
node.js + express + docker + mysql + jwt 實現用戶管理restful api
為了充分發揮RAG的潛力,使LLM的響應能夠切實地建立在可靠數據基礎之上,我們需要超越簡單的索引、檢索、增強和生成的實現方式。要實現這一目標,首先需要建立有效的性能度量標準。RAG評估為建立系統性能基準提供了重要依據,進而為后續的優化提供了方向。
構建RAG概念驗證(PoC)管道的復雜度相對較低。借助LangChain和LlamaIndex等工具,這一過程已經變得相對簡單。通過簡短的訓練和有限樣本的驗證即可實現初步功能。但是為了提高系統的魯棒性,在真實反映生產環境用例的數據集上進行全面測試至關重要。值得注意的是RAG管道本身也可能產生幻覺。從宏觀角度來看,RAG系統存在三個主要的失效點:
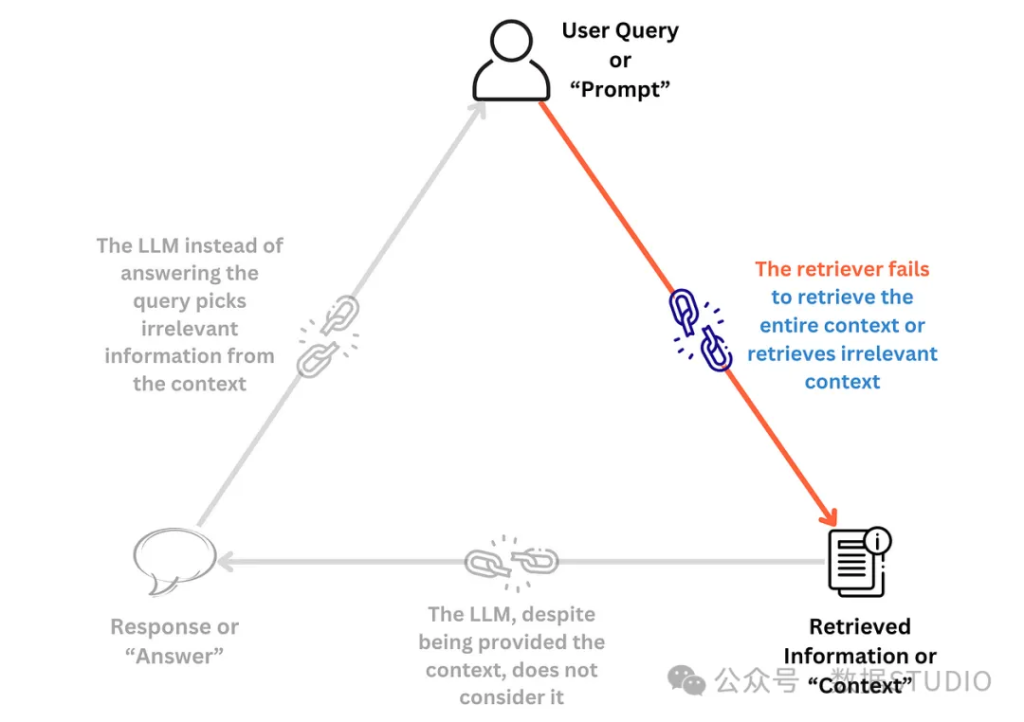
本文將重點討論幾個專注于評估第一個失效點的指標 —— “檢索器未能檢索到完整或相關上下文”。換言之這些指標旨在評估檢索器的質量。
用于評估RAG系統的指標可以大致分為三類:
RAG的檢索組件可以獨立評估確定檢索器滿足用戶查詢的能力。我們將詳細介紹七個廣泛應用于RAG、搜索引擎、推薦系統等信息檢索任務的重要指標。
注:在RAG中,知識庫是一個核心概念。它是一個非參數記憶存儲,用于存儲RAG系統將處理的所有文檔。
準確率在信息檢索領域通常定義為正確預測(包括真陽性和真陰性)占總樣本的比例。這一概念源自監督學習中的分類問題,但在檢索和RAG語境下有其特定解釋:準確率檢索到的相關文檔數未檢索到的不相關文檔數知識庫中總文檔數
盡管準確率是一個直觀的指標,但它并不是評估檢索系統的最佳選擇。在大型知識庫中,對于任何給定查詢大多數文檔通常都是不相關的,這可能導致準確率呈現誤導性的高值。此外該指標并不考慮檢索結果的排序質量。
精確率聚焦于檢索結果的質量,衡量檢索到的文檔中與用戶查詢相關的比例。它回答了這樣一個問題:在所有被檢索到的文檔中,有多少是真正相關的?
精確率檢索到的相關文檔數檢索到的總文檔數
高精確率表明檢索器能夠有效地識別和提取相關文檔。
注:精確率在分類任務中也是一個常用指標,定義為模型預測為正例的樣本中實際為正例的比例,即真陽性 /(真陽性 + 假陽性)。
Precision@k是精確率的一個變體,它僅考慮檢索結果中排名前k的文檔。這一指標在RAG系統中尤為重要,因為通常只有排名靠前的結果會被用于增強。例如如果RAG系統僅使用前5個文檔進行增強,那么Precision@5就成為一個關鍵指標。
例如,Precision@5為0.8(或4/5)意味著在前5個檢索結果中,有4個是相關的。
Precision@k在比較不同系統的檢索性能時特別有用,尤其是當系統間檢索的總文檔數可能不同時。但是它的局限性在于k值的選擇可能帶有主觀性,且該指標不考慮k之外的結果。
召回率評估檢索系統的覆蓋范圍,衡量從知識庫中所有相關文檔中成功檢索到的比例。它回答了這樣一個問題:在所有相關文檔中,實際檢索到了多少?
與精確率不同召回率的計算需要預先知道知識庫中相關文檔的總數。在大規模系統中這可能是一個挑戰。召回率同樣不考慮檢索文檔的排序。理論上檢索所有文檔可以獲得完美的召回率,但這顯然不符合實際需求。
類似于Precision@k,Recall@k考慮了前k個檢索結果中的相關文檔比例:
Recall@k = 前k個結果中相關文檔的數量 / 知識庫中相關文檔總數
召回率和精確率的不同場景
F1分數是精確率和召回率的調和平均值,提供了一個平衡檢索器質量和覆蓋范圍的單一指標。
F1分數的特點是當精確率或召回率任一指標較低時,分數會受到顯著影響。只有當兩個指標都較高時,F1分數才會較高。這種特性使得F1分數不會被單一指標的高值所誤導。
分數平衡了精確率和召回率。中等水平的精確率和召回率可能獲得比一個指標很高而另一個很低時更高的F1分數。
F1分數提供了一個綜合度量,便于比較不同系統的整體性能。但是它不考慮檢索結果的排序,且默認給予精確率和召回率相同的權重,這在某些應用場景中可能不夠理想。
重要說明:
文檔相關性判定:大多數討論的指標都涉及”相關”文檔的概念。確定文檔相關性的最直接方法是通過人工評估。通常由領域專家審查文檔并判定其相關性。為減少個人偏見,這種評估往往由專家小組而非個人完成。但是從規模和成本的角度考慮,人工評估存在局限性。因此任何能可靠建立相關性的數據都變得極為寶貴。在這一背景下,基準事實(Ground Truth)指的是已知真實或正確的信息。在RAG和生成式AI領域,基準事實通常表現為一組預先準備的提示-上下文-響應或問題-上下文-響應示例,類似于監督學習中的標記數據。為知識庫創建的基準事實數據可用于RAG系統的評估和優化。
前面討論的四個指標主要關注檢索的整體效果,而不考慮結果的排序。接下來介紹的三個指標則進一步考慮了檢索結果的排序質量,為評估提供了更深入的視角。
平均倒數排名(MRR)是一個專門用于評估相關文檔排名的指標。它計算的是一組查詢中,每個查詢的第一個相關文檔的排名倒數的平均值。其數學表達式如下:
其中,N為查詢總數,rank(i)為第i個查詢中第一個相關文檔的排名
MRR特別適用于評估系統快速找到相關文檔的能力,因為它考慮了結果的排序。但是由于MRR只關注第一個相關結果,在需要多個相關結果的場景中,其應用可能受到限制。
MRR考慮了排名,但僅關注第一個相關文檔
平均精確率均值(MAP)是一個綜合性指標,它結合了不同截斷級別(k值)的精確率和召回率。MAP首先計算每個查詢的平均精確率,然后取所有查詢的平均值。其計算過程如下:
其中,R(i)為查詢i的相關文檔總數,Precision@k為前k個結果中的精確率,rel(k)為第k個文檔的相關性(0或1)
其中,N為查詢總數
MAP提供了一個在不同召回率水平上的綜合質量度量。當結果的排序質量很重要時,MAP是一個非常有效的指標。但是其計算過程相對復雜。
MAP考慮了所有檢索到的文檔,并對更好的排序給予更高的分數
歸一化折損累積增益(nDCG)是一個更為精細的排序質量評估指標。它不僅考慮了相關文檔的位置,還為較早出現的相關文檔分配更高的權重。nDCG特別適用于文檔具有不同程度相關性的場景。
計算nDCG涉及以下步驟:
其中,rel(i)為第i個文檔的相關性分數
nDCG考慮了文檔的相關性程度,并對不正確的排序進行懲罰
nDCG是一個計算較為復雜的指標。它要求為每個文檔分配相關性分數,這可能引入一定的主觀性。折損因子的選擇也會顯著影響最終結果。盡管如此nDCG能夠有效地處理文檔間不同程度的相關性,并給予排名較高的項目更多權重,使其成為評估高級檢索系統的有力工具。
檢索系統不僅在RAG中發揮關鍵作用,還廣泛應用于網絡和企業搜索引擎、電子商務產品搜索、個性化推薦、社交媒體廣告投放、檔案管理系統、數據庫查詢優化、智能虛擬助手等多個領域。上述檢索指標為評估和改進這些系統的性能提供了重要依據,有助于更好地滿足用戶需求。
本文詳細介紹了七個核心檢索指標,從簡單的準確率到復雜的nDCG,每個指標都有其特定的應用場景和優缺點。在實際應用中,選擇合適的指標組合對于全面評估和優化RAG系統至關重要。
文章轉自微信公眾號@數據STUDIO
node.js + express + docker + mysql + jwt 實現用戶管理restful api
nodejs + mongodb 編寫 restful 風格博客 api
表格插件wpDataTables-將 WordPress 表與 Google Sheets API 連接
手把手教你用Python和Flask創建REST API
使用 Django 和 Django REST 框架構建 RESTful API:實現 CRUD 操作
ASP.NET Web API快速入門介紹

2024年在線市場平臺的11大最佳支付解決方案

完整指南:如何在應用程序中集成和使用ChatGPT API

選擇AI API的指南:ChatGPT、Gemini或Claude,哪一個最適合你?