 艾之:有評論區在問,如果要達到類似的效果,可能用強模型微調一下就可以了,做垂類大模型的意義是什么?再順著延伸下,這幾層里面,哪幾層做完之后會加高你們產品的門檻?不同的門檻對于團隊的要求會是什么樣子?
艾之:有評論區在問,如果要達到類似的效果,可能用強模型微調一下就可以了,做垂類大模型的意義是什么?再順著延伸下,這幾層里面,哪幾層做完之后會加高你們產品的門檻?不同的門檻對于團隊的要求會是什么樣子?從 23 年 3 月份到現在,你們的產品正式上線也有半年時間,在這段時間里,你們產品經歷了哪些大的改版?我覺得對于創業團隊來講,一個產品的轉向都是非常正常的事情,你們是怎樣一個路徑?
姜昱辰:我們一開始做的是純 ToC 的互動內容平臺,平臺上所有內容都是 AI 生成的,當時也發布了一個小程序。后來慢慢意識到內容是整個產品中最重要的部分,不管做什么,還是需要人+AI 輔助生成高質量內容的這樣一個抓手。出于這樣的目的,我們做了蛙蛙寫作,把用戶吸引過來做一些創作。因為之前的版本是一個互動平臺,第一個版本是一個多線內容的編輯器,我們把一鍵生成的接口開放給創作者,希望在 AI 一鍵生成基礎上他們做一些審核修改的工作。
這個功能做得久了就會發現,我們好像真的能幫到大家寫東西,跟一些用戶接觸交流之后,我們在去年年底的時候做了兩個比較重要的變動,一個是把多線的部分隱藏變成單線,讓整個創作邏輯變得更加清晰。第二件事是我們強化了編輯器的屬性,一款好的 AI 輔助寫作工具首先得是一款好的編輯器。所以我們把整個流程都變成了可編輯、可控的,跟 AI 可融合的。編輯器在長文本的創作上是非常非常重要的,在幾百萬字的情況下,非常需要人在中間有交互編輯的過程。這兩個改動做了以后,就是現在蛙蛙寫作所呈現出來的形態了。
艾之:你們在去拆解作者創作過程的時候,是原本已經很了解里面的流程了,還是說其實也要去找一些用戶,去做非常深入的調研,觀察他們怎么去用這個產品?
姜昱辰:我們有很多的研究,因為我不是專業寫小說的,所以一開始跟大量的編劇以及行業里的人去溝通他們都是怎么樣去創作的,怎么去寫稿子的。蠻有意思的一點是,跟很多很厲害的作者去聊的時候,他們講不出所以然來,但跟一些編輯去聊,他們可以把很多邏輯講得很清楚。因為編輯們每天都在審稿,看得多了對寫作這個東西本身更有分析。還有一個點,比較好的作者的創作習慣挺一致的,一般情況下都會寫大綱和人物小傳,把整個東西都構思好后再去做細節創作。我們把這個流程也加在了蛙蛙寫作里面。
艾之:你們作為一個創業公司,大家一定會天然想到說你們的資源是有限的,沒有辦法無限制地投入到技術的研發上面,隨心所欲地去做研究。見投資人或者說跟同行交流的時候,大家一定會問到,你做的這個事會不會有一天就被大模型吞沒了?
姜昱辰:對,幾乎天天會被問到,你會不會擋在 OpenAI 的路上,要做什么樣的技術創新才不會被淘汰。
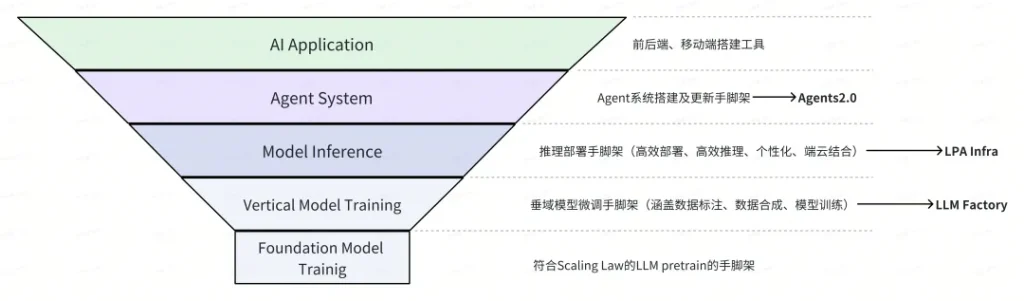
我覺得有兩個維度,一個是會不會被大模型吞噬,另一個是會不會被大模型公司吞噬。之前我提到一個金字塔結構,或者說是 AI/LLM 的技術棧,最底層最核心的是基礎模型。基礎模型需要不斷 scaling,以前我們認為 1B 的模型已經很大了,到了 2023 年,我們覺得 34B 的模型也不算很大了,參數也還在不斷被擴大。這一層需要解決的技術問題是如何做到穩定地 scaling,以及在資源和模型表現之間找到好的平衡策略。
第二層是垂域模型。在基礎模型之上,我們進行持續地預訓練,開發了專用于垂域模型訓練的「腳手架」——LLM factory,Weaver 就是利用這個訓練出來的。垂域模型訓練可以幫助適應特定領域的語料和知識,讓模型的輸出更專業。
第三層是模型推理。這一層在工業界相對少見,但在學術界研究較多。大模型本身是個概率分布,如何通過解碼算法將這些概率分布轉化為具體的輸出句子。我們波形在這一層有較深入的研究,包括 score-based decoding 的技術(下圖中的 LPA Infra)。
第四層是 Agent。Agent 需要具備 Memory、Reflection、對環境的認知能力,以及自我進化的能力。這些能力使得 Agent 能夠根據環境進行反應和自我調整。我們在這一層進行了投入,并研發了端到端的可持續自進化的 Agent 系統 (self-evolving agent,下圖中的 Agents 2.0)。
最外層是 AI 應用。這一層包含各種應用場景,比如項目化寫作、AI 客服、AI 導購等。大概是這樣一個分層。
艾之:有評論區在問,如果要達到類似的效果,可能用強模型微調一下就可以了,做垂類大模型的意義是什么?再順著延伸下,這幾層里面,哪幾層做完之后會加高你們產品的門檻?不同的門檻對于團隊的要求會是什么樣子?
姜昱辰:我覺得這是一個非常典型的問題,網友的 mindset 和一些我們接觸到的 B 端客戶蠻不同的,他們比較傾向于訓練一個所謂的「垂域大模型」。B 端客戶通常會問:訓練一個垂域模型需要多少錢?需要多少數據?但在問這個問題之前,首先應該問自己:我是否真的需要訓練一個垂域模型?其實 80% 的場景中,并不需要訓練垂域模型。
我做過一個紅藍榜:紅榜是需要訓練垂域模型的案例,藍榜是不需要訓練垂域模型的案例。紅榜的例子包括對文風或語義有特殊要求的場景,比如寫小說或標書,這些場景對風格有特別的要求,必須通過訓練模型來達到效果。而在一些重邏輯推理的場景,比如 agent 處理信用證審單或解決數學題等,訓練垂域模型可能并不必要,更多的是依靠模型的記憶能力和理解能力。
網友的問題是,幾千條數據進行微調不就可以了,為什么還要垂域模型?其實微調本身也是在訓練垂域模型。垂域大模型的定義非常寬廣,可以涵蓋各種成本的訓練場景。比如幾千條數據就能達到好的效果,這可以算是一種低成本的垂域模型訓練。有些場景可能需要更復雜的訓練,在前面進行持續預訓練,這可能需要更高的成本。
使用 RAG 來解決問題也有門檻。模型需要理解 RAG,embedding 模型的效果也很重要,Similarity metric 的好壞對結果有很大影響。所以每一層都有其技術難點和關鍵點,把這些問題解決好都會有價值。
對一個企業來說,單獨解決某一層的問題很難。無論是 C 端還是 B 端客戶,最終需要的是一個 all-in-one 的解決方案。客戶不會只因為你解決了某一個技術難題而選擇你,而是因為你能幫助他們實現整體的目標,對蛙蛙來說就是幫創作者寫出更好的小說。因此,一個 AI 公司需要在每一層都有所能力,盡管在不同地方可能有自己的擅長點,但在每一層上都不能缺席。
艾之:我覺得你的這個回答也解釋了,或者說佐證了為什么大家覺得 2024 年應該有非常多的應用出來,但是其實沒有。因為中間還是有非常多的斷點,層與層之間__沒有完全連接上。__
你們剛發布的 LPA,它在剛才講的分層結構中是怎么樣分布的?
姜昱辰:其實就像前面說的,「AI 公司在每一層都不能缺席」,LPA 是一個端到端的在每一層都有所融合的技術棧。具體而言,我們有幾個核心的構建模塊。在 memory 方面,我們有比較深厚的積累,很多人可能聽說過我們的 RecurrentGPT。這種長短期記憶機制在 LPA 中都有繼承。
![]() LPA 的核心是一個叫 AI Persona 的系統。這個系統中的 memory 模塊繼承了 RecurrentGPT 的一些設計思路。另外AI Persona 中還包括 Personality、Pattern 和 Preference。Preference 數據包括用戶在多個選項中的選擇,AI Persona 會記住并反映在后續的互動中。構建 Preference 數據是 LPA 的一個核心部分。
LPA 的核心是一個叫 AI Persona 的系統。這個系統中的 memory 模塊繼承了 RecurrentGPT 的一些設計思路。另外AI Persona 中還包括 Personality、Pattern 和 Preference。Preference 數據包括用戶在多個選項中的選擇,AI Persona 會記住并反映在后續的互動中。構建 Preference 數據是 LPA 的一個核心部分。
另一個核心是如何在保護隱私的情況下,充分利用這些 Preference 數據。我們不能將用戶數據用于訓練大模型,而只是在本地化個性化交流中使用。這意味著 AI Persona 在本地保存用戶信息,大模型在不訪問這些私有數據的情況下,能夠生成個性化的輸出。
第三點是自適應。作為用戶的 copilot,AI 需要能夠隨著用戶的交互數據不斷學習和成長。傳統的模型更新方式,包括 Weaver 1.0 和 2.0 都是集中的大規模更新。我們希望實現的是持續更新。在這方面也下了很多功夫,最近還開源了我們的 self-evolving agent *框架。這個框架現在在 GitHub 上可用,增加了自適應化功能,讓整個 Agent 能夠從用戶行為的軌跡中學習并更新。
*https://arxiv.org/abs/2406.18532
艾之:你剛提到 RecurrentGPT,這個東西對波形來說也是挺關鍵的。能不能講一下 RecurrentGPT 那篇論文中核心的一些東西?
姜昱辰:一句話來說,首先它解決什么痛點?大模型的上下文長度有限,它做不到無限式的輸出,不像以前的 RNN,它可以無限輸出。我們的解決方案主要面向的是長文本和無限輸出的場景。
用人話說就是我們設計了一套長短期動態記憶機制,讓模型端到端地學會怎么遺忘、怎么記東西,怎么從短期記憶中提取記憶。這種機制解決了大模型在生成長文本后半部分內容時不連貫的問題。
艾之:所以當大模型生成很長的內容時,如果它后面開始漫無邊際地胡說八道,其實是它忘了該記住的東西。
姜昱辰:對對對,還有另一個問題。就是大模型的可控性差。我們通過幾個層面解決了這個問題:
在微調階段,我們進行了一個名為 InstructCTG(Instruction based Control Text Generation)*的微調工作,這項技術提高了模型對指令的遵從性。
Agent 框架方面,我們是第一個使用 SOP 控制 Agent 的框架。通過 SOP,我們在 Agent 層面實現了更好的控制。
解碼階段,我們開發了一個叫做 Score-based Decoding 的技術,在解碼時加強了模型的可控性。這項技術與我們的 LPA 緊密結合,使模型在生成文本時能夠更好地遵循指令。
*https://arxiv.org/abs/2304.14293
艾之:那你覺得 Agent 到應用這一層,它和產品之間的界限清晰嗎?還是說可能未來 Agent 就是 AI native 產品最核心的東西?
姜昱辰:非常好的問題。我們現在有個崗位叫 AI 產品經理,但它和傳統的互聯網產品經理有什么區別?我們對這個崗位有什么期望?我有一些自己的體會。
首先,一個好的 AI 產品經理必須懂 Agent。這是一個非常必要的條件。舉個簡單的例子,在蛙蛙的產品設計中,如何設計用戶體驗和用戶交互?一方面需要考慮用戶使用的流暢性,另一方面也要考慮現有技術的局限。雖然蛙蛙在一致性上表現優于 GPT,但它仍然有限制,這時候產品的交互設計就可以彌補其中 80% 的 GAP。
我們最近在討論能否將蛙蛙的 memory 變成可見的、用戶可以操作的部分。通過開放自然語言接口,讓用戶可以直接查看和修改模型的 memory。如果用戶在使用過程中發現某些 memory 需要去掉,他們就可以直接刪除。這種設計思路是傳統產品經理想不到的,純算法的技術人員如果沒有產品設計的敏感度,也不會去考慮這個問題。
所以我覺得AI 時代對產品經理,以及應用團隊提出了更高的要求。他們不僅需要具備傳統的產品設計和用戶體驗設計能力,還需要了解和理解 AI 技術的特點和局限,找到技術與用戶需求之間的最佳平衡點。
 艾之:對,所以產品經理不能僅僅是懂模型,還要需要去理解垂域模型和基礎模型之間相互演進的關系,怎么把一個好的大模型微調成你想要的,怎么把推理/Agent 的東西做得更好。
艾之:對,所以產品經理不能僅僅是懂模型,還要需要去理解垂域模型和基礎模型之間相互演進的關系,怎么把一個好的大模型微調成你想要的,怎么把推理/Agent 的東西做得更好。
姜昱辰:評論區的網友講得特別好,Agent 是一種交互方式,我特別認同。我覺得 Agent 的設計能力在這個時代不應該是做模型的人掌握的能力,而是產品經理應該掌握的能力。
艾之:所以我們在討論 AI 產品的用戶體驗的時候,核心在討論的是 Agent 的機制問題。
姜昱辰:對,我覺得雙向思考是必要的。一方面,你仍然需要關注用戶,這跟互聯網時代沒有任何區別。你需要為市場和用戶設計產品。另一方面,你還必須考慮在當前技術邊界內,如何進行設計來達到最佳效果。
艾之:我比較好奇在用戶開始接觸你們產品的時候,這個時候模型對用戶是完全不了解的,沒有辦法做一些個性化的自適應工作,你們是怎么解決這個問題的?怎么讓數據飛輪轉起來的?
姜昱辰:個性化并不是我們在上線第一天就做的事情,而是一個逐步推進的過程。我們先進行了大量的長期工作,使產品達到了一個能用的 80 分水平,然后才上線。這項個性化技術是在上線半年后推出的,因為我們需要先收集用戶的數據反饋并進行有效的互動,在保障用戶隱私的情況下,使個性化變得可行。
在產品上線的第一天,我們就非常注重數據的收集和結構化構建。我們從一開始就認為需要 agent 和保障隱私的個性化,因此進行了充分的數據準備工作。所以我們先發布一個差不多能用的版本,打磨出一套數據 feed 機制,結構化地來收集數據。再等它轉到一定程度,積累了足夠多的用戶數據和反饋后,我們再利用這些數據進行個性化訓練。
艾之:所以你是先用 RecurrentGPT 結合模型,先把用戶的數據搞到,給用戶建模,之后再上 LPA,把整個事情轉起來。
評論區有人說,在基礎模型之上去額外建設很多工程化的工作,包括設計一些算法機制嘗試去彌補大模型本身。這種堆砌工作是不是走偏了?將低代碼平臺無法堆起來的問題沿用到了 AI 時代,你怎么看?
姜昱辰:我覺得講得特別好,非常同意。這里有兩個點:
首先,不應該把我們的工作僅僅看作是在彌補大模型的不足。如果只是彌補不足,我們可能會被 OpenAI 干掉。更準確地說,我們是在補充大模型的功能,在 scaling 方面的提升會提供更長期的價值。
另一個是定制化的問題。低代碼平臺常常被認為不夠實用,主要是因為它們在定制化和通用性之間難以找到平衡。每個場景的優化需要獨特的設計,這往往會導致解決方案只能達到一個局部最優,而難以廣泛適用。
在 AI 時代,只是做「手搓 Agent」的工作,是換湯不換藥,本質上沒有任何變化。有一個很有前景的技術,就是通過自然語言交互來設計 Agent 流程。將整個過程預置化,這樣不僅提高了通用性,還大大簡化了用戶的操作。所以這是我認為可能破局的點。
艾__之:__明白,就是你先把里面的那個機制先做好了之后,再不斷地優化和簡化用戶和產品的交互界面以及模型之間的距離。
姜昱辰:對,我覺得 AI 時代最需要關心的一個事情就是人和 AI 的交互。Human AI interaction。這個我覺得是非常非常重要的一個設計。怎么設計一個好的交互,讓人在特別舒服又省力的情況下把 AI 生成的一些錯誤東西給糾正了,然后很輕松地做可控式搭建,應該是這樣的一個工作。
艾之:長文本理解和長文本生成,這兩件事情的技術難度到底如何?是不是說理解就比生成更容易,還是更難?
姜昱辰:我覺得這兩個的技術棧都挺難的。
長文本理解涉及到邏輯能力和對信息的處理能力。理解和解析信息需要較強的邏輯推理能力,這是從能力角度出發的要求。從技術角度來說我們面臨的挑戰是如何在有限的上下文窗口內增強模型的理解能力,這可能就會涉及到 scaling。
生成不一樣,它需要維持自一致性和邏輯連貫性。生成模型要能夠在長時間(甚至是 life-long)內保持邏輯一致性,這在處理大量文本生成時尤為重要。從技術方案來說,我們現在用的是 recurrent decoding 方案,關注如何在上下文窗口大小不變的情況下讓模型有更好的記憶更新機制的問題。Recurrent decoding 技術的一個主要限制是它對大量文本的處理速度較慢,因為它需要逐輪生成和處理內容,可能不適合需要「量子速讀」的場景。
艾之:就長文本生成來說,輸出文字長度到什么程度就能達到專業水平?
姜__昱辰__:體感來說 50 萬字以上你就會感受到一個比較明顯的差距了,這時候如果沒有用專門一套長文本生成的方案,一般模型帶不動這么長的 context。
艾之:所以說,如果有一個模型可以一直服務于我們做個性化的事情,在接下來的所有時間里都保持一致,這是非常有價值的一套框架。
我自己試你們產品的時候,能感覺到蛙蛙生成的文風相比 GPT-4 更有人味,機器的味道沒有那么重。你們是怎么做到比它生成得快還好的?
 姜昱辰:我們有幾個維度的調整。
姜昱辰:我們有幾個維度的調整。
第一我們在文風上做了一些調整。尤其是在從通用領域進入垂直領域的時候。對于輸出要求很高的場景,文本上的調整尤為關鍵。這里并不是說數據越多越好,而是需要有高質量的數據。所以如何精選高質量的數據成了我們非常重要的工作。
我們當時手上有 5T 的數據量,最后其實只選出了 50GB 的數據。這是一個非常嚴格的篩選過程。我們意識到并不是越多越好,而是需要一個「黃金配比」,比如多少中文、多少英文、多少小語種。這種好的配比是至關重要的,因為即使你要訓練一個中文模型,也并不意味著你只需要中文的語料。跨語言的轉換能力(cross-lingual transferability)也非常重要。
第二,在 SFT(Supervised Fine-Tuning)階段,我們做了一個叫做「指令的反向翻譯」(instruction back translation)的技術。因為我們主要是一個輸出場景,輸出質量非常重要,必須是「杰作」。所以我們拿過來一批好作品,標注出它們的特征和模式,這個任務比正向標注簡單得多,高效得多。
第三,在 RLHF(Reinforcement Learning from Human Feedback)階段,我們做了一個技術叫 Constitutional DPO。這個技術的核心是將模型的任務分解,每個模型只需負責一個方向,比如人物的一致性,內容的趣味性等等。這樣做的好處是任務更輕松,大大提升了標注員之間的一致性(IAA),這反過來又幫助了模型的訓練。
艾之:可不可以理解成,把一個比較抽象的形容詞,比如說「好」或者「不好」先進行量化拆解。我們先要把抽象的概念轉化為一些具體的、可測量的指標。然后在每一個量化的拆解部分,我們再將其對應到一個具體的模型。這個模型的任務非常明確、非常聚焦,只負責處理特定的指標,不涉及其他方面的內容。接下來,我們會分析在這幾個象限中,什么樣的作品表現得最好,以及它們在這些象限中具體表現如何。如果一個作品在這些象限中都表現得很好,那么我們就認為它是寫得好的。
姜昱辰:對,這也是一個很好的把行業 know-how 用起來的例子。我們請了大量專業的作者過來確定標準,把行業 know-how 給沉淀下來。
艾之:你們在做的就是把一些手藝活的東西,盡可能地用理性去拆解它。有評論區提問,蛙蛙會用大量的生成數據嗎?
姜昱辰:會,這其實就是我前面提到的,instruction back translation 和 Constitutional DPO 本質上就是一種數據合成的范式。我們應用了大量自動化的數據標注流程。雖然在系統中確實有一部分數據是由人類標注的,但這些人類標注的數據更多是作為一個參考數據集,用來訓練數據標注模型。所以整個過程是一個相當長的 pipeline,其中包含了非常多由 AI 自己生成的數據。
艾之:我們剛才提到,從模型到產品大致分了幾個層次。你們基本上是從模型層以上逐步構建的。那么你覺得,現在的創業團隊是否也需要從這個層次開始?當時波形創業時,你們是如何判斷這是一個合適的時間點?
因為回顧過去十年,不同的產業階段確實適合不同類型的創業者下場創業。如果個人與時代無法同頻共振,很多時候是無法推出好的產品,也無法培養出優秀的公司。所以節奏感非常重要,你對此有什么個人的思考?
姜昱辰:我覺得是這樣的,現在的 AI 是一個涉及未來 10 到 20 年,甚至 30 年的大事件,這一點大家應該都有共識。在這樣一個背景下,我們剛剛經歷的過去一到兩年的時間,其實是非常早期的階段。所以 AI 確實是一個改變時代的技術,但這不是一蹴而就的。你看從上世紀 40 年代第一臺計算機 ENIAC 的發布到真正 PC 普及和互聯網興起,中間還隔了很長時間。
所以我的建議是,如果你身處這個行業,需要有耐心,你需要做出一些貢獻。回到前面的問題——什么樣的人適合進來?我覺得,至少你要對技術棧有所貢獻,現在進來才是合適的。因為當前的技術棧還不完整,所有人都需要在造輪子上做一些事情。如果你對造輪子有熱情并且有相關的技術經驗,那么現在下場是非常好的時機。現在是開荒階段,你可以獲得非常寶貴的經驗,而且你可以在市場和場景中找到很多好的技術棧機會,處于一個非常有利的位置。
總而言之我覺得這件事沒有明確標準。沒有特別明確的答案可以說什么樣性格的人適合現在加入,什么背景的人不適合。這是非常個人化的選擇,關鍵在于你是否擁抱這個時代。如果你愿意,那就歡迎你的加入。
艾之:波形在產品開發和市場反饋上已經達成了一個小的 TPF 閉環,雖然還未完全成熟。但我相信,在這一年半的創業過程中,你一定也在不斷思考 TPF 和 PMF 的問題。作為一個從吭哧吭哧寫論文的研究人員,轉變為吭哧吭哧跑市場、跑用戶的創業者,你感覺找到一些手感了嗎?
姜昱辰:確實,我的思考也在變得越來越深刻。早期更多關注的是 TMF,認為某個場景可以通過技術來解決問題,或者覺得某個痛點很重要,就投入時間和資源去攻克技術難題。但現在更多的是看 TPF,如何在產品交互設計上優化,讓技術與產品結合得更好,實現質的提升。這是我在創業過程中學到的一大課題,確實有了更深刻的認知。
艾之:那你當時選擇的時候是如何評估這個市場和場景的?
姜昱辰:我們當時確認這是一個高頻需求市場,并且在現有技術范圍內能夠實現 TPF。多個因素疊加后,我認為這是一個值得進入的市場。另外就是要熱愛,不熱愛整個過程會非常痛苦。
艾之:你們有走過什么彎路嗎?
姜昱辰:肯定有。最初嘗試的方向偏向于純 AI 驅動的解決方案,但發現產品邊界在那個階段無法找到 TPF。然后我們就調整了策略,轉向更用戶導向的方案,在這一過程中找到了某種程度的 PMF。接下來的一段時間里,我們可能會回過頭重新評估之前的方向,看看是否達到了 TPF 的臨界點。如果達到了,我們一定會繼續推進。
艾之:你覺得現在蛙蛙產品算成了嗎?到什么節點,取得什么里程碑的時候你覺得可以跟大家很自信地說,我們做成了這件事?
姜__昱辰__:「成了」這個詞確實很微妙。我感覺從 PMF 的角度來說,蛙蛙確實已經算是跑通了 PMF,ROI 也達到了正收益,我們在為用戶創造價值。從用戶留存和日均使用時長來看,這確實達到了一個閉環產品的水準。
但從另一個角度來說,蛙蛙作為一個工具型產品,不管是從我們自身的角度,還是從整個 AI 發展的角度來看,它其實還是一個中間態的產品。就像我前面提到的,我們最初想做的是一個互動內容平臺,而蛙蛙寫作的核心使命其實是為我們積累數據和沉淀技術,以便我們未來能夠做出更高級、更有趣的產品形態。
艾之:你會怎么看波形?一方面你們在推進技術的發展,另一方面也在不斷嘗試做一些產品,持續觀察市場需求。我看你們基本上以半年為一個小周期,較大幅度地迭代產品和開拓場景。到底哪一條線才是你們真正的主軸線呢?
姜昱辰:用一句話定義,我覺得我們是一個持續尋找 TPF 的組織。在產品跟技術上就會相輔相成,互相去迭代,去成就。半年對于創業公司來說節奏上也是比較好的一個迭代周期。
AI寫作如何工作?
使用AI寫作有什么風險或挑戰?
使用AI寫作可能面臨版權問題、內容質量不一致、缺乏原創性和深度、以及可能的倫理問題,如誤導讀者或傳播不準確信息。
如何提高AI寫作的質量?
提高AI寫作質量可以通過使用更先進的算法、提供更高質量的訓練數據、不斷優化和調整模型參數、以及結合人類編輯的反饋來進行。
AI寫作是否能夠理解語境和文化差異?
AI寫作系統正在不斷進步,能夠更好地理解和適應不同的語境和文化差異。然而,這通常取決于訓練數據的多樣性和模型的復雜性。目前,AI可能在理解某些細微的文化差異方面仍有局限。
如何評估AI寫作生成的內容質量?
評估AI寫作內容的質量通常涉及多個方面,包括語法正確性、內容的相關性、邏輯連貫性、以及是否符合目標受眾的需求。此外,還可以通過用戶反饋和專業編輯的評審來進一步評估和改進。
AI寫作是否會取代傳統的寫作工具?
AI寫作不太可能完全取代傳統的寫作工具,如文字處理軟件。相反,它更可能成為這些工具的補充,提供輔助功能,如自動校對、內容建議和風格指導。
原文轉自 微信公眾號@Founder Park