 – 視頻分類 與圖像分類不同的是,分類的對(duì)象不再是靜止的圖像,而是一個(gè)由多幀圖像構(gòu)成的、包含語音數(shù)據(jù)、包含運(yùn)動(dòng)信息等的視頻對(duì)象,因此理解視頻需要獲得更多的上下文信息,不僅要理解每幀圖像是什么、包含什么,還需要結(jié)合不同幀,知道上下文的關(guān)聯(lián)信息。
– 視頻分類 與圖像分類不同的是,分類的對(duì)象不再是靜止的圖像,而是一個(gè)由多幀圖像構(gòu)成的、包含語音數(shù)據(jù)、包含運(yùn)動(dòng)信息等的視頻對(duì)象,因此理解視頻需要獲得更多的上下文信息,不僅要理解每幀圖像是什么、包含什么,還需要結(jié)合不同幀,知道上下文的關(guān)聯(lián)信息。循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)與 CNN 類似,但可以處理一系列圖像,以找到它們之間的聯(lián)系。
就像人類辨別遠(yuǎn)距離的圖像一樣,CNN 首先辨別硬邊緣和簡單的形狀,然后一邊運(yùn)行預(yù)測迭代,一邊填充信息。CNN 用來分析單張圖像,而 RNN 可以分析視頻并了解圖像之間的關(guān)系。
在體育、汽車、農(nóng)業(yè)、零售、銀行、施工和保險(xiǎn)等行業(yè),計(jì)算機(jī) 視覺應(yīng)用非常廣泛。得益于目前機(jī)器用于識(shí)別物體的圖像處理器 – 卷積神經(jīng)網(wǎng)絡(luò) (CNN),各種由 AI 驅(qū)動(dòng)的機(jī)器紛紛開始采用仿人眼技術(shù)來獲得更多助力。CNN 已成為當(dāng)今自動(dòng)駕駛汽車、石油勘探和聚變能源研究領(lǐng)域的“眼睛”。它們還有助于在醫(yī)學(xué)成像領(lǐng)域快速發(fā)現(xiàn)疾病并挽救生命。
數(shù)十年來,傳統(tǒng)的計(jì)算機(jī) 視覺和圖像處理技術(shù)已經(jīng)應(yīng)用于眾多應(yīng)用和研究工作。然而,現(xiàn)代 AI 技術(shù)采用人工神經(jīng)網(wǎng)絡(luò),能夠?qū)崿F(xiàn)更高的性能準(zhǔn)確性;高性能計(jì)算依托 GPU 取得長足進(jìn)步,實(shí)現(xiàn)超人的準(zhǔn)確性,從而在運(yùn)輸、零售、制造、醫(yī)療健康和金融服務(wù)等行業(yè)廣泛應(yīng)用。
在將圖像和視頻分類為精細(xì)離散的類別和分類方面,如同醫(yī)學(xué)計(jì)算機(jī)軸向斷層掃描或 CAT 掃描中隨時(shí)間推移而產(chǎn)生的微小變化,傳統(tǒng)或基于 AI 的計(jì)算機(jī) 視覺系統(tǒng)遠(yuǎn)勝于人類。在這個(gè)意義上,計(jì)算機(jī) 視覺將人類有可能完成的任務(wù)自動(dòng)化,但其準(zhǔn)確性和速度要高得多。
當(dāng)前和潛在的應(yīng)用多種多樣,因此計(jì)算機(jī) 視覺技術(shù)和解決方案的增長預(yù)測相當(dāng)驚人,這點(diǎn)不足為奇。一項(xiàng)市場調(diào)研表明,到 2023 年,該市場將以驚人的 47% 的年增長率增長,屆時(shí)將在全球達(dá)到 250 億美元。在整個(gè)計(jì)算機(jī)科學(xué)范疇內(nèi),計(jì)算機(jī) 視覺是熱門、活躍的研發(fā)領(lǐng)域之一。
許多組織沒有資源資助計(jì)算機(jī) 視覺實(shí)驗(yàn)室以及創(chuàng)建深度學(xué)習(xí)模型和神經(jīng)網(wǎng)絡(luò)。 他們可能還缺乏處理海量視覺數(shù)據(jù)所需的算力。 IBM 等公司正在通過提供計(jì)算機(jī) 視覺軟件開發(fā)服務(wù),助他們一臂之力。 這些服務(wù)交付預(yù)先構(gòu)建的學(xué)習(xí)模型,可以從云端獲取,因此還可以緩解對(duì)計(jì)算資源的需求。 用戶通過應(yīng)用程序編程接口 (API) 連接到服務(wù),并使用它們來開發(fā)計(jì)算機(jī) 視覺應(yīng)用程序。
以下示例展示了一些常見的計(jì)算機(jī) 視覺任務(wù):
– 視頻分類 與圖像分類不同的是,分類的對(duì)象不再是靜止的圖像,而是一個(gè)由多幀圖像構(gòu)成的、包含語音數(shù)據(jù)、包含運(yùn)動(dòng)信息等的視頻對(duì)象,因此理解視頻需要獲得更多的上下文信息,不僅要理解每幀圖像是什么、包含什么,還需要結(jié)合不同幀,知道上下文的關(guān)聯(lián)信息。
 – 物體檢測 可以使用圖像分類來識(shí)別一類特定圖像,然后檢測圖像或視頻中出現(xiàn)的這類圖像并制成表格。 例如,檢測裝配線上的損壞,或者識(shí)別需要維護(hù)的機(jī)械裝置。
– 物體檢測 可以使用圖像分類來識(shí)別一類特定圖像,然后檢測圖像或視頻中出現(xiàn)的這類圖像并制成表格。 例如,檢測裝配線上的損壞,或者識(shí)別需要維護(hù)的機(jī)械裝置。
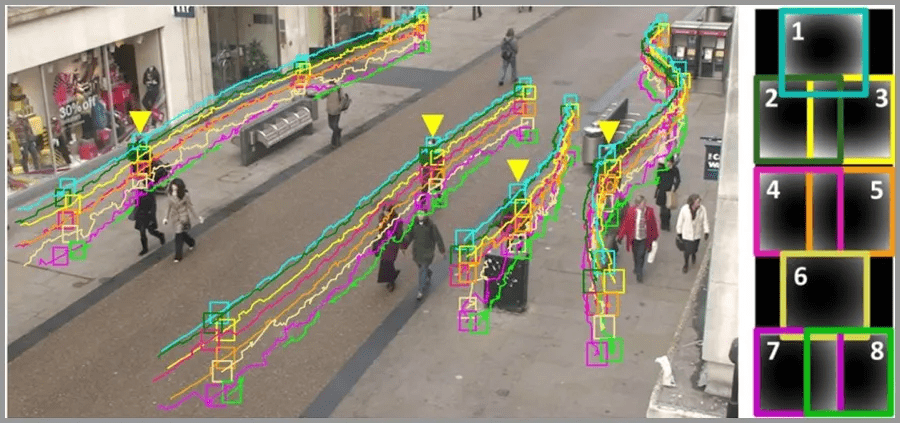
 – 對(duì)象跟蹤會(huì)跟蹤檢測到的對(duì)象。 此任務(wù)通常對(duì)按順序捕獲或在實(shí)時(shí)視頻源中捕獲的圖像執(zhí)行。 例如,自主駕駛汽車不僅需要對(duì)行人、其他車輛、道路基礎(chǔ)設(shè)施等對(duì)象進(jìn)行分類和檢測,還必須能夠在行駛過程中跟蹤它們以避免發(fā)生碰撞并遵守交通規(guī)則。
– 對(duì)象跟蹤會(huì)跟蹤檢測到的對(duì)象。 此任務(wù)通常對(duì)按順序捕獲或在實(shí)時(shí)視頻源中捕獲的圖像執(zhí)行。 例如,自主駕駛汽車不僅需要對(duì)行人、其他車輛、道路基礎(chǔ)設(shè)施等對(duì)象進(jìn)行分類和檢測,還必須能夠在行駛過程中跟蹤它們以避免發(fā)生碰撞并遵守交通規(guī)則。
 – __基于內(nèi)容的圖像檢索__ 利用計(jì)算機(jī) 視覺,根據(jù)圖像內(nèi)容從大型數(shù)據(jù)存儲(chǔ)中瀏覽、搜索和檢索圖像,而不是根據(jù)與圖像關(guān)聯(lián)的元數(shù)據(jù)標(biāo)記。 這個(gè)任務(wù)可以包含自動(dòng)圖像注解,以取代手動(dòng)圖像標(biāo)記。 這些任務(wù)可用于數(shù)字資產(chǎn)管理系統(tǒng),可以提高搜索和檢索的準(zhǔn)確性。
– __基于內(nèi)容的圖像檢索__ 利用計(jì)算機(jī) 視覺,根據(jù)圖像內(nèi)容從大型數(shù)據(jù)存儲(chǔ)中瀏覽、搜索和檢索圖像,而不是根據(jù)與圖像關(guān)聯(lián)的元數(shù)據(jù)標(biāo)記。 這個(gè)任務(wù)可以包含自動(dòng)圖像注解,以取代手動(dòng)圖像標(biāo)記。 這些任務(wù)可用于數(shù)字資產(chǎn)管理系統(tǒng),可以提高搜索和檢索的準(zhǔn)確性。
60 多年來,科學(xué)家和工程師一直在嘗試開發(fā)各種方法,讓機(jī)器能夠看到和理解視覺數(shù)據(jù)。 在 1959 年的第一次實(shí)驗(yàn)中,神經(jīng)生理學(xué)家向一只貓展示一組圖像,試圖喚起貓大腦的反應(yīng)。 他們發(fā)現(xiàn)貓會(huì)先對(duì)硬邊緣或線條做出反應(yīng),從科學(xué)角度來說,這意味著圖像處理從簡單的形狀開始,例如直邊。
大約在同一時(shí)期,第一個(gè)計(jì)算機(jī)圖像掃描技術(shù)成功地開發(fā)出來,使計(jì)算機(jī)能夠?qū)D像數(shù)字化并獲取圖像。 1963 年,計(jì)算機(jī)能夠?qū)⒍S圖像轉(zhuǎn)換為三維形式,標(biāo)志著第二個(gè)里程碑的實(shí)現(xiàn)。 在 20 世紀(jì) 60 年代,人工智能作為一個(gè)學(xué)術(shù)域研究誕生了,同時(shí)也標(biāo)志著人們開始探求依靠人工智能解決人類視覺問題的方法。
1974 年,光學(xué)字符識(shí)別 (OCR) 技術(shù)走向市場,它能夠識(shí)別以任何字體或字型打印的文字,例如各類證件、各類單據(jù)。同樣,智能字符識(shí)別 (ICR) 能夠使用神經(jīng)網(wǎng)絡(luò)識(shí)別手寫文字。此后,OCR 和 ICR 廣泛地運(yùn)用到文件和發(fā)票處理、車牌識(shí)別、移動(dòng)支付、機(jī)器翻譯和其他常見領(lǐng)域。
1982 年,神經(jīng)系統(tǒng)科學(xué)家 David Marr 證實(shí)了視覺分層工作原理,并推出了使機(jī)器能夠檢測邊緣、角落、曲線和類似的基本形狀的算法。 與此同時(shí),計(jì)算機(jī)科學(xué)家 Kunihiko Fukushima 開發(fā)了一個(gè)能夠識(shí)別模式的細(xì)胞網(wǎng)絡(luò)。 這個(gè)網(wǎng)絡(luò)稱為 Neocognitron,它在一個(gè)神經(jīng)網(wǎng)絡(luò)中包含了多個(gè)卷積層。
到 2000 年,物體識(shí)別成為研究重點(diǎn),2001 年,第一個(gè)實(shí)時(shí)人臉識(shí)別 應(yīng)用誕生。 在 21 世紀(jì)初,逐漸形成了視覺數(shù)據(jù)集標(biāo)記和注釋的標(biāo)準(zhǔn)化實(shí)踐。 2010 年,ImageNet 數(shù)據(jù)集公開可用。 該數(shù)據(jù)集包含上千種物體的數(shù)百萬張標(biāo)記的圖像,為如今使用的 CNN 和深度學(xué)習(xí)模型奠定了基礎(chǔ)。 2012 年,來自多倫多大學(xué)的團(tuán)隊(duì)帶著一個(gè) CNN 模型參加了圖像識(shí)別競賽。 這個(gè)名為 AlexNet 的模型顯著降低了圖像識(shí)別的錯(cuò)誤率。 在這一次突破后,錯(cuò)誤率已經(jīng)下降到僅僅百分之幾的水平。
圖像處理利用算法來更改圖像,包括銳化、平滑、過濾或增強(qiáng)。但計(jì)算機(jī) 視覺不同,因?yàn)樗⒉桓膱D像,而是理解它所發(fā)現(xiàn)的內(nèi)容并執(zhí)行任務(wù),例如進(jìn)行標(biāo)記。在某些情況下,可以利用圖像處理來修改圖像,以使計(jì)算機(jī) 視覺系統(tǒng)能夠更好地理解圖像。在其他情況下,可以利用計(jì)算機(jī) 視覺來識(shí)別圖像或圖像的某些部分,然后利用圖像處理進(jìn)一步修改圖像。
1、IBM 什么是計(jì)算機(jī) 視覺? 2、維基百科 計(jì)算機(jī) 視覺 3、Amazon 什么是計(jì)算機(jī) 視覺 4、《動(dòng)手學(xué)深度學(xué)習(xí)》 第13章節(jié):計(jì)算機(jī) 視覺