
PixverseAI互動功能(HUG)在AI擁抱視頻生成中的應用
比如用戶可能會問“我想看兩個男人在天臺決斗的電影”,此類問題在傳統NLP技術下是難以做到識別用戶是想看《無間道》的意圖的,而大模型強大的泛化推理能力可以很好的解決。
因此在整個鏈路中,首先重點要解決的就是意圖識別問題,我們在意圖識別領域使用大模型對傳統NLP能力進行了全面升級,本文的重點也是介紹大模型意圖識別能力在智能電視AI OS的核心鏈路中落地過程和思考。
意圖識別概念介紹
意圖識別(Intent Classification),是一種自然語言處理技術,用于分析用戶的輸入并將其映射到某個預定義的意圖類別。這種技術在問答機器人、智能客服、虛擬助手等領域被廣泛使用。其目的是通過分析用戶的文本或語音輸入,識別用戶的詢問、請求或指示真正的目的,從而提供個性化、準確的服務。
例如,在智能客服場景中,用戶輸入的語句可能比較模糊、復雜,包含著咨詢、抱怨、建議等多種潛在意圖,大模型通過意圖識別能力,剖析語句的語言模式、關鍵詞以及語義關聯等,準確判斷出用戶究竟是想要咨詢產品功能,還是對服務質量有所不滿,從而針對性地給出恰當回復,有效提升客戶服務體驗。
在大模型的應用體系里,意圖識別處于十分關鍵的位置,它就像是一座橋梁,連接著用戶模糊或明確的表達與大模型后續具體的任務執行,只有精準完成這一步驟,才能保證后續一系列動作的準確性和有效性,讓大模型真正成為幫助用戶解決問題、滿足需求的有力工具。
例如下面是一個企業內部對話機器人的例子:

在意圖層面有以下幾個概念:
意圖改寫:指在不改變用戶原始意圖的前提下,對用戶表達意圖的文本內容進行重新表述。例如,原始文本為 “明天的天氣”,改寫后的文本可以是 “幫我查一下明天的天氣狀況”。通過意圖改寫可以有效提高大模型輸出的準確率。
意圖分類:通過給不同的意圖分配特定標簽,便于大模型進行快速分類和處理。比如將意圖分為 “查詢類”“預訂類”“咨詢類” 等大的類別標簽,在 “查詢類” 下又可以細分出 “查詢天氣”“查詢航班” 等具體標簽。當用戶輸入內容后,大模型依據這些預設的標簽體系,能夠迅速判斷出所屬類別,從而采取相應的處理邏輯。
意圖槽位:意圖槽位在大模型意圖識別中起著關鍵作用,它就像是一個個精準捕捉用戶需求的 “小格子”。例如在用戶預訂機票的場景中,像出發地、目的地、出發時間、航班艙位等級等這些關鍵要素都可以看作是不同的意圖槽位。大模型通過分析用戶輸入的語句,嘗試將對應的信息填充到相應的槽位里,以此來更好地理解用戶究竟想要做什么。
意圖置信度:是指模型在預測用戶意圖時的自信程度。通常用一個概率值來表示,概率越高,表示模型對預測的意圖越有信心。例如,模型預測用戶意圖是 “產品咨詢”,置信度為 0.9,這就表明模型比較確定用戶的意圖是產品咨詢;如果置信度為 0.4,說明模型對這個預測不是很有把握。
意圖識別在智能電視中的落地挑戰
由于該場景處于電視C端業務的核心交互鏈路上,因此對意圖識別模塊也提出了更高的要求。該場景的落地挑戰主要來自于以下幾個方面:
1.延遲要求:由于全鏈路較長,用戶對延遲容忍度低,因此對意圖識別模型的延遲要求也非常苛刻,通常需要在500ms-800ms左右必須返回全包,以供后續鏈路繼續處理業務。
2.準確性要求:C端用戶對整體體驗效果敏感,不準確的意圖會導致全鏈路功能失效,無法達到用戶預期。因此對意圖識別模型的準確性要求非常高,需要保證簡單指令100%準確率,復雜指令98%+準確率。
3.實時數據處理能力:由于電視場景的特性,業務上需要涉及到最新的媒資信息或互聯網上較新的梗,例如“老默吃魚”,單純靠基模能力無法有效理解。因此需要將一些較新的知識內容注入給模型。
方案一:基模 + Prompt
開發成本低,適用于需要快速上線,對延時要求不高,分類相對簡單的場景。
該方案主要靠基模的推理能力,需要根據分類難度和延時要求選擇不同模型。建議至少使用32b以上的模型,如qwen-plus、qwen-max。
Prompt的實現也有較多寫法,這里是一些常用的實現技巧:
CoT的核心在于引導模型逐步構建一個邏輯鏈,這個鏈由一系列相關的推理步驟組成,每個步驟都是基于前一步的結果。這種方法有助于模型更好地理解問題的上下文和復雜性,并且增強了模型輸出的解釋性和可信度。
# 思考步驟為了完成上述目標,請按照下面的過程,一步一步思考后完成: 1.首先需要先理解候選的意圖信息共有如下{}個類別,每個意圖的含義或常見描述如下:{}
大模型具備強大的少樣本學習能力,通過在prompt中引入few shot少樣本可有效提高大模型在意圖識別分類任務中的能力。例如:
2. 然后,觀察以下意圖識別分類案例,學習意圖識別分類任務的能力:{}
3. 意圖識別前,請重點學習并記住以下識別準則:{}
(4)輸出示例
4. 請以JSON格式進行輸出,輸出示例:{}
基于以上原因,我們放棄了基模 + 提示詞的方案,該場景更適合業務相對簡單,延遲要求不敏感的業務場景。
方案二:基模 + Prompt + RAG
檢索增強生成(Retrieval-Augmented Generation,RAG)指的是在LLM回答問題之前從外部知識庫中檢索相關信息,RAG有效地將LLM的參數化知識與非參數化的外部知識庫結合起來,使其成為實現大型語言模型的最重要方法之一

鑒于方案一中垂類領域知識的問題,考慮加入RAG能力解決。通過在知識庫中上傳大量的意圖分類知識,使得該方案可以理解較為垂類或更個性化要求的分類判定邏輯。
該方案引入了RAG能力,對模型推理要求不是很高,建議選用性能相對性價比較高的模型,如qwen-turbo、qwen-plus。
以下是一些建議的步驟:
首先我們需要定義不同意圖的分類以及其槽位的設計,這些設計會和實際的業務場景以及后續承載具體實現的Agent密切相關,例如:

(2)數據生成
這里可以考慮給一些生產上用戶可能問的query示例,用LLM生成一批同義句,此處不再贅述
根據前面設計的意圖語料結構,使用大尺寸模型生成相關意圖分類和槽位,并可加入在線搜索相關能力,代碼示例和Prompt如下:
prompt = """# 角色你是一位意圖樣本生成專家,擅長根據給定的模板生成意圖及對應的槽位信息。你能夠準確地解析用戶輸入,并將其轉化為結構化的意圖和槽位數據。
## 技能### 技能1:解析用戶指令- **任務**:根據用戶提供的自然語言指令,識別出用戶的意圖。
### 技能2:生成結構化意圖和槽位信息- 意圖分類:video_search,music_search,information_search- 槽位分類:-- information_search: classification,video_category,video_name,video_season-- music_search: music_search,music_singer,music_tag,music_release_time-- video_search: video_actor,video_name,video_episode- **任務**:將解析出的用戶意圖轉換為結構化的JSON格式。 - 確保每個意圖都有相應的槽位信息,不要自行編造槽位。 - 槽位信息應包括所有必要的細節,如演員、劇名、集數、歌手、音樂標簽、發布時間等。
### 技能3:在線搜索- 如果遇到關于電影情節的描述,可以調用搜索引擎獲取到電影名、演員等信息稱補充到actor,name等槽位中
### 輸出示例 - 以JSON格式輸出,例如: -"這周杭州的天氣如何明天北京有雨嗎":{'infor_search':{'extra_info':['這周杭州的天氣如何明天北京有雨嗎']}} -"我一直在追趙麗穎的楚喬傳我看到第二十集了它已經更新了嗎我可以看下一集嗎":{'video_search':{'video_actor':['趙麗穎'],'video_name':['楚喬傳'],'video_episode':['第21集'],'extra_info':['我一直在追趙麗穎的楚喬傳我看到第二十集了它已經更新了嗎我可以看下一集嗎']}}
## 限制- 只處理與意圖生成相關的任務。- 生成的意圖和槽位信息必須準確且完整。- 在解析過程中,確保理解用戶的意圖并正確映射到相應的服務類型- 如果遇到未知的服務類型或槽位信息,可以通過調用搜索工具進行補充和確認。- 直接輸出Json,不要輸出其他思考過程生成后的用于知識庫的數據集格式如下:
[{“instruction”:”播放一首七仔的歌曲我想聽他的經典老歌最好是70年代的音樂風格”,”output”:”{‘music_search’:{‘singer’:[‘張學友’],’music_tag’:[‘經典老歌’],’release_time’:[’70年代’]}}”}]
這里有非常多成熟的方案可以選擇,可以考慮阿里云百煉平臺的RAG方案,此處不再贅述。
因此,該方案也不太適用于電視C端交互鏈路上,但是方案二關于數據增強的思路還是值得借鑒的,基于這個思路,我們可以嘗試用小尺寸模型SFT的方案
方案三:使用小尺寸模型進行SFT
通過小尺寸模型解決延遲問題,通過微調解決數據增強問題
一般而言,模型底座越大,下游任務效果越好,但是部署成本和推理代價相應增大。針對意圖識別的場景,建議從4B左右的大模型底座開始進行SFT和調參,當效果較大同時通過調參無法進一步提升時,建議換成7B的更大底座。超過10B的底座理論上能得到更好的結果,但是需要權衡實際的效果和成本問題,因此本場景使用7B的底座性價比較高。
選用LoRA方式進行微調

LoRA 原理(來源 LoRA 論文:LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS)
LoRa算法在固定主預訓練參數的情況下,用支路去學習特定任務知識,來完成特定任務。它的假設為模型適應時的權重改變總是“低秩”的。訓練方法為在每層transfomer block旁邊引入一個并行低秩的支路,支路的輸入是transfomer block的輸入,然后將輸出和transfomer block的輸出相加。訓練完后將原始權重加上LoRA訓練的權重(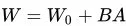 ),最終使得模型結構不變。
),最終使得模型結構不變。
SFT的大致流程如下:

參考方案二中的意圖預料設計,此處不再贅述
樣本生成有很多方式,比如前面提到的LLM生成或是引入一些數據預處理工具。筆者這里使用的是PAI-iTag工具。首先,將用于iTag標注的數據注冊到PAI數據集,該數據集為manifest格式文件,內容示例如下:
{“data”:{“instruction”: “我想聽音樂”}}{“data”:{“instruction”: “太吵了,把聲音開小一點”}}{“data”:{“instruction”: “我不想聽了,把歌關了吧”}}{“data”:{“instruction”: “我想去杭州玩,幫我查下天氣預報”}}
標注完成后可以將標注結果導出至OSS,在本示例中,輸出文件內容如下:
{“data”:{“instruction”:”我想聽音樂”,”_itag_index”:””},”label-1787402095227383808″:{“results”:[{“questionId”:”2″,”data”:”play_music()”,”markTitle”:”output”,”type”:”survey/value”}]},”abandonFlag”:0,”abandonRemark”:null}{“data”:{“instruction”:”太吵了,把聲音開小一點”,”_itag_index”:””},”label-1787402095227383808″:{“results”:[{“questionId”:”2″,”data”:”volume_down()”,”markTitle”:”output”,”type”:”survey/value”}]},”abandonFlag”:0,”abandonRemark”:null}{“data”:{“instruction”:”我不想聽了,把歌關了吧”,”_itag_index”:””},”label-1787402095227383808″:{“results”:[{“questionId”:”2″,”data”:”music_exit()”,”markTitle”:”output”,”type”:”survey/value”}]},”abandonFlag”:0,”abandonRemark”:null}{“data”:{“instruction”:”我想去杭州玩,幫我查下天氣預報”,”_itag_index”:””},”label-1787402095227383808″:{“results”:[{“questionId”:”2″,”data”:”weather_search(杭州)”,”markTitle”:”output”,”type”:”survey/value”}]},”abandonFlag”:0,”abandonRemark”:null}
標注完成的數據格式說明參考標注數據格式概述。為了在PAI-ModelGallery
種使用標注數據進行模型訓練,需要將上述文件轉化為PAI-ModelGallery
接受的訓練數據格式,可以參考如下Python腳本:
# 輸入文件路徑和輸出文件路徑input_file_path = 'test_json.manifest'output_file_path = 'train.json'
converted_data = []with open(input_file_path, 'r', encoding='utf-8') as file: for line in file: data = json.loads(line) instruction = data['data']['instruction'] for key in data.keys(): if key.startswith('label-'): output = data[key]['results'][0]['data'] converted_data.append({'instruction': instruction, 'output': output}) break
with open(output_file_path, 'w', encoding='utf-8') as outfile: json.dump(converted_data, outfile, ensure_ascii=False, indent=4)全參數微調消耗計算資源最多,而且容易使大模型產生災難性遺忘,LoRA和QLoRA有效地避免了這個問題。另一方面,QLoRA由于參數精度低,容易對下游任務的效果產生不利影響。綜合考慮,使用LoRA算法進行微調。
全局批次大小=卡數*per_device_train_batch_size*gradient_accumulation_steps
這里在GPU顯存允許的情況下盡可能調大batch size,可以使得模型更快收斂到最優解,同時具有較高的泛化能力。
序列長度對顯存消耗和訓練效果有較大的影響,過小的序列長度雖然節省了顯存,但是導致某些比較長的訓練數據集被切斷,造成不利影響;過大的序列長度又會造成顯存的浪費。從意圖識別的場景來看,根據實際數據的長度,選擇64/128/256的長度比較合適。
如果訓練數據質量比較差,訓練效果一般會受影響,所以在數據標注的時候需要進行充分的質量校驗。同時,由于LoRA訓練一般參數調整空間不大,學習率默認可以進行偏大設置,例如1e-4左右,當訓練loss下降過慢或者不收斂時,建議適當調大學習率,例如3e-4或者5e-4。不建議使用1e-3這個量級的學習率,容易得不到優化的結果。
一般而言,模型底座越大,下游任務效果越好,但是部署成本和推理代價相應增大。針對意圖識別的場景,建議從4B左右的大模型底座開始進行SFT和調參,當效果較大同時通過調參無法進一步提升時,建議換成7B的更大底座。超過10B的底座理論上能得到更好的結果,但是需要權衡實際的效果和成本問題,因此,因此本場景使用7B的底座性價比較高。
(4)啟動訓練任務

值得注意的是,如果需要在訓練過程中改變默認的system_prompt,讓大模型扮演某種特定的角色,可以在Qwen1.5系列模型的訓練中配置自定義的
system_prompt,例如“你是一個意圖識別專家,可以根據用戶的問題識別出意圖,并返回對應的意圖和參數”。在這種情況下,給定一個訓練樣本:
[ { “instruction”:”我想聽音樂”, “output”:”play_music()” }]
實際用于訓練的數據格式如下:
<|im_start|>system\n你是一個意圖識別專家,可以根據用戶的問題識別出意圖,并返回對應的意圖和參數<|im_end|>\n<|im_start|>user\n我想聽音樂<|im_end|>\n<|im_start|>assistant\nplay_music()<|im_end|>\n
當設置apply_chat_template為true并且添加system_prompt,算法會自行對訓練數據進行擴展,無需關注執行細節。
當模型訓練結束后,可以使用如下Python腳本進行模型效果的評測。假設評測數據如下:
[ { “instruction”:”想知道的十年是誰唱的?”, “output”:”music_query_player(十年)” }, { “instruction”:”今天北京的天氣怎么樣?”, “output”:”weather_search(杭州)” }]
評測腳本如下所示:
#encoding=utf-8from transformers import AutoModelForCausalLM, AutoTokenizerimport jsonfrom tqdm import tqdm
device = "cuda" # the device to load the model onto
# 修改模型路徑model_name = '/mnt/workspace/model/qwen14b-lora-3e4-256-train/'print(model_name)model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto")tokenizer = AutoTokenizer.from_pretrained(model_name)
count = 0ecount = 0
# 修改訓練數據路徑test_data = json.load(open('/mnt/workspace/data/testdata.json'))system_prompt = '你是一個意圖識別專家,可以根據用戶的問題識別出意圖,并返回對應的函數調用和參數。'
for i in tqdm(test_data[:]): prompt = '<|im_start|>system\n' + system_prompt + '<|im_end|>\n<|im_start|>user\n' + i['instruction'] + '<|im_end|>\n<|im_start|>assistant\n' gold = i['output'] gold = gold.split(';')[0] if ';' in gold else gold
model_inputs = tokenizer([prompt], return_tensors="pt").to(device) generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=64, pad_token_id=tokenizer.eos_token_id, eos_token_id=tokenizer.eos_token_id, do_sample=False ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] pred = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] if gold.split('(')[0] == pred.split('(')[0]: count += 1 gold_list = set(gold.strip()[:-1].split('(')[1].split(',')) pred_list = set(pred.strip()[:-1].split('(')[1].split(',')) if gold_list == pred_list: ecount += 1 else: pass
print("意圖識別準確率:", count/len(test_data))print("參數識別準確率:", ecount/len(test_data))部署的推理服務支持使用ChatLLM WebUI進行實時交互,也可以使用API進行模型推理,具體使用方法參考5分鐘使用EAS一鍵部署LLM大語言模型應用:
https://help.aliyun.com/zh/pai/use-cases/deploy-llm-in-eas
以下給出一個示例request客戶端調用:
import argparseimport jsonfrom typing import Iterable, List
import requests
def post_http_request(prompt: str, system_prompt: str, history: list, host: str, authorization: str, max_new_tokens: int = 2048, temperature: float = 0.95, top_k: int = 1, top_p: float = 0.8, langchain: bool = False, use_stream_chat: bool = False) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "use_stream_chat": use_stream_chat, "history": history } response = requests.post(host, headers=headers, json=pload, stream=use_stream_chat) return response
def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] history = data["history"] return output, history
if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=4) parser.add_argument("--top-p", type=float, default=0.8) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=0.95) parser.add_argument("--prompt", type=str, default="How can I get there?") parser.add_argument("--langchain", action="store_true")
args = parser.parse_args()
prompt = args.prompt top_k = args.top_k top_p = args.top_p use_stream_chat = False temperature = args.temperature langchain = args.langchain max_new_tokens = args.max_new_tokens
host = "EAS服務公網地址" authorization = "EAS服務公網Token"
print(f"Prompt: {prompt!r}\n", flush=True) # 在客戶端請求中可設置語言模型的system prompt。 system_prompt = "你是一個意圖識別專家,可以根據用戶的問題識別出意圖,并返回對應的意圖和參數"
# 客戶端請求中可設置對話的歷史信息,客戶端維護當前用戶的對話記錄,用于實現多輪對話。通常情況下可以使用上一輪對話返回的histroy信息,history格式為List[Tuple(str, str)]。 history = [] response = post_http_request( prompt, system_prompt, history, host, authorization, max_new_tokens, temperature, top_k, top_p, langchain=langchain, use_stream_chat=use_stream_chat) output, history = get_response(response) print(f" --- output: {output} \n --- history: {history}", flush=True)
# 服務端返回JSON格式的響應結果,包含推理結果與對話歷史。def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] history = data["history"] return output, history在智能電視意圖識別場景中,為了保證用戶的交互體驗,通常要求更高的延時,因此建議使用PAI提供的BladeLLM推理引擎進行LLM服務的部署。
因為主要靠微調提升效果,Promp的寫法相對簡單,不再預置業務規則和思維鏈:
{"role": "system", "content": "你是個意圖識別專家,你要通過用戶的輸入,識別用戶的意圖以及槽位信息,注意:不要添加沒有的意圖和槽位。"}幾種方案的對比:

在實際的生成鏈路上,我們發現要保證準確率、時效性、以及成本之間,還有一些工作要做,主要包含以下幾個靈魂拷問:
1.如何保證生產準確率持續符合要求?
互聯網上的信息更新迭代很快,尤其是在娛樂性質較重的媒資類產品上,幾乎每天都會產生新的電視/電影/音樂等信息;一些互聯網上的梗也持續出現,比如“老默吃魚”,“蔣欣在這里”等等,用戶個性化的問法也是層出不窮,如何能持續保證生產的準確率符合98%以上的預期是一個難題。
2.如何在生產環境上對結果糾錯?
電視場景的交互是以語音為主,不太涉及觸屏等精細化交互操作。如果客戶對某個答案不滿意,并不會像PC或手機上的智能機器人那樣有一個“點踩”的反饋渠道。出現大量事實性錯誤時,只能通過用戶投訴得到反饋,這會極大有損用戶體驗。所以如何拿到生產的意圖結論對錯成為一個待解決的問題。
3.海量C端用戶的指令無法窮舉,大量的訓練集如何產生?
我們通過微調解決垂直業務數據問題,前期我們準備的訓練數據只能解決一小部分問題,實際生產上微調模型是需要不停的迭代的,那么微調的數據要從要哪里來也是一個很重要的問題。
4.訓練集不停變大,反復SFT耗時耗力,有沒有自動化的方案?
當我們拿到了訓練集后,需要人工在平臺上進行模型訓練和部署,如果這個操作頻率精細化到每天都要處理,那么無疑對人力成本的消耗是巨大的。所以有沒有一個全自動化的方案能幫我們解決這些問題?
通過設計完整的離線質檢工程鏈路,持續自動訓練和部署最新模型,解決生產準確率、訓練集和微調模型成本的問題。

該方案通過多步驟處理流程,實現了自動對線上意圖質檢及自動重新訓練的流程。總體上分為在線流程和離線流程兩部分,以下是詳細的流程描述:
在線流程:
1.用戶的query先經過一道意圖緩存庫,該庫直接以query為key,將曾經正確返回的意圖結果存儲在es中。當緩存被命中時直接將結果返回,不再走后續鏈路,以此提高響應速度和保證準確性。該緩存庫主要是為一些簡單意圖如系統指令、媒資名搜索做快速結果返回
2.如果未命中緩存,則走到后續的模型推理鏈路。當前使用的是微調后的qwen-7b模型
離線流程:
1.當大模型輸出意圖推理結果后,會異步將query+reponse傳入給一個意圖優化應用,作為整體質檢的入口
2.調用一個大尺寸模型,例如qwen-max對結果進行質檢。質檢規則是輸出response相對于result的得分情況,滿分為1分,只有0.9分以上的答案才認為是正確的
3.如果意圖準確,則重新將此次的意圖結果寫進緩存中,方便下次調用讀取
4.如果意圖得分低于0.9,認為該意圖生成質量不佳,此時會嘗試使用大尺寸模型如qwen-max進行意圖的重新生成。需要注意的是,此質檢agent會引入LLM實時搜索能力,保證對一些較新的query信息做好理解
5.當意圖生成agent的答案重新通過質檢后,會更新到訓練集中,以供下一次SFT使用
在某國產頭部電視廠家落地過程中,最終經過多輪技術選型,我們決策使用PAI平臺進行qwen-7b模型的訓練和推理部署,該方案準確率和延遲上都有較大優勢,平均延遲500ms,生產實時準確率達到98%+。
隨著電視技術的迅猛發展和用戶交互模式的日益多樣化,意圖識別技術在增強用戶體驗中發揮著不可或缺的作用。本文聚焦于電視環境中大模型意圖識別的核心技術、所面臨的挑戰以及當前的解決方案。
AI大模型技術還在不斷高速迭代更新,作為阿里云大模型技術服務團隊將陪伴客戶共同成長,一起見證更加智能且人性化的電視互動體驗的誕生。通過持續優化和升級現有的大模型結構,并融入多維度的數據源——例如語音情感分析與視覺內容感知等先進技術,未來的電視設備將不僅能夠準確理解用戶的指令,還能夠預判其需求,提供超越預期的個性化服務。
這種進步將重新定義觀眾與電視之間的互動方式,開啟智能家居娛樂的新紀元。






