除了更新文本編碼方法外,我們還對負(fù)責(zé)去除圖片噪聲的 U-Net 架構(gòu)進(jìn)行了大規(guī)模研究。主要的難題是哪種類型的層將包含大部分網(wǎng)絡(luò)參數(shù):Transformer 層還是卷積層。在對大量數(shù)據(jù)進(jìn)行訓(xùn)練時,Transformer 在圖像上的表現(xiàn)更好,但幾乎所有擴散模型的 U-Net 架構(gòu)都是以卷積為主的。為了解決這個難題,我們分析了不同的架構(gòu),并為自己指出了以下模型:
- ResNet-18、ResNet-50 是眾所周知的架構(gòu),但有一個值得注意的點。小版本中的卷積塊與大版本中的卷積塊的不同之處在于,存在一個瓶頸,負(fù)責(zé)在通過 3×3 卷積處理張量之前壓縮通道數(shù)。這可以減少參數(shù)數(shù)量,從而增加網(wǎng)絡(luò)深度,這在實踐中可以提供更好的訓(xùn)練結(jié)果。

CoAtNet 是一種結(jié)合了卷積和注意力模塊的架構(gòu)。其主要思想是,在初始階段,圖像應(yīng)通過局部卷積進(jìn)行處理,而其已壓縮的表示則通過提供圖像元素全局交互的轉(zhuǎn)換層進(jìn)行處理。

MaxViT 是一種幾乎完全基于變壓器塊的架構(gòu),但通過降低自注意力的二次復(fù)雜度來適應(yīng)處理圖像。

使用分類模型的想法受到這樣一個事實的啟發(fā):許多好的架構(gòu)解決方案都取自在 ImageNet 基準(zhǔn)上表現(xiàn)出色的模型。然而,我們的實驗表明,質(zhì)量遷移的效果并不明確。在分類任務(wù)上表現(xiàn)最好的 MaxVit 架構(gòu)在將其轉(zhuǎn)換為 U-Net 后,在生成任務(wù)上的表現(xiàn)并不理想。在研究了上述所有架構(gòu)后,我們決定將 ResNet-50 塊作為基本的 U-Net 塊,并借用 BigGan 的論文中的想法,為其添加了另一個具有 3×3 核心的卷積層。
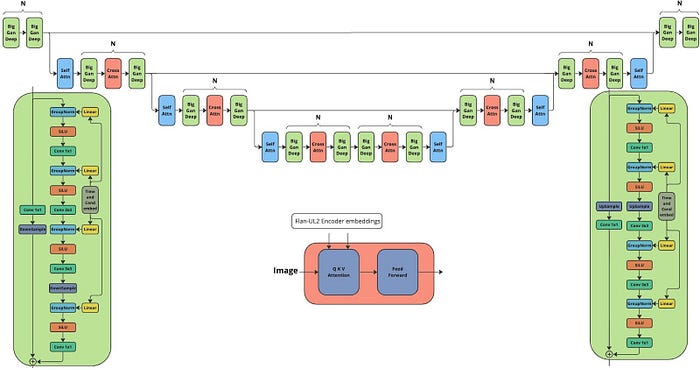
最終,康定斯基3.0建筑由三個主要部分組成:
- Flan-UL2 ,編碼器-解碼器架構(gòu)的語言模型。對于文本編碼,我們只采用了編碼器,它占了整個架構(gòu)參數(shù)的一半。除了在文本語料庫上進(jìn)行預(yù)訓(xùn)練外,此版本還在大量語言任務(wù)語料庫上以 SFT 風(fēng)格進(jìn)行了預(yù)訓(xùn)練。我們的實驗表明,SFT 顯著提高了圖像生成。在模型映射部分的訓(xùn)練過程中,語言模型完全凍結(jié)。
- U-Net 的架構(gòu)如下所示,主要由 BigGAN 深度塊組成。與其他基于傳統(tǒng) BigGAN 塊的擴散相比,該架構(gòu)的深度增加了一倍,同時保持了相同數(shù)量的參數(shù)。
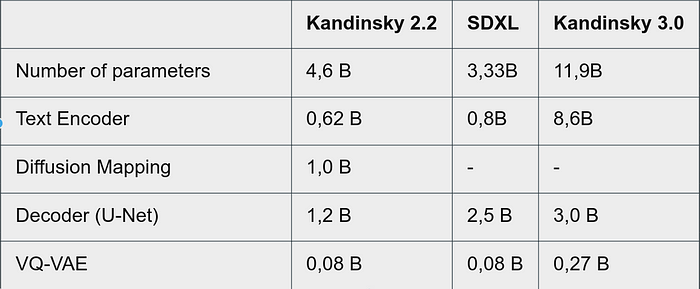 與競爭對手的比較
與競爭對手的比較
Kandinsky 3.0 模型訓(xùn)練數(shù)據(jù)
訓(xùn)練使用了從互聯(lián)網(wǎng)上收集的許多文本-圖片對。這些數(shù)據(jù)經(jīng)過了眾多篩選:圖像美觀度、圖像與文本匹配、重復(fù)、分辨率和長寬比。與 Kandinsky 2.2 相比,我們擴展了所使用的數(shù)據(jù)集,用新數(shù)據(jù)豐富了數(shù)據(jù)集,添加了俄語實體,并添加了使用最先進(jìn)的多模態(tài)模型生成描述的圖像。
訓(xùn)練過程分為幾個階段,這使得我們可以使用更多的訓(xùn)練數(shù)據(jù),以及生成不同大小的圖像。
- 256 × 256:11 億個文本-圖片對,批量大小為 20,600k 步,100 個 A100
- 384×384:7.68 億個文本到圖片對,批量大小 10,500k 步,100 個 A100。
- 512 × 512:4.5 億個文本-圖片對,批量大小為 10,40 萬步,100 個 A100
- 768 × 768:2.24 億個文本到圖片對,批量大小為 4,250k 步,416 A100
- 混合分辨率:768≤寬×高≤1024,2.8 億個文本-圖片對,批量大小 1,35 萬步,416 個 A100
Kandinsky 3.0 文本生成圖像示例
 鉤針編織藝術(shù)風(fēng)格的美麗戶外風(fēng)景,由 Alfons Mucha 繪制
鉤針編織藝術(shù)風(fēng)格的美麗戶外風(fēng)景,由 Alfons Mucha 繪制
 汽車、野馬、電影、人物、海報、車罩、人物、亞歷山德羅·戈塔多的風(fēng)格、金色和青色、杰拉爾德·哈維·瓊斯、反射、高度詳細(xì)的插圖、工業(yè)城市場景
汽車、野馬、電影、人物、海報、車罩、人物、亞歷山德羅·戈塔多的風(fēng)格、金色和青色、杰拉爾德·哈維·瓊斯、反射、高度詳細(xì)的插圖、工業(yè)城市場景
 美麗的童話沙漠,天空中一波沙與銀河融為一體,星星,宇宙主義,數(shù)字藝術(shù),8k
美麗的童話沙漠,天空中一波沙與銀河融為一體,星星,宇宙主義,數(shù)字藝術(shù),8k
 抽象畫由黃色和紅色、黑色和白色以及綠色色調(diào)組成,采用紅色和橙色的風(fēng)格,抽象具象大師、伊博藝術(shù)、狂熱行動繪畫、澳大利亞原住民、袋鼠、仙人掌磨損、安古拉凱
抽象畫由黃色和紅色、黑色和白色以及綠色色調(diào)組成,采用紅色和橙色的風(fēng)格,抽象具象大師、伊博藝術(shù)、狂熱行動繪畫、澳大利亞原住民、袋鼠、仙人掌磨損、安古拉凱
 白色背景圖像和 Daz3d 風(fēng)格充氣 Kitty 貓出汗娃娃,簡化的 Kitty 貓圖像,超高清圖像,透明/半透明介質(zhì),8k,c4d,oc,blende
白色背景圖像和 Daz3d 風(fēng)格充氣 Kitty 貓出汗娃娃,簡化的 Kitty 貓圖像,超高清圖像,透明/半透明介質(zhì),8k,c4d,oc,blende
 丹麥峽灣邊緣的一座黃色房子,風(fēng)格類似埃科·奧亞拉、英格麗德·巴爾斯、廣告海報、山景、喬治·奧特、逼真的細(xì)節(jié)、深白色和深灰色,4k
丹麥峽灣邊緣的一座黃色房子,風(fēng)格類似埃科·奧亞拉、英格麗德·巴爾斯、廣告海報、山景、喬治·奧特、逼真的細(xì)節(jié)、深白色和深灰色,4k
 火龍果頭,上身,逼真,Joshua Hoffine Norman Rockwell 的插圖,恐怖,令人毛骨悚然,生物黑客,未來主義,扎哈·哈迪德風(fēng)格
火龍果頭,上身,逼真,Joshua Hoffine Norman Rockwell 的插圖,恐怖,令人毛骨悚然,生物黑客,未來主義,扎哈·哈迪德風(fēng)格
 紫色的花朵坐落在郁郁蔥蔥的綠色田野之上,靈感來自 Mike Winkelmann、仙人掌、可愛的 c4d、海上朋克、粉紅色的風(fēng)景、拋光的原始水域、迷人的夢想、夢想。instagram、沙漠綠洲、cgsocciety、數(shù)字藝術(shù)、3D 渲染、4k
紫色的花朵坐落在郁郁蔥蔥的綠色田野之上,靈感來自 Mike Winkelmann、仙人掌、可愛的 c4d、海上朋克、粉紅色的風(fēng)景、拋光的原始水域、迷人的夢想、夢想。instagram、沙漠綠洲、cgsocciety、數(shù)字藝術(shù)、3D 渲染、4k
Kandinsky 3.0 比較結(jié)果與生成示例
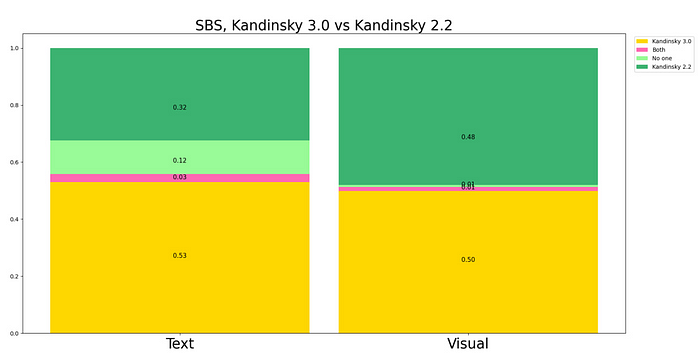
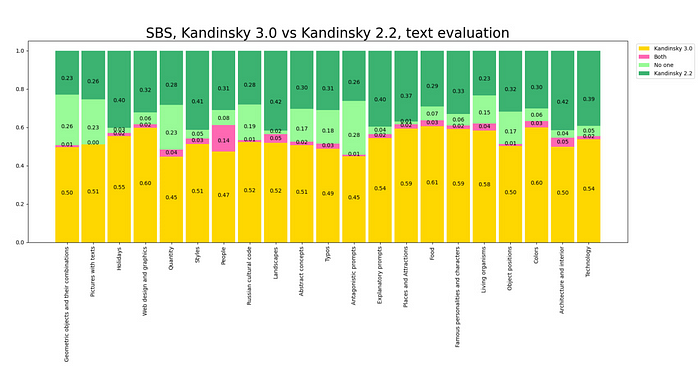
為了比較模型,我們收集了 21 個類別的 2100 個提示,并比較了不同的 Kandinsky 3.0 權(quán)重以選出最佳的提示。為此,我們進(jìn)行了三次并排運行,使用了 28 個標(biāo)記。然后,當(dāng)選擇了 Kandinsky 3.0 模型的最佳版本時,與 Kandinsky 2.2 模型進(jìn)行了并排比較。12 個人參與了這項研究,總共投票 24,800 次。為此,他們開發(fā)了一個機器人,可以顯示 2,100 對圖像中的一對。每個人根據(jù)兩個標(biāo)準(zhǔn)選擇最佳圖像:
- 與文本的相關(guān)性,
- 圖像的視覺質(zhì)量。
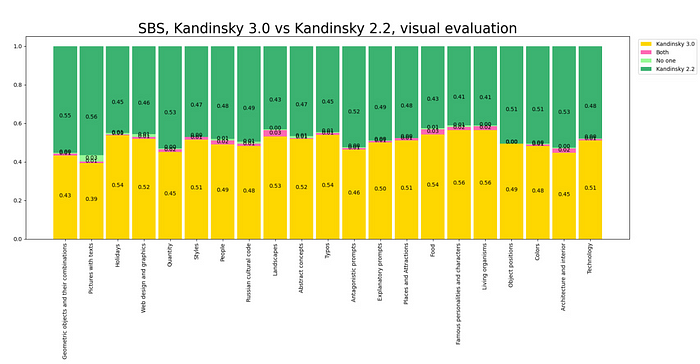
對所有類別的視覺質(zhì)量和文本理解進(jìn)行了總體比較,并對每個類別進(jìn)行了單獨比較:
以下是與康定斯基 3.0 相比的流行模型代示例:
 美麗的女孩
美麗的女孩
 這是一幅非常精細(xì)的數(shù)字繪畫,描繪了一座神秘森林中的門戶,森林里有許多美麗的樹木。一個人站在門戶前。
這是一幅非常精細(xì)的數(shù)字繪畫,描繪了一座神秘森林中的門戶,森林里有許多美麗的樹木。一個人站在門戶前。
 留著胡子的男人
留著胡子的男人
 一張 4K 數(shù)碼單反相機拍攝的照片,一只刺猬坐在池塘中央的一艘小船上。它穿著夏威夷襯衫,戴著草帽。它正在看書。背景中有幾片樹葉。
一張 4K 數(shù)碼單反相機拍攝的照片,一只刺猬坐在池塘中央的一艘小船上。它穿著夏威夷襯衫,戴著草帽。它正在看書。背景中有幾片樹葉。
 芭比和肯正在購物
芭比和肯正在購物
 奢華的令人垂涎欲滴的漢堡,配有各種配料。突出層次和質(zhì)感
奢華的令人垂涎欲滴的漢堡,配有各種配料。突出層次和質(zhì)感
 一只戴著俄羅斯民族帽子、拿著巴拉萊卡琴的熊
一只戴著俄羅斯民族帽子、拿著巴拉萊卡琴的熊
修復(fù) + 修復(fù)外貌
我們的團隊為 Fusion Brain 網(wǎng)站開發(fā)了修復(fù)/外繪模型,借助該模型,您可以編輯圖像:更改圖像內(nèi)必要的對象和整個區(qū)域( 修復(fù)方法 ),或通過外繪方法將其擴展到巨大的全景圖,添加新的細(xì)節(jié)。修復(fù)任務(wù)比標(biāo)準(zhǔn)生成復(fù)雜得多,因為必須學(xué)習(xí)不僅從文本生成模型,還要使用圖像上下文來生成模型。
為了訓(xùn)練模型的修復(fù)部分,我們使用了 GLIDE 方法,該方法之前已在 Kandinsky 系列模型以及穩(wěn)定擴散系列模型中實現(xiàn):U-Net 的輸入層經(jīng)過修改,以便輸入可以額外接受圖像潛在和蒙版。因此,U-Net 最多接受 9 個通道作為輸入:4 個用于原始潛在,4 個用于圖像潛在,一個額外的通道用于蒙版。從修改的角度來看,進(jìn)一步的訓(xùn)練與標(biāo)準(zhǔn)擴散模型的訓(xùn)練并無不同
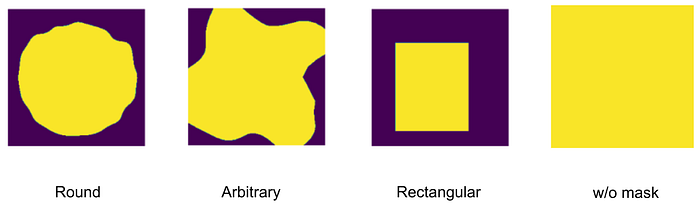
該任務(wù)的一個重要特征是如何生成蒙版以及訓(xùn)練時使用哪些文本。用戶可以使用畫筆繪制蒙版,也可以通過外繪繪制新圖像。為了考慮用戶的工作方式,我們在訓(xùn)練期間創(chuàng)建了模仿其行為的特殊蒙版:任意形狀的畫筆繪制蒙版、對象蒙版和圖像填充
因此,該模型可以很好地應(yīng)對圖像替換和圖像增強(參見示例)
修復(fù)示例

 火箭
火箭

 一艘大船在河里航行
一艘大船在河里航行

 坐在長凳上的機器人
坐在長凳上的機器人
Outpainting 示例

 日落時分,摩天大樓林立的未來主義城市景觀
日落時分,摩天大樓林立的未來主義城市景觀

 寧靜的海灘日落,棕櫚樹和溫柔的海浪
寧靜的海灘日落,棕櫚樹和溫柔的海浪

 一片神秘的森林,有高聳的古樹和發(fā)光的蘑菇
一片神秘的森林,有高聳的古樹和發(fā)光的蘑菇
Deforum
隨著 Kandinsky 3.0 的推出,我們還更新了 Deforum,這是一項允許我們通過圖像到圖像的方法生成動畫視頻的技術(shù)。

將框架適配到新模型的主要困難在于擴散過程中噪聲添加方式的不同:Kandinsky 2.2 按照線性時間表添加噪聲(上圖),而 Kandinsky 3.0 按照余弦時間表添加噪聲(下圖)。這個特性需要大量的實驗才能適應(yīng)。
動畫示例
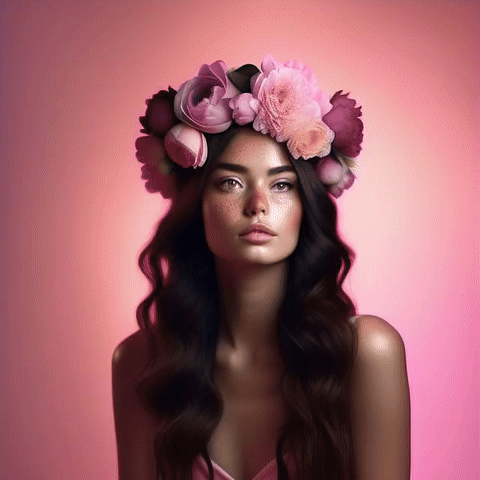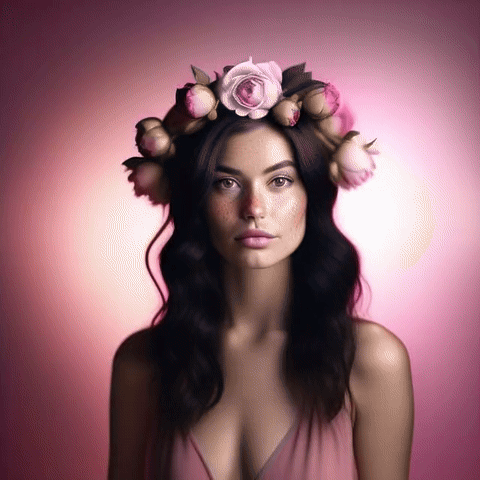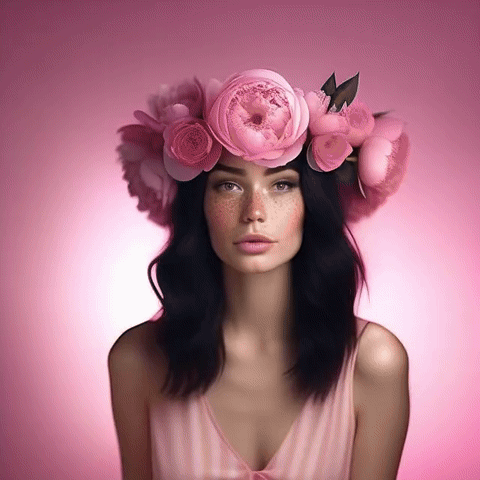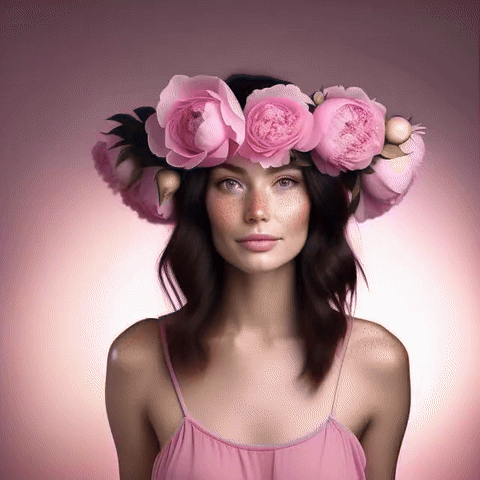 美麗的女人,深色頭發(fā),雀斑,大牡丹和玫瑰花冠,美麗的漸變粉色背景,頂燈,專業(yè)攝影,工作室攝影,4k;模式:“直播”
美麗的女人,深色頭發(fā),雀斑,大牡丹和玫瑰花冠,美麗的漸變粉色背景,頂燈,專業(yè)攝影,工作室攝影,4k;模式:“直播”
 極致細(xì)節(jié)、8k、超高品質(zhì)、杰作、景深、柔和的燈光、插圖、非常可愛逼真的切布拉特卡,身穿夾克,手里拿著橘子,錯綜復(fù)雜的清晰細(xì)節(jié),b 維照明,令人難以置信的細(xì)節(jié)比例,令人難以置信的細(xì)節(jié)眼睛,大耳朵,令人難以置信的細(xì)節(jié)特寫視圖,彩虹光,詳細(xì)的透明涂層,雪,冬季城市,煙花,燈光,電光花,花環(huán),歡樂,笑聲,微笑,善良,幸福
極致細(xì)節(jié)、8k、超高品質(zhì)、杰作、景深、柔和的燈光、插圖、非常可愛逼真的切布拉特卡,身穿夾克,手里拿著橘子,錯綜復(fù)雜的清晰細(xì)節(jié),b 維照明,令人難以置信的細(xì)節(jié)比例,令人難以置信的細(xì)節(jié)眼睛,大耳朵,令人難以置信的細(xì)節(jié)特寫視圖,彩虹光,詳細(xì)的透明涂層,雪,冬季城市,煙花,燈光,電光花,花環(huán),歡樂,笑聲,微笑,善良,幸福
 超級美麗的冬季森林
超級美麗的冬季森林
結(jié)論和計劃
我們推出了新的基于文本的圖像生成架構(gòu)——Kandinsky 3.0。與之前的模型相比,我們對文本和俄羅斯文化的理解有了顯著提高,我們一定會繼續(xù)朝這個方向努力。在科學(xué)方面,我們的計劃包括創(chuàng)建另一個新一代模型,它將在人工智能領(lǐng)域嶄露頭角。
人工智能和生成學(xué)習(xí)領(lǐng)域為進(jìn)一步發(fā)展開辟了廣闊的空間,誰知道呢,也許在不久的將來,像我們的康定斯基這樣的模型會形成一個新的現(xiàn)實——與現(xiàn)在的現(xiàn)實沒有太大區(qū)別。這些變化對人類的影響很難判斷,而且有陷入許多可疑猜測的風(fēng)險。作為研究人員,我們要警惕過于悲觀和樂觀的預(yù)測。但我們可以肯定的是,這種發(fā)展無論如何都會非常有趣,需要改變我們對周圍許多事物的看法。我們?nèi)祟愡€沒有意識到生成學(xué)習(xí)的全部力量。請繼續(xù)關(guān)注,以免錯過世界將如何改變,包括通過我們的努力!
文章轉(zhuǎn)載自:Kandinsky 3.0 — a new model for generating images from text
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業(yè)工程師共享工作效率翻倍的秘密
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
亚洲18影院在线观看|
五月激情六月综合|
国产午夜亚洲精品不卡|
日本在线不卡视频一二三区|
91成人网在线|
亚洲在线观看免费|
91麻豆精品久久久久蜜臀|
亚洲成a人v欧美综合天堂|
在线播放日韩导航|
久久99国产乱子伦精品免费|
久久久www免费人成精品|
波多野结衣一区二区三区|
亚洲精品第一国产综合野|
7777精品伊人久久久大香线蕉超级流畅|
午夜久久电影网|
国产女人18毛片水真多成人如厕
|
韩国女主播成人在线观看|
久久精品亚洲国产奇米99|
97精品超碰一区二区三区|
一区二区三区免费网站|
精品国产麻豆免费人成网站|
99精品视频一区二区|
蜜臀av性久久久久蜜臀aⅴ四虎|
国产三级精品三级|
91精品国产色综合久久ai换脸|
国产激情精品久久久第一区二区|
亚洲狠狠丁香婷婷综合久久久|
日韩精品中午字幕|
在线精品视频免费播放|
国产成人在线视频免费播放|
日本中文字幕一区二区有限公司|
国产精品久久久久影院老司|
日韩欧美精品三级|
欧洲人成人精品|
成人国产免费视频|
久久免费电影网|
国产精品卡一卡二卡三|
欧美一区二区高清|
波多野结衣中文一区|
国产一区二区主播在线|
视频一区国产视频|
香蕉久久夜色精品国产使用方法|
国产精品每日更新在线播放网址|
日韩精品一区二区三区四区视频|
在线观看成人小视频|
色呦呦日韩精品|
99re6这里只有精品视频在线观看
99re8在线精品视频免费播放
|
91尤物视频在线观看|
国产精品一区二区三区乱码|
日本中文在线一区|
污片在线观看一区二区|
亚洲午夜免费福利视频|
亚洲欧美国产77777|
亚洲色图一区二区三区|
中文欧美字幕免费|
国产精品国产成人国产三级
|
色婷婷综合久色|
99视频有精品|
一道本成人在线|
欧美影视一区在线|
91精品国产综合久久久蜜臀粉嫩
|
国产成人一区二区精品非洲|
国产在线播放一区|
成人午夜伦理影院|
一本久久精品一区二区|
欧美专区在线观看一区|
91麻豆精品国产91久久久久|
欧美一区二区三区喷汁尤物|
日韩午夜电影在线观看|
久久品道一品道久久精品|
欧美国产一区视频在线观看|
国产精品国模大尺度视频|
亚洲女同ⅹxx女同tv|
丝袜亚洲另类欧美|
国产激情91久久精品导航|
91麻豆免费视频|
精品蜜桃在线看|
日韩理论片在线|
六月丁香综合在线视频|
av成人免费在线|
精品日本一线二线三线不卡|
亚洲精品亚洲人成人网在线播放|
日本成人在线不卡视频|
成人av小说网|
日韩欧美www|
亚洲乱码日产精品bd|
奇米影视7777精品一区二区|
成人aa视频在线观看|
欧美日韩二区三区|
国产女人18水真多18精品一级做
|
国产精品1024|
欧美电影影音先锋|
亚洲免费在线视频|
国产69精品久久久久777|
欧美日韩国产天堂|
亚洲柠檬福利资源导航|
国产精一品亚洲二区在线视频|
欧美三级资源在线|
亚洲日本一区二区三区|
精东粉嫩av免费一区二区三区|
91在线观看污|
国产欧美视频一区二区三区|
日韩av电影免费观看高清完整版|
精品精品欲导航|
亚洲九九爱视频|
国内精品在线播放|
日韩一级片网址|
日日夜夜精品视频免费|
欧美日韩国产bt|
香蕉av福利精品导航|
97久久精品人人做人人爽50路|
国产午夜亚洲精品理论片色戒|
三级久久三级久久久|
欧美日韩精品二区第二页|
亚洲一区二区三区四区的|
91视频xxxx|
亚洲一区二区三区影院|
欧美久久久一区|
久久狠狠亚洲综合|
久久九九影视网|
99久久精品国产一区二区三区|
国产精品国产三级国产三级人妇|
99热精品国产|
五月婷婷久久综合|
精品美女被调教视频大全网站|
精品制服美女久久|
国产日韩欧美电影|
色又黄又爽网站www久久|
天天综合天天综合色|
欧美一级高清大全免费观看|
国内精品视频一区二区三区八戒|
久久新电视剧免费观看|
www.久久精品|
丝袜美腿亚洲色图|
久久美女高清视频|
欧美中文一区二区三区|
久久精品国产久精国产爱|
国产精品私人影院|
一区二区三区自拍|
欧美成人一区二区三区片免费|
国产suv精品一区二区6|
亚洲一区二区三区自拍|
国产日韩在线不卡|
欧美一卡二卡三卡|
91丨九色丨黑人外教|
九九九久久久精品|
亚洲一区二区在线观看视频|
精品999在线播放|
欧美三级中文字幕在线观看|
国产91精品入口|
另类小说欧美激情|
亚洲一区二区三区四区不卡|
国产偷国产偷精品高清尤物|
欧美精品一级二级三级|
91在线视频观看|
国产成a人无v码亚洲福利|
日韩av一级片|
一区二区三区精品视频|
欧美国产精品久久|
久久蜜臀中文字幕|
亚洲精品在线观看视频|
欧美一区二区在线不卡|
91丝袜国产在线播放|
国产91精品久久久久久久网曝门|
狠狠色狠狠色合久久伊人|
日韩高清不卡一区二区三区|
亚洲福中文字幕伊人影院|
亚洲精品视频在线|
精品不卡在线视频|
在线观看免费一区|
成人精品视频一区二区三区尤物|
美女免费视频一区二区|
日本美女视频一区二区|
亚洲18女电影在线观看|
亚洲电影激情视频网站|
一区二区在线观看免费|
亚洲精品欧美二区三区中文字幕|
中文字幕在线视频一区|
中文字幕av一区 二区|
久久久天堂av|
国产亚洲综合色|
一区二区三区在线免费视频|
国产欧美一区二区精品婷婷
|
国产亚洲污的网站|
久久亚洲捆绑美女|
国产精品夫妻自拍|
亚洲高清不卡在线|
天天操天天干天天综合网|
日欧美一区二区|
韩国女主播成人在线|
久久精品国产网站|
成人av网站在线观看免费|
久久九九全国免费|
国产精品国产a|
亚洲午夜视频在线|
精品一区二区三区不卡
|
精品国产乱码久久久久久浪潮
|
欧美一级生活片|
亚洲天天做日日做天天谢日日欢|
五月激情丁香一区二区三区|