
2025年最新推理大模型API參數(shù)與性能詳解:通義千問(wèn)Max、豆包1.5 Pro、混元Lite深度對(duì)比
LLM大模型基本選擇以Decoder模塊堆疊N層組成的網(wǎng)絡(luò)結(jié)構(gòu)。
例如羊駝系列 LLaMA 大模型,按照參數(shù)量的大小有四個(gè)型號(hào):LLaMA-7B、LLaMA-13B、LLaMA-33B 與 LLaMA-65B。這里的 B 是 billion 的縮寫(xiě),指代模型的參數(shù)規(guī)模。故最小的模型 7B 包含 70 億個(gè)參數(shù),而最大的一款 65B 則包含 650 億個(gè)參數(shù)。
我們以大模型的最基本結(jié)構(gòu) Transformer 為例,首先來(lái)看一下參數(shù)量是怎么算出來(lái)的。
transformer 由 L 個(gè)相同的層組成,每個(gè)層分為兩個(gè)部分:self-attention 和 MLP 層。其中 self-attention 塊,不管用的是 self-attention 還是 multi-head self-attention,參數(shù)量計(jì)算并不影響。因?yàn)樵谳斎霑r(shí),對(duì) Q,K,V 三個(gè)向量都進(jìn)行了線性變換,只是 multi-head self-attention 會(huì)對(duì)隱藏層 h 切分成 head 份而已。那么 self-attention 塊的參數(shù)量為:4h2+4h。MLP 塊由 2 個(gè)線性層組成,這兩個(gè)層的 shape 是先將維度 h 映射到 4h,然后第二個(gè)線性層再將維度從 4h 映射回 h。self-attention 和 MLP 塊各有一個(gè) layer normalization,包含了 2 個(gè)可訓(xùn)練的參數(shù):尺度縮放參數(shù) gamma,和平移參數(shù) beta,形狀都是 [h]。那么這兩個(gè) layer normalization 參數(shù)量為:4h。那么,每個(gè) transformer 層的參數(shù)量就為:12h2+13h。除此之外,還有輸入部分的詞嵌入?yún)?shù),詞向量的維度為 h,假設(shè)詞表大小 vocab size 為 V。那么詞嵌入的參數(shù)量為 Vh,而輸出層的權(quán)重矩陣通常與輸入的詞嵌入矩陣參數(shù)是共享的,不會(huì)引入額外的參數(shù)量。關(guān)于位置編碼,這部分參數(shù)比較少,可以忽略。其中,如果采用可訓(xùn)練的位置編碼,那么參數(shù)量為 N*h,N 是最大序列長(zhǎng)度,例如 chatgpt 的 4k。如果采用的是相對(duì)位置編碼,如旋轉(zhuǎn)編碼 RoPE 或者 AliBi,則這部分就沒(méi)有可訓(xùn)練的參數(shù)。綜上所述,L 層的 transformer 模型的總參數(shù)量為 L(12h2+13h)+Vh,當(dāng)隱藏維度 h 較大時(shí),可以忽略一次項(xiàng),模型參數(shù)量可以近似為 12Lh2。
綜上所述,L 層的 transformer 模型的總參數(shù)量為 L(12h2+13h)+Vh,當(dāng)隱藏維度 h 較大時(shí),可以忽略一次項(xiàng),模型參數(shù)量可以近似為 12Lh2。

如何計(jì)算大語(yǔ)言模型所需的顯存?

4B是因?yàn)?2位的浮點(diǎn)精度會(huì)占4個(gè)字節(jié)內(nèi)存;
下面以運(yùn)行16位精度的 Llama 70B 模型所需的 GPU 內(nèi)存為例套用公式:
該模型有 700 億參數(shù)。
M = (700 ? 4) / (32 / 16) ? 1.2 ≈ 140 * 1.2 = 168GB

我們以 LLaMA-7B 為例,這個(gè)大模型參數(shù)量約為 70 億,假設(shè)每個(gè)參數(shù)都是一個(gè) fp32,即 4 個(gè)字節(jié),總字節(jié)就是 280 億字節(jié),則 280 億字節(jié)/1024(KB)/1024(MB)/1024(GB) = 26.7GB,當(dāng)然這是原始的理論值,我們?cè)偻驴础R驗(yàn)閷?shí)際存儲(chǔ) weight 權(quán)重參數(shù)會(huì)存 fp16,所以模型大小繼續(xù)減半為 13.35GB。但是部分 layer norm 等數(shù)據(jù)會(huì)保留源格式 fp32,因此實(shí)際會(huì)稍微有所增加到 13.5GB 左右,我們從開(kāi)源的 LLaMA-7B 的實(shí)際的存儲(chǔ)結(jié)果來(lái)看,是符合上面的計(jì)算的:

相信在介紹這部分后,大家應(yīng)該對(duì)LLM大模型的模型結(jié)構(gòu)、參數(shù)量、精度、存儲(chǔ)空間更具象的認(rèn)識(shí)。

模型微調(diào)通常來(lái)說(shuō),雖然可以提高任務(wù)的效果,但通常來(lái)說(shuō),微調(diào)的成本遠(yuǎn)大于提示詞調(diào)優(yōu),模型微調(diào)相對(duì)來(lái)說(shuō)復(fù)雜性高、資源需求大而且成本高。
使用 OpenAI API 進(jìn)行快速工程的最佳實(shí)踐:
https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-the-openai-api

prompt:結(jié)構(gòu)化、具體化、清晰化
在微調(diào)之前先嘗試優(yōu)化prompt和fewshot來(lái)探索模型能力邊界,是否能解決現(xiàn)有問(wèn)題,合適的base-model(類型和size)的選取,有了明確的效果保證后,再微調(diào)得到更加穩(wěn)定的效果輸出和更小的size部署等需求。
有這么一句話在業(yè)界廣泛流傳:數(shù)據(jù)和特征決定了機(jī)器學(xué)習(xí)的上限,而模型和算法只是逼近這個(gè)上限而已。所以數(shù)據(jù)的構(gòu)造至關(guān)重要,需要建立對(duì)生成數(shù)據(jù)質(zhì)量的把控。
在chatgpt出來(lái)后,業(yè)界最開(kāi)始基于pretrain模型上做sft最受關(guān)注的工作之一,是self-instruct,蒸餾chatgpt得到高質(zhì)量的sft數(shù)據(jù),很多后來(lái)的生成sft數(shù)據(jù)的工作是以這個(gè)工作為基礎(chǔ)。核心思想是通過(guò)建立種子集,然后prompt模型輸出目標(biāo)格式的數(shù)據(jù),通過(guò)后置ROUGE-L等篩選方法去重,不斷的加入種子集合,來(lái)提升產(chǎn)出數(shù)據(jù)的多樣性和質(zhì)量。
比如qwen2.5-7b是pretrain后的模型,qwen2.5-7b-instrcut是基于qwen2.5-7b做了通用的SFT微調(diào)后得到。

生成指令數(shù)據(jù)的流程由四個(gè)步驟組成。1)指令生成,2)識(shí)別指令是否代表分類任務(wù),3)用輸入優(yōu)先或輸出優(yōu)先的方法生成實(shí)例,4)過(guò)濾低質(zhì)量數(shù)據(jù)。

關(guān)注數(shù)據(jù)集的質(zhì)量和豐富度:

我們提及微調(diào)更多是在通用SFT訓(xùn)練好的模型基礎(chǔ)上再做領(lǐng)域的微調(diào)。
可以更省事的選擇俄把生成好的數(shù)據(jù),直接丟給模型去訓(xùn)練驗(yàn)證最后的效果;但是如果朝著長(zhǎng)期做效果迭代的方向,我們需要對(duì)生成的數(shù)據(jù)是否符合預(yù)期,有更現(xiàn)驗(yàn)的判斷,這也能夠?yàn)楹罄m(xù)如果微調(diào)后模型不符合預(yù)期的情況下,來(lái)有debug的依據(jù)和方法。
一方面是人來(lái)check數(shù)據(jù)質(zhì)量,另外一方面是可以通過(guò)規(guī)則或者LLM大模型來(lái)做后置的數(shù)據(jù)驗(yàn)證,讓模型來(lái)打分并給出推理過(guò)程等方式。數(shù)據(jù)量的問(wèn)題上,跟數(shù)據(jù)類型的分布關(guān)系很大,需要產(chǎn)生不同任務(wù)下的高質(zhì)量數(shù)據(jù),更需要關(guān)注數(shù)據(jù)分布。
基于已有開(kāi)源大模型進(jìn)行微調(diào)訓(xùn)練,如果采用預(yù)訓(xùn)練的方式對(duì)模型的所有參數(shù)都進(jìn)行訓(xùn)練微調(diào),由于現(xiàn)有的開(kāi)源模型參數(shù)量都十分巨大。PEFT (Parameter-Efficient Fine-Tuning),即對(duì)開(kāi)源預(yù)訓(xùn)練模型的所有參數(shù)中的一小部分參數(shù)進(jìn)行訓(xùn)練微調(diào),最后輸出的結(jié)果和全參數(shù)微調(diào)訓(xùn)練的效果接近。
LoRA(論文:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS),該方法的核心思想就是通過(guò)低秩分解來(lái)模擬參數(shù)的改變量,從而以極小的參數(shù)量來(lái)實(shí)現(xiàn)大模型的間接訓(xùn)練。(秩是矩陣中最長(zhǎng)的獨(dú)立行數(shù)或列數(shù))

神經(jīng)網(wǎng)絡(luò)包含很多全連接層,其借助于矩陣乘法得以實(shí)現(xiàn),然而,很多全連接層的權(quán)重矩陣都是滿秩的。因此,論文的作者認(rèn)為權(quán)重更新的那部分參數(shù)矩陣盡管隨機(jī)投影到較小的子空間,仍然可以有效的學(xué)習(xí),可以理解為針對(duì)特定的下游任務(wù)這些權(quán)重矩陣就不要求滿秩。
在涉及到矩陣相乘的模塊,在旁邊增加一個(gè)新的通路,通過(guò)前后兩個(gè)矩陣A,B相乘,第一個(gè)矩陣A負(fù)責(zé)降維,第二個(gè)矩陣B負(fù)責(zé)升維,中間層維度為r。其中,r<<d,r是矩陣的秩,這樣矩陣計(jì)算就從d x d變?yōu)閐 x r + r x d,參數(shù)量減少很多。將原部分跟新增的通路兩部分的結(jié)果加起來(lái)作為最終的結(jié)果(兩邊通路的輸入跟輸出維度是一致的)。
此外,Transformer的權(quán)重矩陣包括Attention模塊里用于計(jì)算query, key, value的Wq,Wk,Wv以及多頭attention的Wo,以及MLP層的權(quán)重矩陣,LoRA只應(yīng)用于Attention模塊中的4種權(quán)重矩陣,而且通過(guò)消融實(shí)驗(yàn)發(fā)現(xiàn)同時(shí)調(diào)整 Wq 和 Wv 會(huì)產(chǎn)生最佳結(jié)果。
instructGPT提出的SFT和RLHF的流程圖,在SFT模型的基礎(chǔ)做強(qiáng)化學(xué)習(xí)的訓(xùn)練往往會(huì)提升模型的表現(xiàn)。

我們需要一個(gè)模型來(lái)定量評(píng)判模型輸出的回答在人類看來(lái)是否質(zhì)量不錯(cuò),即輸入 [提示(prompt),模型生成的回答] ,獎(jiǎng)勵(lì)模型輸出一個(gè)能表示回答質(zhì)量的標(biāo)量數(shù)字。
1.把大量的prompt(Open AI使用調(diào)用GPT-3用戶的真實(shí)數(shù)據(jù))輸入給第一步得到的語(yǔ)言模型,對(duì)同一個(gè)問(wèn)題,可以讓一個(gè)模型生成多個(gè)回答,也可以讓不同的微調(diào)(fine-tune)版本回答。
2.讓標(biāo)注人員對(duì)同一個(gè)問(wèn)題的不同回答排序,實(shí)驗(yàn)發(fā)現(xiàn)發(fā)現(xiàn)不同的標(biāo)注員,打分的偏好會(huì)有很大的差異,而這種差異就會(huì)導(dǎo)致出現(xiàn)大量的噪聲樣本。排序的話能獲得大大提升一致性。
3.這些不同的排序結(jié)果會(huì)通過(guò)某種歸一化的方式變成定量的數(shù)據(jù)丟給模型訓(xùn)練,從而獲得一個(gè)獎(jiǎng)勵(lì)模型。也就是一個(gè)裁判員。
由于PPO需要4個(gè)模型加載,2個(gè)推理,2個(gè)訓(xùn)練,成本較高;而DPO只需要兩個(gè)模型,一個(gè)推理一個(gè)訓(xùn)練。
開(kāi)始訓(xùn)練時(shí),reference model和policy model都是同一個(gè)模型,只不過(guò)在訓(xùn)練過(guò)程中reference model不會(huì)更新權(quán)重。

目標(biāo)函數(shù):

梯度:

動(dòng)態(tài)因子:

因此DPO的優(yōu)化目的可以理解為通過(guò)訓(xùn)練, 最大化正樣本上的獎(jiǎng)勵(lì) 和負(fù)樣本上的獎(jiǎng)勵(lì)兩者的間距(margin)。 因?yàn)閰⒖寄P褪遣粍?dòng)的,因此進(jìn)一步可以理解為提升模型在正樣本上的概率(優(yōu)化模型在正樣本上的概率 大于 參考模型在正樣本上的概率), 降低模型在負(fù)樣本上的概率(優(yōu)化模型在負(fù)樣本上的概率 小于 參考模型在負(fù)樣本上的概率)。
當(dāng)我們的任務(wù)能夠產(chǎn)出正負(fù)樣例對(duì)的時(shí)候,我們可以通過(guò)這種方式來(lái)微調(diào)模型提升表現(xiàn)。來(lái)讓模型從正負(fù)樣例中學(xué)到好的為什么好,差的為什么差,往往能夠得到比SFT更優(yōu)的效果。它和SFT的區(qū)別在于,SFT只能告訴模型正例而沒(méi)有負(fù)例。
{
"messages": [
{
"role": "user",
"content": "你能幫我寫(xiě)一篇關(guān)于環(huán)境保護(hù)的文章嗎?"
}
],
"chosen": {
"role": "assistant",
"content": "當(dāng)然可以。環(huán)境保護(hù)是一個(gè)非常重要的話題,我們可以從減少碳排放、保護(hù)森林和水資源、推廣可再生能源等方面來(lái)入手。你想要文章的具體方向和字?jǐn)?shù)是多少呢?"
},
"rejected": {
"role": "assistant",
"content": "可以的,環(huán)境保護(hù)是一個(gè)重要的話題。"
}
}介紹完一些初步的理論基礎(chǔ)后,這部分主要來(lái)講大模型的具體微調(diào)流程和具體的操作細(xì)節(jié)。
因?yàn)榧瘓F(tuán)內(nèi)外關(guān)于模型微調(diào)的工具也很豐富,這里只給出我們團(tuán)隊(duì)常使用的平臺(tái)和框架,以及微調(diào)的實(shí)操流程。
本文涉及幾個(gè)內(nèi)部平臺(tái)說(shuō)明:
外部平臺(tái):
https://github.com/hiyouga/LLaMA-Factory
這里給出一個(gè)微調(diào)的實(shí)踐簡(jiǎn)化流程如下:
idealab 幫助文檔一共接入了包含文生文、多模態(tài)、向量化、bing搜索、代碼生成等類別的大模型共計(jì)近50個(gè),涵蓋了包含azure openai gpt系列、dalle,阿里通義千問(wèn)、淘天星辰,谷歌vertexAI系列等主流模型。

調(diào)用的方式:
-H "Content-Type:application/json"
-H 'X-AK: xxxx'
-d '{
"model": "gpt-3.5-turbo",
"prompt": "你是誰(shuí)"
}'whale平臺(tái)上提供了豐富的開(kāi)源模型部署,根據(jù)調(diào)試或批量調(diào)用的需求,可以分成訪問(wèn)免費(fèi)部署模型和獨(dú)立部署模型兩部分。整體體驗(yàn)還是比較便捷,對(duì)大模型部署支持的比較好,比較推薦。


在部署模型之后,除了whale的UI界面去調(diào)用,也支持sdk調(diào)用whale服務(wù)代碼:LLMChatStreamDemo.py,核心代碼如下:
from whale import TextGeneration, VipServerLocator
from whale.util import Timeout
response = TextGeneration.chat(
model="Qwen-72B-Chat-Pro",
messages=msgs,
stream=True,
temperature=1.0,
max_tokens=2000,
timeout=Timeout(60, 20),
top_p=0.8,
extend_fields=extend_fields)當(dāng)我們通過(guò)上述方式生成好自己的訓(xùn)練集后,就需要開(kāi)始微調(diào)模型了。
針對(duì)小任務(wù)/小模型,可以在自己開(kāi)發(fā)機(jī)上微調(diào)即可,推薦使用LLaMA-Factory微調(diào)框架;對(duì)于依賴較大資源或者數(shù)據(jù)量較大的情況,可以使用TuningFactory框架,結(jié)合星云平臺(tái)做模型的訓(xùn)練。
LLaMA-Factory代碼庫(kù):https://github.com/hiyouga/LLaMA-Factory

lora微調(diào),scripts/sft_lora.sh

WORLD_SIZE=8
LR=1e-5
# 實(shí)驗(yàn)項(xiàng)目名,需要在星云實(shí)驗(yàn)管理中創(chuàng)建實(shí)驗(yàn)或者選擇你有權(quán)限的實(shí)驗(yàn)
# 如果不指定,并且開(kāi)啟了report_to=ml_tracker,會(huì)默認(rèn)使用 你工號(hào)_default 作為實(shí)驗(yàn)項(xiàng)目名
# TRACKER_PROJECT_NAME=""
# if you want to train based on lora ckpt, please set LORA_CKPT and set MODEL_NAME to pretrained model
# LORA_CKPT="your_nebula_project.your_lora_ckpt/version=your_version/ckpt_id=checkpoint-xxx"
# LORA_CKPT="digital_live_chat.Google-RAG-7B/version=v1.4/ckpt_id=checkpoint-330"
LORA_CKPT="digital_live_chat.sft_model_whale/version=v20.26/ckpt_id=checkpoint-210"
args="--stage dpo \
--model_name_or_path=$MODEL_NAME \
--do_train \
--do_eval \
--val_size 0.05 \
--file_name=${INPUT} \
--ranking \
--system=system \
--prompt=input \
--chosen=pos \
--rejected=neg \
--deepspeed=scripts/ds_zero3.json \
--template=$PROMPT_TEMPLATE \
--finetuning_type lora \
--gradient_checkpointing True \
--lora_target=o_proj,q_proj,k_proj,v_proj,up_proj,gate_proj,down_proj \
--lora_rank=64 \
--lora_alpha=16 \
--output_dir=local/tmp/ckpt_save_path/ \
--overwrite_cache \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--num_train_epochs 20 \
--learning_rate=$LR \
--cutoff_len=2048 \
--preprocessing_num_workers=8 \
--dataloader_num_workers=4 \
--plot_loss \
--report_to=none \
--pref_beta=0.2 \
--pref_ftx=0.5 \
--bf16"在這里可以指定訓(xùn)練的lora checkpoint到指定的項(xiàng)目存儲(chǔ)路徑,后續(xù)可以在whale平臺(tái)直接調(diào)用,非常方便。
訓(xùn)練完成結(jié)果和統(tǒng)計(jì)圖表如下:


挑選eval集合上loss最低的checkpoint作為最優(yōu)的模型。
在模型配置處可以搜索上一步中生成好的訓(xùn)練模型,選擇部署。

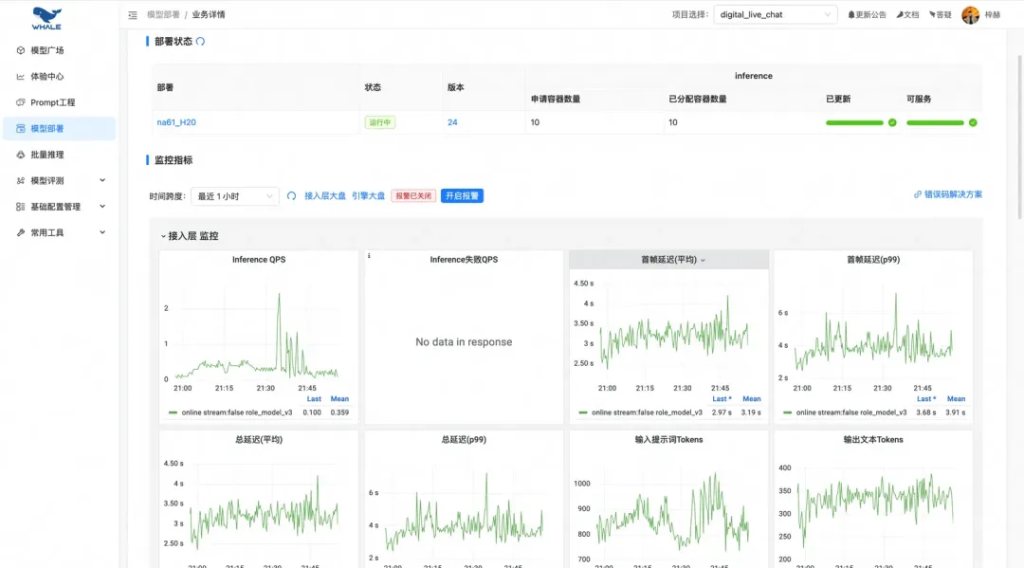
自動(dòng)化的流量和模型性能監(jiān)控報(bào)表:
可視化的對(duì)話調(diào)試界面:

在模型的推理加速上,探索過(guò)以下三種whale平臺(tái)上配置加速的手段:



以Qwen2.5-7B為例,測(cè)試不同加速方法帶來(lái)的提升:

平臺(tái)自動(dòng)支持:推理引擎會(huì)根據(jù)請(qǐng)求自動(dòng)湊batch推理;支持多并發(fā)請(qǐng)求:

模型微調(diào)和部署完成后,往往需要在我們的測(cè)試集上查看模型效果,這依賴你需要有:
我們需要預(yù)先定義一個(gè)指標(biāo)來(lái)判斷模型的效果好壞,對(duì)于指標(biāo)定義不明確的任務(wù),盡量細(xì)化它的標(biāo)準(zhǔn)。可以讓人工去評(píng)估,也可以讓大模型自動(dòng)評(píng)估。
經(jīng)過(guò)上述步驟有了新的模型效果后,除了考慮算法工程(耗時(shí)、部署資源、模型并發(fā))外,效果上需要考慮是否能推送上線的關(guān)注點(diǎn):
從指標(biāo)和case分析中,發(fā)現(xiàn)并定位問(wèn)題;從數(shù)據(jù)構(gòu)造中不斷去完善更高質(zhì)量的數(shù)據(jù),探索更強(qiáng)模型和更優(yōu)的微調(diào)方法。
全是goodcase是個(gè)理想的情況,實(shí)驗(yàn)結(jié)果往往會(huì)存在不符合預(yù)期或者蹺蹺板的問(wèn)題,這個(gè)時(shí)候需要思考是模型能力的問(wèn)題、還是數(shù)據(jù)構(gòu)造上有考慮不周的情況等。不同的任務(wù)/base模型/數(shù)據(jù)質(zhì)量/訓(xùn)練參數(shù)和數(shù)據(jù)集都有關(guān),還是得結(jié)合具體場(chǎng)景來(lái)做分析和優(yōu)化。一般經(jīng)驗(yàn)來(lái)講提升數(shù)據(jù)質(zhì)量是最直接有效的方法,在這個(gè)基礎(chǔ)上再探索強(qiáng)化學(xué)習(xí)、推理模型等進(jìn)一步解決目標(biāo)問(wèn)題的手段。
文章轉(zhuǎn)載自:大模型微調(diào)知識(shí)與實(shí)踐分享
2025年最新推理大模型API參數(shù)與性能詳解:通義千問(wèn)Max、豆包1.5 Pro、混元Lite深度對(duì)比

2025年五大AI大模型API基礎(chǔ)參數(shù)、核心性能:Gemini 2.5、DeepSeek R1、Claude 3.7

2025年五大AI大模型API價(jià)格對(duì)比:Gemini 2.5、DeepSeek R1、Claude 3.7

國(guó)產(chǎn)精品大模型API價(jià)格對(duì)比:通義千問(wèn) Max、字節(jié)跳動(dòng)Doubao 1.5 pro 256k、DeepSeek V3

REST API:關(guān)鍵概念、最佳實(shí)踐和優(yōu)勢(shì)

大模型API亂斗,基礎(chǔ)參數(shù)、核心性能:Grok3、deepseek R1、ChatGPT 4o

3大AI語(yǔ)言大模型API價(jià)格的區(qū)別:ChatGPT 4o、百度千帆 ERNIE 4.0、阿里通義千問(wèn) Max

從頭開(kāi)始構(gòu)建 GPT 風(fēng)格的 LLM 分類器
3大AI語(yǔ)言大模型API基礎(chǔ)參數(shù)、核心性能的區(qū)別:ChatGPT 4o、百度千帆 ERNIE 4.0、阿里通義千問(wèn) Max
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)