
如何使用Requests-OAuthlib實現OAuth認證
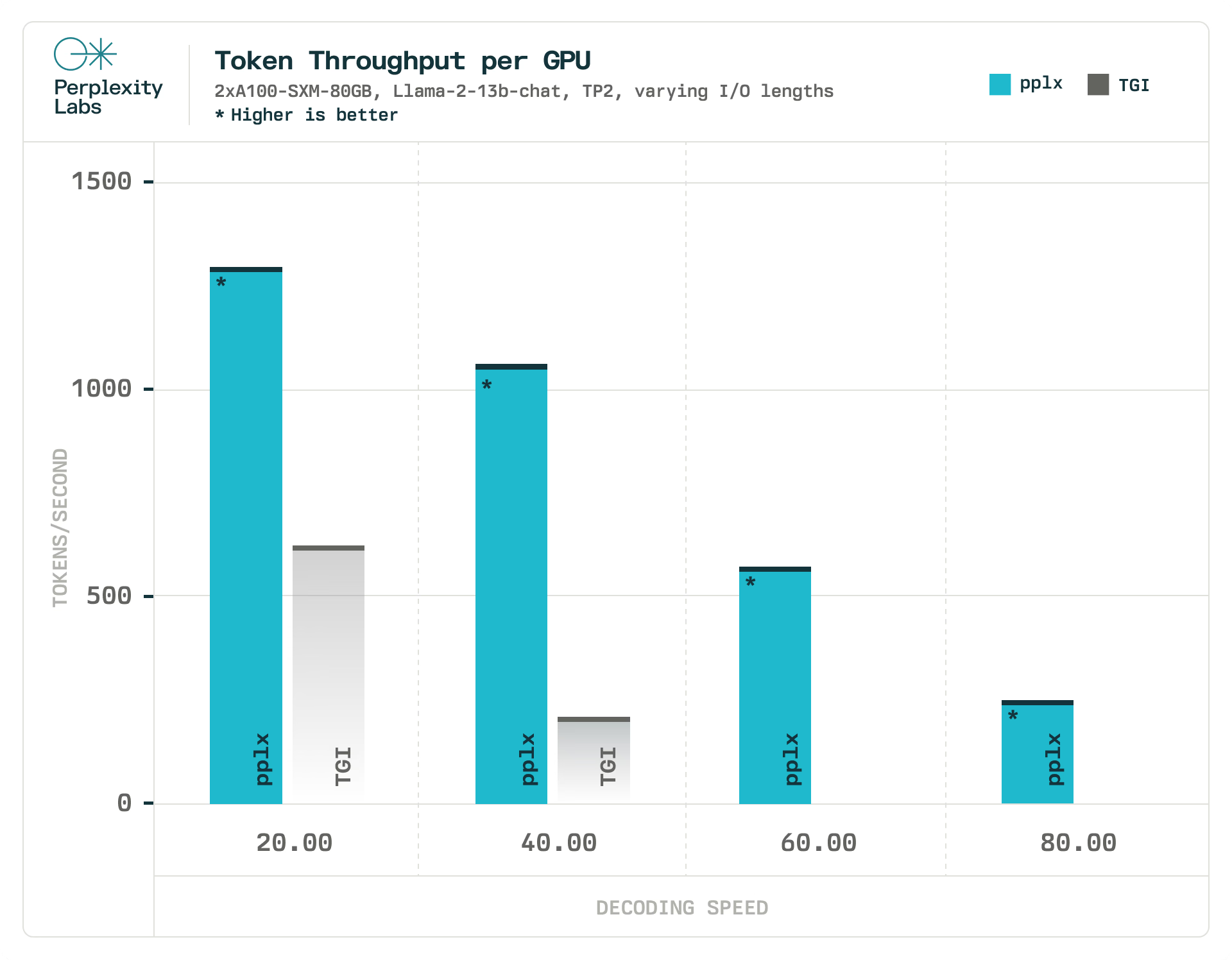
使用相同的實驗設置,我們將 pplx-api 的最大吞吐量與 TGI 進行了比較,將解碼速度作為延遲約束。在我們的實驗中,pplx-api 處理令牌的速度比 TGI 快1.90 倍到 6.75 倍,而 TGI 完全無法滿足我們更嚴格的延遲約束(每秒60和80 個 令牌)。我們在與評估 pplx-api 相同的硬件和負載條件下評估 TGI。由于我們無法控制它們的硬件和負載因素,因此無法將此指標與 Replicate 和 Anyscale 進行比較。
作為參考,人類的平均閱讀速度為 5 個令牌/秒,這意味著 pplx-api能夠以比人類閱讀速度更快的速度提供服務。
要實現這些延遲數字需要最先進的軟件和硬件的結合。
由 NVIDIA A100 GPU 提供支持的AWS p4d 實例為擴展具有一流時鐘速度的 GPU 奠定了最具成本效益和最可靠的選擇基礎。
為了讓軟件充分利用此硬件,我們運行 NVIDIA 的 TensorRT-LLM,這是一個加速和優化 LLM 推理的開源庫。TensorRT-LLM 封裝了 TensorRT 的深度學習編譯器,并包含為 FlashAttention 和掩蔽多頭注意力 (MHA) 的尖端實現而制作的最新優化內核,用于 LLM 模型執行的上下文和生成階段。
從這里開始,AWS 的主干及其與 Kubernetes 的強大集成使我們能夠彈性擴展到數百個 GPU 以上,并最大限度地減少停機時間和網絡開銷。
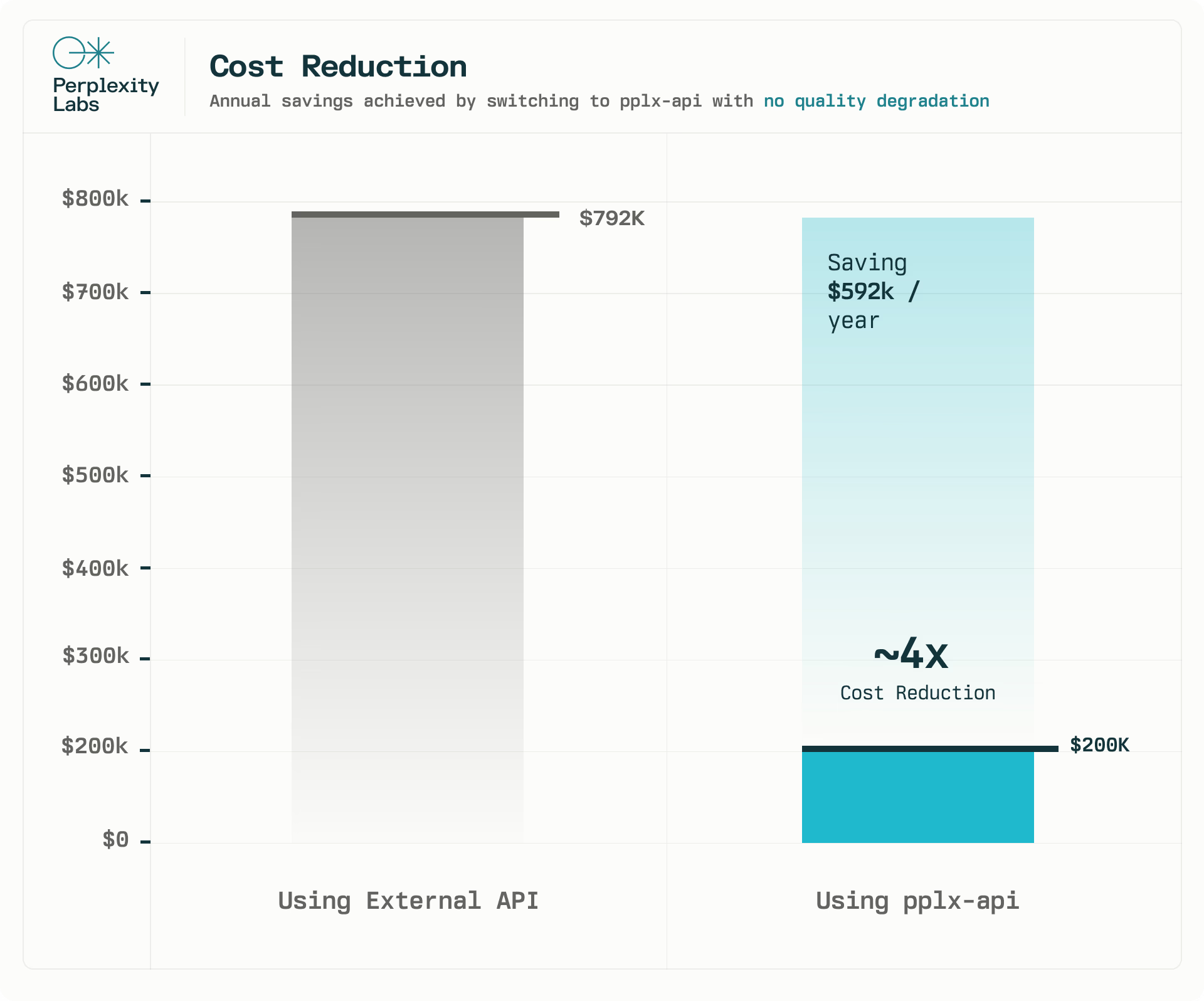
我們的 API 已經為 Perplexity 的核心產品功能之一提供支持。只需將一個功能從外部 API 切換到 pplx-api,每年即可節省 62 萬美元,成本大約降低了4 倍。我們運行了 A/B 測試并監控了基礎設施指標,以確保質量不會下降。在 2 周的時間里,我們在 A/B 測試中沒有觀察到統計學上的顯著差異。此外,pplx-api 可以承受每天超過一百萬個請求的負載,每天總共處理近 10 億個令牌。
這次初步探索的結果非常令人鼓舞,我們期待 pplx-api 能隨著時間的推移為我們的更多產品功能提供支持。
我們還使用 pplx-api 為Perplexity Labs提供支持,這是我們的模型游樂場,為各種開源模型提供服務。
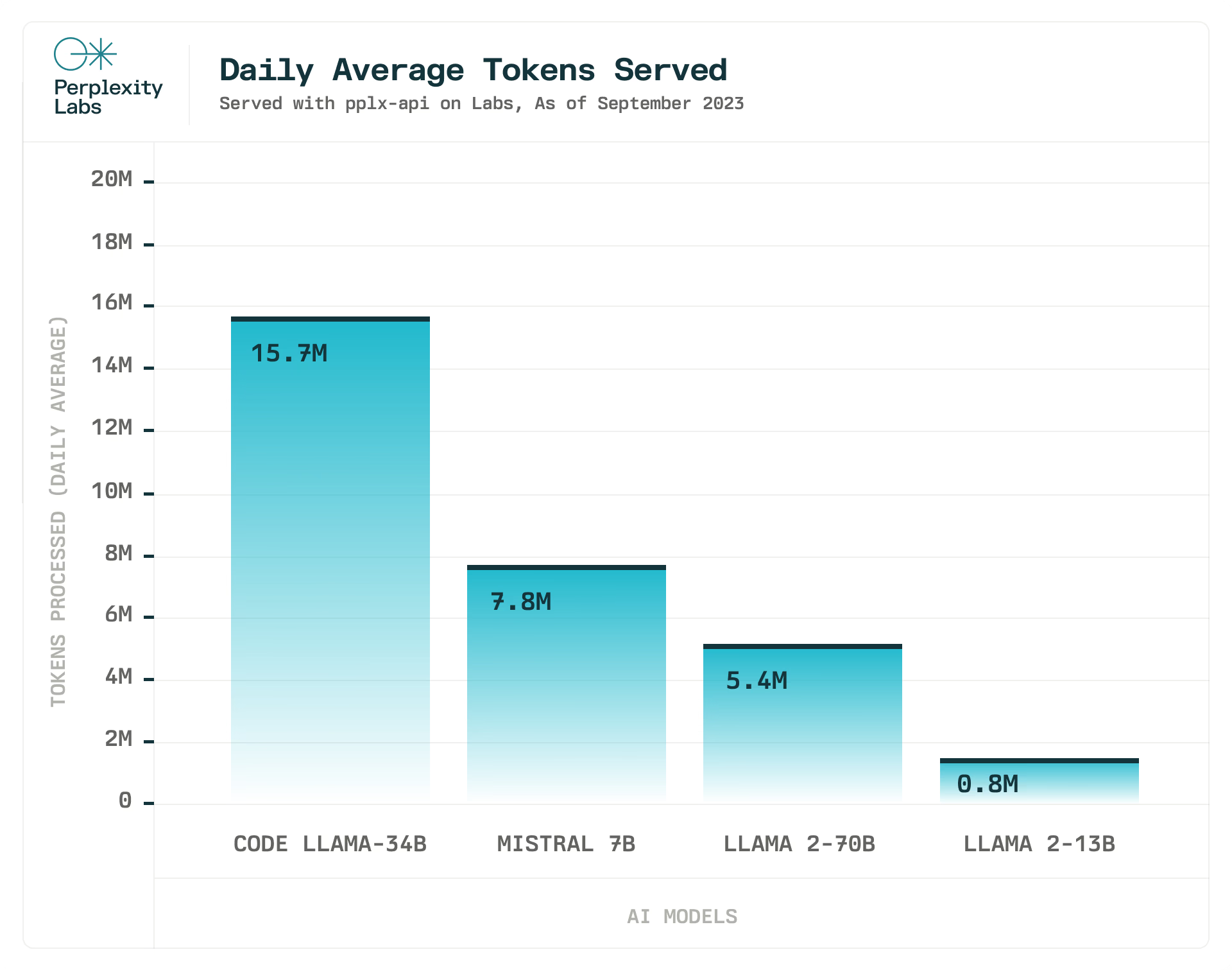
Perplexity團隊致力于提供最新的先進開源 LLM。我們在 Mistral 7B、Code Llama 34b 和所有 Llama 2 模型發布后幾個小時內就將它們集成在一起,并計劃在推出更多功能更強大的開源 LLM 時這樣做。
您可以使用 HTTPS 請求訪問 pplx-api REST API。pplx-api 身份驗證涉及以下步驟:
Authorization在每個 pplx-api 請求的標頭中將 API 密鑰作為承載令牌發送。以下示例中,PERPLEXITY_API_KEY是使用上述指令生成的與密鑰綁定的環境變量。CURL 用于提交聊天完成請求。
curl -X POST \
--url https://api.perplexity.ai/chat/completions \
--header 'accept: application/json' \
--header 'content-type: application/json' \
--header "Authorization: Bearer ${PERPLEXITY_API_KEY}" \
--data '{
"model": "mistral-7b-instruct",
"stream": false,
"max_tokens": 1024,
"frequency_penalty": 1,
"temperature": 0.0,
"messages": [
{
"role": "system",
"content": "Be precise and concise in your responses."
},
{
"role": "user",
"content": "How many stars are there in our galaxy?"
}
]
}'content-type: application/json{
"id": "3fbf9a47-ac23-446d-8c6b-d911e190a898",
"model": "mistral-7b-instruct",
"object": "chat.completion",
"created": 1765322,
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": " The Milky Way galaxy contains an estimated 200-400 billion stars.."
},
"delta": {
"role": "assistant",
"content": " The Milky Way galaxy contains an estimated 200-400 billion stars.."
}
}
],
"usage": {
"prompt_tokens": 40,
"completion_tokens": 22,
"total_tokens": 62
}
}from openai import OpenAI
YOUR_API_KEY = "INSERT API KEY HERE"
messages = [
{
"role": "system",
"content": (
"You are an artificial intelligence assistant and you need to "
"engage in a helpful, detailed, polite conversation with a user."
),
},
{
"role": "user",
"content": (
"Count to 100, with a comma between each number and no newlines. "
"E.g., 1, 2, 3, ..."
),
},
]
client = OpenAI(api_key=YOUR_API_KEY, base_url="https://api.perplexity.ai")
# demo chat completion without streaming
response = client.chat.completions.create(
model="mistral-7b-instruct",
messages=messages,
)
print(response)
# demo chat completion with streaming
response_stream = client.chat.completions.create(
model="mistral-7b-instruct",
messages=messages,
stream=True,
)
for response in response_stream:
print(response)Perplexity目前支持Mistral 7B、Llama 13B、Code Llama 34B、Llama 70B,并且 API 方便地與 OpenAI 客戶端兼容,以便于輕松與現有應用程序集成。





