
墨西哥支付方式:是什么?
張小珺:對于 Perplexity 的出現,國外 Google、國內百度這類傳統搜索公司有什么樣的應對策略嗎?
Guangmi Li:Google 出了一個 SGE 產品,包括 Overview,但好像口碑不是很好。百度好像還沒有動作,國內好像有一個秘塔。但國內有個很現實的問題是內容是割裂的,因為中國過早的進入了移動互聯網時代,小紅書的內容很難檢索、微信的內容也很難檢索,甚至知乎的都不一定那么開放。高質量內容的有效性是比較少的。百度搜索出來的首頁里,百度自己的內容占很大比例,所以中國的內容的割裂性和海外的這種 PC 形態主導模式的區別是比較大的。

張小珺:中國的 Perplexity 更有可能是巨頭的菜,還是創業公司的菜?
Guangmi Li:我個人感覺肯定是巨頭的菜。其實字節一年前就應該做一個這種產品去打百度,信息流就是對百度廣告的一個很大的搶份額機會,只是感覺很多人還沒意識到這是不是一個 PMF,有的人覺得 Perplexity 也還沒有完全 PMF,以及長期面臨大模型公司本身的競爭。
張小珺:Perplexity 今天的估值和國內的月之暗面是一樣,都是 30 億美金,這意味著兩家公司是除了 ChatGPT 以外全球并駕齊驅的明星 AI 公司。他們兩個在模型和產品形態上,你覺得本質區別有哪些?
Guangmi Li:月之暗面還是基礎大模型公司,但是他們的產品做的特別好。Kimi Chat 其實也抓了很多知識工作者的心智,用戶畫像和 Perplexity 也比較接近,有重合。
張小珺:Kimi 是一個從大模型到應用的公司,而 Perplexity 是一個從應用到模型的公司,先后順序其實是不一樣的。
Guangmi Li:應用公司是很難往下做模型的,只是做基礎的模型的一些調優。我感覺中國的模型公司是必須得往上做應用的,所以美國出來哪些好的 use case ,我覺得大家都會借鑒的。
張小珺:如果我們畫一個腦圖,在海外市場,Perplexity 這類 30 億美元估值的 AI native 的公司在第一梯隊。那第二梯隊、第三梯隊的 AI 創業公司有哪些?
Guangmi Li:今天第一位肯定還是 OpenAI,ChatGPT 已經上億的 DAU 了,還是很了不起的。The Information 曝出來 OpenAI 的 ARR 已經 34 億美金了。我們盤了一下整個硅谷其他所有 AI 公司的 ARR 加起來應該還不到 15 億美金,所以可能還不到 OpenAI 的一半。
Anthropic 是完全 To 企業端,ToC 很小。它可能是 OpenAI 今天的 1/10,大概 3 億多美金。Character AI 有 600-700 萬的 DAU,估值是 30-50 億美金。最近比較火的 AI 程序員是 20 億美金,還有很多想做 agent 的一些公司,比如新出來的 Reflection, 出來就幾億美金。邁到獨角獸級別的感覺應該就 10 家公司,但都還是在 PMF 之前,有規模化的 ARR,比如 超過 10 million ARR 的其實還是非常少。
張小珺:看起來大模型公司要比 AI native 應用的公司估值都要高?
Guangmi Li:大模型公司的估值肯定是顯著高的。OpenAI 是千億美金量級,Anthropic 和 Elon Musk 的 xAI 都是 200 億美金估值,再往后是 Mistral,50-60 億美金,Character AI 是 30-50 億美金, Cohere 也有 40-50 億美金估值。AI-native 應用中跑出一定量級、故事比較好的有幾個獨角獸,但很多公司的估值都還是在小幾億美金。
張小珺:所以 Perplexity 是在 AI native 應用里面的估值第一?
Guangmi Li:純應用的公司中是它的估值比較高的,不做模型的公司里面應該是估值最高的。
張小珺:我前段時間寫了一個報道,叫大模型的撲克牌,講的是中國資本在大模型領域的投資故事。海外大模型的撲克牌是什么樣的?和中國資本參與的顯著不同是什么?
Guangmi Li:海外更清晰一些,沒有那么混沌。AWS 和 Anthropic 深度綁定,微軟和 OpenAI 深度綁定,而 Elon Musk 是自成一派,靠自己的影響力融了 60 億美金,未來可能還能融更多錢。Character AI 想再融幾個 billion 美金的錢可能比較難,Mistral 最近剛融了 5-6 億美金。
所以前面獨立的公司只有三家:OpenAI、Anthropic、xAI。今年年內這三家公司都已經有了 3.2 萬卡的集群,到明年都是奔著 10 萬卡的集群去的。如果沒有一個極強的大腿再支持幾個 billion 美元量級的融資,其實挺難在大模型這里去卷的。
我比較期待未來 6-12 個月,Apple 和 Meta 這兩個怎么選?巴菲特 push Apple 了 1100 億美金的回購。如果是我的話,我覺得蘋果應該去收購一家公司。Meta Llama 團隊的人才密度感覺還是不夠的,可能還是有船票的。Elon Musk 拿到了最后一張船票。
張小珺:這個取決于人才嗎?
Guangmi Li:Meta 是有很多卡的,而且集群能力也是很強的,當其實人才上還是明顯弱于前幾家模型公司的。Elon Musk 的 xAI 其實像紅杉美國、a16z 這些基金都參與了,每家應該都放了 5 億美金左右,這對于 VC 基金還是挺大的一筆錢。
張小珺:我們剛才講完了整個大模型和 AI native 應用到底有哪些公司,以及他們的估值。根據你的觀察, AI 原生應用大爆發了嗎?
Guangmi Li:還沒有大爆發。GPT-4 出來一年了,大家也試了一年,其實是沒有系統性的大爆發的。90% 的因素是只基于 GPT-4 的能力水平是不夠的,只能做信息組合的創新,而沒辦法做長距離的推理、創造型工作,所以還是得卷下一代模型,尤其是推理能力和多模態能力。
還有 10% 的因素是時間問題,未來只基于 GPT-4o 的能力水平還是有概率能做出來大的應用的。NLP 已經出來 20 年了,也不算絕對成熟,但是也誕生了搜索這種 Killer App。電力發明以后很長時間也只有電燈泡這一個 killer app,但隨著時間推移,各種消費電子也都發明出來了,各種家用電器也都有了。大家打磨了一年多,也快有一些 PMF 的意思了,這里需要年輕的產品天才。
張小珺:能不能舉個模型能力和產品能力不夠的例子?
Guangmi Li:比如我就想要一個幽默版的 ChatGPT,會講段子、討人開心,這個不是一個傳統的產品經理能解決的,產品形態再怎么設計都很難,還是需要基礎模型能力變強。
我一直比較相信高情商是建立在高智商的基礎上的,首先模型要理解用戶,理解用戶的環境、背景、context。理解用戶這個圈子在發生什么,還能舉一反三。想實現幽默這一個點就不太容易,只有產品形態上的改變是不夠的,也得向下改模型的性格、改數據。
張小珺:你覺得應用大爆發的關鍵條件有哪些?我們之前在元旦跨年的節目里面也提到了新摩爾定律,當時總結是有兩條線:第一是能力上漲,第二是成本下降。今天你還維持這個判斷嗎?
Guangmi Li:這還是最重要的兩條線。我們和用戶、開發者和企業客戶這三類用戶做過訪談后發現他們會關注 2-3 個要素:第一是模型能力,第二是調用成本,第三是速度、latency。
假設模型能力不變,維持 GPT-4o 這個水平,如果未來一年速度再提升 3-5 倍,GPT-4o 比 GPT-4 Turbo 其實已經提了 3-4 倍的速度,如果成本還能再降 100 倍,是今天 GPT-4o 定價的 1%。那僅僅是速度提升 3 倍、成本再下降 100 倍,還是能催生很多東西的。
OpenAI 最近推出了 ChatGPT 桌面客戶端,大家可以試試,非常方便,快捷鍵能直接調出來,我的信息檢索基本上就不用再打開 Chrome 和 Google 了。ChatGPT 今天已經 1 億多 DAU,如果客戶端、手機端做得足夠好,未來做到 3-5 億 DAU 是很有希望的。到那個時候我覺得 OpenAI 是絕對可以掀翻 Google 一個墻角的。這里可以提一下,成本下降是高度確定的,但不一定是最重要的。最后還是取決于模型最后的經濟價值。不是所有的 Token 都有同樣的價值, Token 的質量決定了模型的商業模式,比如我今天問 ChatGPT 要買什么股票,它能告訴我買 AWS 還是 Meta,或者告訴我 Tesla 該買還是賣,那其實遠比給我一大堆搜索結果、各種報告是有意義的。
單位 token 的價值是更重要的,這還是模型能力本身決定的,這個就代表著一個模型工資的高低。

張小珺:ChatGPT 告訴你買什么股票你敢買嗎?
Guangmi Li:決策肯定會還是我做的。但有些基礎分析我覺得慢慢可信度是在提升的。
張小珺:模型的未來會分不同的工種,不同工種的定價是不一樣的?
Guangmi Li:比如我經常會問我們的分析師幫我研究一下幾家公司的對比。之后交互更好其實就可以問 AI 了。模型肯定是會出錯的,但是準確度和可信度都會經歷持續提升的過程。
張小珺:那是需要模型在垂直領域有更深的見解、有更多的數據獲取、能力更強,才能夠這么定價嗎?
Guangmi Li:所以 OpenAI 一定要把搜索做好才能滿足更多人的檢索準確度需求。比如 OpenAI 未來在金融領域的數據上再做很多的工作、做很多的 fine-tuning,那其實就能滿足金融投研從業者的需求。
張小珺:未來 6-12 個月哪些是你覺得高確定性要發生的問題,哪些是高賠率問題?
Guangmi Li:高確定性的關鍵詞就三個,第一是成本下降,第二是多模態改變交互,第三是端側。
成本下降其實是一個時間和工程問題,而且下降的速度可能會大幅超越大家的預期。創業者其實應該按照免費的心態去想怎么構建應用?其實不惜用量,就應該用最好的模型的 API 去制定 PMF。其實未來一段時間我也想沿著成本下降這條路去看看新的機會,之前哪些場景因為成本快速下降就突然 work 了,感覺還是會出來很多的。
我預計企業級里面會比較多。比如企業有知識庫、各種 Data Base。如果可以無限檢索,那準確度就會提升。
多模態方面是下一代交互。Voice Agent?可能是今年最值得關注的一個方向,也就是新一代的交互界面。打字還是太消耗了,而聲音大幅度降低了交互的能耗,就像觸屏手機比鍵盤手機能耗更低。GPT-4o 是第一個端到端、聲音進聲音出的大模型。這個技術路線下,下一代交互的一個開始就是低延遲、高智能。?
GPT-4o 的出現其實能讓端到端的新交互變得更快。核心的變量是 4o 的聲音 API 什么時候開放,可能短期還不會開放。手機觸屏的交互模式催生了短視頻,那聲音的 agent 是不是能孕育一個新交互模式的抖音應用機會?誰會是 Voice 領域新的抖音?
多模態改變交互的確定性很高,決定了 AI 原生應用的下限在哪,但我更期待的是多模態未來可以提升模型的邏輯推理能力,而這個目前還不確定,那其實也是一個高賠率的問題。今天多模態的數據知識密度太低,現存的多模態數據到底適不適合 AI 學習會是一個問題。網上很多的視頻都是人工剪輯后的,比如我們看到一個房子的大門后就直接進入到客廳了,人是知道怎么走過來的,但對于 AI 要怎么能一步一步的理解兩段視頻場景之間的邏輯關系比較重要。其次,今天多模態的泛化能力也不夠,比如讓模型讀特定領域的 PDF 文件,如果很多地方沒對齊,它其實就讀不出來的還有就是假如未來 GPT-4o 就在我們的眼睛、手表、手機上裝著,可以實時聽著我們,那以后我們也不用 Hey Siri、Hey Meta 來喚醒它了。模型未來可以實時地插話,我覺得這也是一個更好的交互形態。
第三個高確定性問題是端側,scaling law 是讓模型變得更大,探索智能的邊界和新智能的涌現能力,但大家其實遠遠低估了模型變小的速度。未來 6- 12 個月可能就會有一個 3B 大小的的模型也能達到極好的效果。
比如 GPT-4o 明年就變成了能跑在手機上一個 3B 的小模型,那對 PC 和手機端側帶來的機會還是比較大的。過去一年我們卷的是云端數據中心的基建,可能未來一兩年,甚至更長時間我們會卷端側的基建。今天 iPhone 的內存是 8GB,未來可能就是 12GB、 24GB 往上提升。端側的機會是很大的,模型變小的速度也是很快的。之前不 work 的產品,比如 IoT 互聯網,有可能也是會重新 work 了。
高賠率事件會有幾個,最重要的還是邏輯推理能力。這個也還是不確定性的科學問題,目前有兩三個路徑在嘗試,也有非常多的 Tricks。但大的方向上,下一代模型有更大的參數、更多高質量的數據、更大的模型,這個確定性是比較高的。還有就是解題和持續的 inference 也是提高邏輯能力的一個重點。
另外一個是可解釋性的重要程度還是被大家低估了。可解釋性如果能有突破,模型的可控性也就解決了。就像廣告系統可以定向給模型的回答加一些針對于用戶的傾向性。
另外一個高賠率的問題是模型的組織能力。全球所有的 AI 公司中,只有 OpenAI 的組織是相對工業化的。其他的 AI 公司都還有些實驗室的感覺。比如好萊塢是持續的產出好電影的,導演和演員,誰被替換掉好像也都可以。OpenAI 持續做科研的成功率是比較高的,目前推出 GPT-4o、之前推出 Sora,未來還是會持續推出很多東西的,如果按照單位 GPU 來看,OpenAI 的產出肯定還是最高的。
最后一個高賠率的問題是,如果明天 AGI 就實現了,那應該是用一個什么產品來承接?產品的載體值得思考,是手機上的 APP,還是各種其他的東西?其實還有一個高賠率和高確定性的問題,GPT-5 和 Claude-4 的能力提升,我覺得大家應該樂觀。
張小珺:模型變小的挑戰是什么?
Guangmi Li:今天最主要的挑戰是蒸餾。簡單理解就是,比如我做了一個應用,應用中有 90% 的 Query 可能都是圍繞 1000 個問題,這 1000 個問題我用不同的方法去問 ChatGPT,ChatGPT 給我的回答就足夠我去 train 一個自己小模型的語料了。這種方法的不足是相當于讓一個小學生、中學生能力的模型,通過死記硬背變得能說會道了,但其實不知道模型是不是真的智能。
其次是一個人總是能說會道,但是不會做任務,長期也是不行的。蒸餾會增加 hallucination,模型有時候不知道自己在說什么,不知道自己不懂的問題。OpenAI 訓練的小模型效果可能比別的公司的大模型效果還要好。
張小珺:端側的小模型肯定是會必然發生的嗎?端側小模型的意義是什么?
Guangmi Li:假如有一個 GPT-4o 在手機上時時跟著用戶,隱私永遠存在手機上用戶是更放心的,但如果存在云端用戶是不放心的,隱私是一個很重要的問題。如果用戶有一個很強的 AI 助理就在手機上,全天 24 小時打開它,用戶也是樂意的。但是在云端用戶可能就不一定樂意了。
AI 消費硬件還是很多中國創業者的機會,我們也看到很多創業者在考慮 Meta 眼鏡這種方向。這個形態蠻有意思的,但主要是今天的 AI 能力還不太行,但未來有可能做的事還是更多的。
張小珺:剛剛提到 OpenAI 的組織能力工業化,這個工業化體現在哪里?
Guangmi Li:OpenAI 的組織可以持續產出新的東西,做科研的效率也是最高的。比如一個很年輕、沒有太多的工作經驗的 PHD,到 OpenAI 一年就能產出 Sora,這個是蠻厲害的。OpenAI 的 Infra、怎么做事情、怎么做實驗、怎么定目標都是很強的。未來還會有更多這種例子。
張小珺:如果只保留 1-2 個能力,接下來你覺得能力躍升的重點是什么?
Guangmi Li:我覺得是邏輯推理能力加上多模態能力。
張小珺:如果 OpenAI 的 GPT-4o 給開發者的 API 成本大幅下降,下降到可以忽略成本,哪些應用可以爆發?
Guangmi Li:我也想順帶圍繞這個問題做個調研,大家可以在評論區留言。
我自己會首先看企業級應用。如果 API 成本可以忽略,那企業內的知識庫、內部的數據庫都可以放進去并且無限次檢索,那準確率是很高的,能讓企業內的 use case 落地。比如企業的客服場景,先前大家覺得大模型出來之后,AI 客服是理所當然的,但其實過去一年并沒有大規模出現 AI 客服。我們前段時間做了一些客服訪談,目前反饋最大的問題,第一是大模型不夠可靠,還不如 rule-based 的客服系統更可控,大模型容易亂回答,因為本質還是一個概率模型。第二個是 RAG 信息檢索是很難做好的,今天是沒有一個端到端、自動化、傻瓜式的 RAG 產品能讓檢索做得很好的。如果要精準的檢索企業內的數據,那如果成本降低,企業可以大規模、無限次地試,那可能對企業內的 use case 落地是有很大幫助的。
張小珺:能不能總結一下 GPT 在過去一年定價的下降的幅度?
Guangmi Li:假如按照每 100 萬 token 的定價來看,不同的三個版本。從輸入端上看,最早的 GPT4-128K,對應的是每 100 萬收費 60 美金。GPT4-Turbo 下降到了 10 美金,GPT-4o 下降到了 5 美金。輸出端上,最早的 GPT-4 是 120 美金,GPT4-Turbo 下降到了 30 美金,GPT-4o 已經是 15 美金了。過去一年定價已經下降了 10 倍,和我們之前新摩爾定律的預測是一樣的。
這個趨勢其實是符合我們預期的,但我也會比較好奇為什么 OpenAI 不更激進地降價?如果它更激進降價,對很多模型公司是一個毀滅性的打擊。
張小珺:你觀察下來, AI 應用型的人才畫像會是什么樣?
Guangmi Li:年輕人,90 后、95 后。其實和一些老的人聊,感覺包袱都很大,都想把產品確定的需求規劃出來,包袱挺多的,尤其是 90 后、 95 后。傳統的產品是一個自動販賣機,是有固定的按鈕、固定的 SKU 的。但今天模型不是一個固定的東西,是一個隨機性的概率模型,要接受這種不確定性的結果。
張小珺:可以給 AI 新物種大爆發一個時間的預測嗎?
Guangmi Li:GPT-5 出來后的半年,因為需要給大家一些實驗的時間。
張小珺: 為什么 GPT-5 和我們想象相比來得這么慢?去年我們很多的預期都是可能這個時候就已經出來了。
Guangmi Li:還是受限于 GPU。由于算力需求大,硬件供給還是不夠。GPT-4 相比 GPT-3 是幾十倍的算力提升,GPT-5 相比 GPT-4 也是十幾倍的算力提升。H100 芯片大批量到貨的時候已經是 2023 年的 Q4 了,集群搭起來還需要很多時間,大的 GPU 集群也不穩定,到今年初才能做大規模的訓練,因為從拿到 GPU 到真正能大規模的訓練可能還需要半年時間。
所以這并不是一個 AI 的問題,也不是大家提的數據不夠用問題,更不是 scaling law 遇到瓶頸的問題,就是實實在在的 GPU 物理世界建設問題。其實是簡簡單單的需要更大的算力。隨著模型變大,系統的復雜度也是指數提升的,因為模型變大以后出現的問題是大家可能之前想象不到的。
張小珺:這也 Call Back 了我們上一期節目 AGI 大基建受限于物理條件的問題。GPT-5 預計什么時候來呢?會帶來哪些根本性變化?
Guangmi Li:預期是今年年底。還是應該強調下 scaling law 應該是沒有減速的,雖然外面噪音比較多,但還是要相信這些全球范圍最頂尖、最聰明的科學家,硅谷幾個大的科技公司都是巨量投入到下一代模型中。
具體來講,相比于 GPT-4,GPT-5 的參數上還要大 3-5 倍,假設是 5-10 T 參數,數據量也要比 GPT-4 大 7-10 倍,不排除 OpenAI 可能也會發多個版本。未來可能是會走向非常大的 MoE,參數量巨大,但是激活不一定大,激活可能做到 500D。GPT-5 能做到多模態輸入、多模態輸出,但很難做視頻生成,視頻生成的成本還是比較高的。我一直不覺得 Sora 是在 AGI 的主線中,但 GPT-5 的視頻理解能力會提升。
模型變大后,GPT-5 的邏輯推理能力是能有大幅提升的,這個是對解鎖應用最重要的一個關鍵能力。另外是多模態的交互能力變強,其實會把應用打的比較高吧。
張小珺:為什么 GPT-4 和 GPT-5 之間要插一個 GPT-4o?
Guangmi Li:為了降成本,也能省出來很多卡去給到 research。這是一個最簡單的原因。成本下降的速度還是超出我們預期的。
張小珺:硅谷大模型公司格局在牌桌上發生了什么變化?
Guangmi Li:過去半年,硅谷的格局用簡單的一句話說就是 GPU 決定生死線。今年和明年分別對應兩條生死線。今年年內如果模型公司還沒有 3.2 萬卡的集群,那這家公司肯定就不在第一梯隊了。到明年,第一梯隊的門票是 10 萬卡集群,這里是指 H100,因為 B 系列可能要明年這個時候才能大規模到貨。這是一個明牌,拼資源、拼決心大不大。GPU 資源的競爭也會加速二、三線模型公司出局或者被收購的過程。比如像 Character AI、Mistral、Cohere。Elon Musk 拿到了最后一張門票,如果 Meta 想入局,還是得收購公司。
張小珺:中國公司在過去半年的梯隊有變化嗎?他們的生死線是什么?
Guangmi Li:今天這七八家還挺模糊的,從今天的模型能力上來看其實很難分辨哪家公司一定是最好的。從今天的模型能力上來看,是很難拉開的差距形成斷崖式領先的。目前是交替、都有一些亮點,第一個分水嶺就是哪家公司真正開始 GPT-4 水平的試訓練,擁有 8000 張 H100 量級的集群,但是今天好像還沒開始。
張小珺:Musk 的 xAI 相當于自己給自己造了一張大模型門票?它有什么差異化嗎?
Guangmi Li:可能存在一種暴力美學,因為 Elon Musk 公開提到了 xAI 就是 bet on 10 萬卡集群,而且是全球第一個,可能今年 8-9 月份上線充分互聯、全液冷的 10 萬卡集群。這意味著一個月可以 train 10 個 GPT-4,迭代速度變快了,并且可以更早訓練下一代模型。
我很期待這個超大集群未來能出來哪些新東西。xAI 如果比其它模型公司更早 6 個月做出來 10 萬卡集群,那是有彎道超車機會的。Elon Musk 覺得 GPU 是最重要能決定生死的資源。此外,xAI 的團隊還是很強的,可以看看他們未來能不能很快發出來接近 GPT-4、Claude-3 水平的模型,我還是比較樂觀。
張小珺 :據你了解大模型公司工作節奏怎么樣?他們卷不卷?
Guangmi Li:工作節奏是非常卷的。我聽過一個很形象的比喻,大基建很像西部拓荒,OpenAI 內部的狀態就像一個從東向西的火車來開拓美洲大陸,科學家讓火車在高速奔跑, Infra 工程師在前面修鐵路,鐵路鋪設和火車行駛是齊頭并進的,你就能感受到這種狀態。很多人說硅谷下午 4-5 點就下班,這個印象不是全對的。做大模型的人都是很卷的,基本的休息時間、運動時間幾乎全沒了,每天都在一個很卷的戰斗狀態。因為沒解決的問題比解決的問題多,而且新問題也非常多。
OpenAI 是最卷的,而且人才密度也確實是最高的。有一個朋友提到連續 5 天平均每天只睡 3 個小時,睡前和醒來就是在 train Model。
張小珺:整體來看,過去一年你覺得在大模型上中美差距是放大還是縮小了?
Guangmi Li:有一個非共識的觀點是真實差距可能在拉大,而不是表面上看著真的追上了。更準確的說應該是可以局部追上,比如熱門問題的問答,但是國內模型處理長尾的問題其實都還不太行,這個就說明模型的泛化能力還是不夠的。最核心的是今天我們不知道 OpenAI 內部走到多遠了。GPT-4o 到底代表 OpenAI 的幾成功力呢?有可能只占三成功力。OpenAI 的人才密度很高,也都是非常聰明的人,而且有最領先的模型,也能更早拿到了更大量的 GPU、做更多的探索。只是探索的結果已經不公開了。用 5% 的資源就想真正超過 OpenAI 百分百的投入還是比較難的,除非說第一名成為先驅。人才密度角度上看,OpenAI 的一個人還是能頂其他公司的十個人。Sora 團隊可能也就不到 10 個人,別的公司可能幾十個人也不一定能做出來一樣的模型。
外界是希望更早、更快地看到一些新的進展,但模型變大后,需要處理的細節還是很多的。過去 GPT-4 其實是一個技術發展史中的跳躍時刻,那不可能每年都有這種跳躍時刻的,因為大家的預期變高了。不跳躍大家可能就覺得無聊了。然后其中很多細節、各種產品的打磨,需要的工作量還是比較大的。里面是一個優化打補丁的點,大家都還是基于 Python 來做的,只能每次處理一個事情,執行起來其實是不夠 Efficient。最近也有人提出基于 C 語言手搓一個大模型,只是說大家還沒有大規模試起來,大家對模型結構的優化做的還是比較多的,只是外界可能沒有談到。
張小珺:在 GPU 上中美差距拉大了嗎?
Guangmi Li:國內應該還是小幾千張 GPU 做訓練,而硅谷的一線模型應該都是 2-3 萬卡的集群做訓練了,下一階段是 10 萬卡集群。Elon Musk 還提到自己有 30 萬張 B100,這就對應了 60 萬張 H100。國內可能首先要突破萬張卡和萬億參數 MOE 這兩個臨界點,我也不知道未來怎么去追趕 10 萬卡集群,而且 OpenAI 和微軟的星際之門(Stargate),投入 1000 億美金搭建新的超級計算機。如果這件事情真的在發生,不知道怎么去追趕。

張小珺:Benchmark 上看國內模型是追上來了。
Guangmi Li:模型評估是很難的,就像評估一個人一樣。Benchmark 的題目全是公開的,也都可以圍繞題目做提前的充分訓練。可以理解為這個榜單已經被 Hack 掉了。另一方面是蒸餾,國內模型做蒸餾還是比較多、比較兇的,很多人在 distill 頭部模型公司的數據。最終模型的經濟價值還是取決于是否能做任務。國內模型這么多,其實也挺難說哪家是真的好,今天可能還是模糊的狀態。短期模型能力是不決定勝負的,還是真正看誰先做出 GPT-4 水平的模型。但是做出來 GPT-4 水平的模型又會怎樣呢?下一階段可能會是,哪家公司先能有 3000-5000 萬 DAU 的產品占住心智,留存好、商業模式跑通,這個比較重要。
張小珺:接下來我們來聊聊大模型的商業模式和壁壘。大模型是一個好的商業模式嗎?
Guangmi Li:目前肯定沒有廣告平臺的商業模式好,訂閱還是一個比較傳統的商業模式。
ChatGPT 現在是 1 億多的 DAU,假設 10% 的付費用戶,那就是 1000 萬付費用戶,訂閱 200 美金一年,總數就是 20 億美金。假如未來能翻幾倍,那相比 Google 廣告平臺一年 2000 多億美金的營收,也還只是 Google 營收的 1%- 2%,是比較小的。
廣告平臺是一個非常成熟的商業模式,每新增一個用戶,在未來 6- 12 月肯定是能把新增用戶花費的成本賺回來的,這個 ROI 是能算得很清楚的。
但大模型投入,購買 GPU 的 ROI 是沒法計算而且很難分析的。因為這里面兼具著很多科研屬性,而且失敗率比較高,失敗的成本其實是 GPU 的時間,一張 GPU 運行一個小時的成本假設是 3 美金,那一張卡一個月可能就是 200 多萬美金成本。用不好 GPU 就是在浪費成本。
但從另外一個角度思考, GPT-4 當年的訓練成本假設是 2 億美金,OpenAI 已經通過 ChatGPT 早就賺回來了這個錢,單看 ChatGPT 這個產品好像是盈利性很好的,他們的虧損主要還是在探索新的模型技術上。
這就很像藥企的新藥研發,也許 GPT-5 還能發現下一個新藥,也能幫 OpenAI 賺更多的錢,但從全球范圍看,可能也只有 2-3 家模型公司通過賣模型可以把訓練成本賺回來。其實很多模型公司連訓練成本還是賺不回來的。
新事物的商業模式總是要慢一些。比如 AI Agent 落地后會不會顛覆廣告平臺?用戶讓一個 Travel Agent 幫忙規劃一個意大利的旅行計劃,用戶的精力和注意力是有限的,其實是被迫看了很多廣告。那如果有一個 Travel Agent,其實就不用看太多廣告了,而是讓 Agent 幫忙比價、談價。這對傳統廣告平臺是有很大顛覆效應的,傳統的廣告平臺是建立在人的注意力和精力是有限的情況下,但未來 Agent 是 7* 24 小時工作。
包括之前播客提到未來能不能有一個 value-based 的定價,類似于在電商平臺賣掉 1 萬塊錢商品要給電商平臺付 5 個點左右的抽成。那未來用 ChatGPT 的 Agent 增加了 1 萬塊錢每月的產出,給 OpenAI 付 500 塊錢, 對應 5% 的抽成好像也合理。
而且今天模型的 API 切換成本是不高的,用戶很容易換,也因此很容易產生價格戰,整體來看感覺還不是一個最好的商業模式。
張小珺:聽起來最后好的商業模式還是建立在產品和應用上,那會是什么樣的產品?如果 AI 助手的產品都是幫助用戶節約時間,那它就讓廣告投放天然會變得比較差?
Guangmi Li:是的,任何一個偉大的公司都是建立在極好的商業模式之上的。廣告、類似 Apple 這種科技消費品、公有云平臺,都具有規模效應,包括電商平臺。AI 公司想成為偉大公司,還是要有極好的商業模式。今天商業模式的 0 到 1,這個 1 我覺得還是沒有跑通的。
張小珺:產品角度跑通了嗎?AI 助手是不是一個好的產品形態?
Guangmi Li:不知道,核心還是看是不是足夠聰明。如果足夠聰明,那就相當于 AGI 來了。很多商業模式都會從本質上發生變化,廣告平臺也發生變化了。
張小珺:大模型的壁壘在哪里?
Guangmi Li:壁壘是明牌。第一階段就是 GPU,第一梯隊如果沒有 3.2 萬卡,今年就很難在硅谷坐穩第一梯隊。但其實背后更核心的點,是要具備 30-50 人的核心人才團隊。今天很難再重新 build 一個像 xAI 一樣團隊了,因為人才收斂比較快的,最后可能還是一個綜合的壁壘。比如說像好萊塢,有沒有工業體系和成熟的組織方式決定了效率。如果給了卡,也投入很多錢,但最后科研的效率很低,那也很容易掉隊。
張小珺:現在很多人開始說 scaling law 不一定是唯一的路徑,或者是錯誤的路徑。你覺得會有不一樣的路徑能走向 AGI 嗎?
Guangmi Li:Scaling law 是最簡單的路徑了,因為簡單粗暴地懟 GPU 就能通往 AGI,如果成功就可以造福人類,失敗也是科技巨頭買單,那其實是應該繼續加大投入的。
很多人也在關心另類的架構,其實肯定 OpenAI 是更關心另類架構的,新的架構 OpenAI 應該全都試過了,但至今是沒有發現其他新的、真的 work 的路徑的。如果有,大家肯定就撲上去了。今天還有很多人質疑 transformer ,其實是不是 transformer 也不重要了。最重要的還是什么架構既能滿足持續的 scaling up、又能具有通用的泛化能力,這兩個能力是 transformer 最大的優勢。但 transformer 今天最大的缺點是 data hungry,其次是 compute hungry,要消耗很多的數據,消耗很多的卡。data 和 compute 效率是頭部模型公司目前在解決的。有可能未來的架構還是以 transformer 一個底座,有本身優秀的特性。上面加一些能讓 data、compute 更 efficient 的新架構。
這里有一個高賠率的問題,是研究怎么提高 data 和 compute 效率的問題,讓小樣本數據也能取得很好的效果。比如教一個小學生解方程,可能教個幾十次慢慢就能教會了。但是今天要教給模型,可能要教幾萬次。隨著模型能力變強,可能未來幾百個也就夠了,甚至說模型能力更強了之后可能教他兩三個就夠了,這就是一個數據的效率吧。其實在模型架構角度,像 OpenAI、Anthropic 其實對 transformer 的動刀幅度已經很大了,比如馬車早已經沒有了馬,已經變得四不像了。
其次也要看大家對 AGI 的預期。AI 并不完全需要像人,人機互補是更重要的。比如 AI 很擅長數據吞吐量特別大的工作,可以并行讀取、加工很多的數據。而且 AI 比人更擅長學習,能從大量的數據中找到最大公約數。今天 AI 數據量小的時候是不如人的,但 AI 也有更擅長,比如它可以 7* 24 小時工作、提供經濟價值。如果邏輯推理能力提升之后還可以 7* 24 小時幫用戶去執行推理的工作。
只要能創造經濟價值就好了,不一定需要完全 follow 人的工作,馬車也沒有馬,就是輪子,效率也比較高。AGI 即便無法實現,下限也是非常高的。AIGC 在數據量很大、套路很多的領域是更有優勢的, AI 提供了智能的勞動力,人是智能的創造力。
基于 scaling law 讓模型變大其實主要是在探索智能的邊界,并不是模型一定要保持一直很大的狀態。未來人們把模型變小、進行大規模商用的速度也會是很快的,是一個時間和工程的問題。
張小珺:在大模型的應用側,除了 AI 軟件,其實還有通用機器人和無人駕駛,你怎么看待這兩條腿的落地?
Guangmi Li:通用機器人的大腦未來就是多模態大模型的底座,再加一些針對機器人數據的 fine tuning,我覺得是不存在獨立的機器人大腦模型的,其中有一個難點是怎么從大腦的智能規劃能力轉化為控制信號,這是未來需要大規模鋪設設備基礎上才能繼續做的。硅谷的通用機器人公司,除了 Tesla 外,都不具備制造硬件本體的能力,硬件大概率還是中國公司的機會。控制部分比較難,中國的供應鏈優勢還是非常強的。
還有個點比較有趣的是今天想做通用機器人的公司還沒有一家能定義出來一個真正好的場景的,所以大家就只能先把通用機器人開發出來,就像當時個人電腦開發的過程一樣。大家也不知道怎么用,最后大家發現 PC 的第一個場景是報稅,于是企業內部報稅先用起來了。
所以有可能通用機器人明年可以大規模的做出來讓大家去試,有可能餐廳老板我能用把機器人起來,或者酒店老板說我能用起來,到最后就是大家去試場景的過程。
張小珺:通用機器人和無人駕駛哪個會落地的更快?
Guangmi Li:自動駕駛更快。Tesla 團隊是比較自信的,覺得可能 2 年內可以結束戰斗,通用機器人可能還需要 5 年。因為自動駕駛是一個限定領域,總共有幾個 action:往前走、剎車、左轉、右轉。但通用機器人的目標還沒有定義清楚。而且無人駕駛領域 scaling law 和成長速度還是比較快的,也比較期待接下來 8 月 8 日 Tesla Robotaxi 的發布,可以看看到時候還有沒有方向盤,如果沒有方向盤那是真的比較自信了。
張小珺:FSD 這一年有什么進展?兩年內結束戰斗能結束到什么程度?
Guangmi Li:從 Palo Alto 開車到三藩基本不用碰方向盤了,甚至不用碰方向盤了。這已經是一個挺大的進步了,FSD 的安全性已經比人要高很多了。FSD 的終局可能是Tesla 一部分車型可以沒有方向盤了,這樣的話它就可以重新定義“車”這個產品了。
張小珺:我們接下來聊聊過去半年巨頭都發生了什么。OpenAI 變化也很大,Ilya 離開了,也造成了一個小的 OpenAI 離職潮,這種離職風波對這家公司影響大嗎?可以先講講怎么看 Ilya 的離開?他的離開對于 OpenAI 的影響大不大?
Guangmi Li:有兩派觀點,一派是認為 Ilya 過去幾年貢獻不是很突出,另外一派認為 Ilya 的 research taste 非常好,講的都是未來三五年決定性的事情。
我感覺 Ilya 的離開對于 OpenAI 幾乎沒有任何影響,OpenAI 最核心 100-200 人是沒有變化的。其他的公司像 xAI、Anthropic,或者其他模型公司想挖人幾乎是挖不動 OpenAI 最核心的人的。新加入的人主要還是圍繞產品、商業、安全這些方面。最核心的底子是非常穩且非常強的。
張小珺:最近 Apple 舉辦了發布會,大家的關注度比較高。你怎么看 Apple 這次的發布?
Guangmi Li:Apple 還是很穩的,未來三年手機可能還是人們最方便、最可信的設備。今天好像看不到哪個設備真的能夠替代手機。之前出現了很多 AI 消費設備,但更多還是一個補充。對蘋果最重要的一個判斷是 AI 的 feature 能不能帶來手機的換機潮?這個是對 Apple 商業上最重要的一個判斷。其次是能夠加上什么樣的新 feature?比如內存很大、端側模型能力足夠強,能夠刺激用戶愿意買一個新的手機,或者 Siri 真的變得極其聰明了、有其他的 features 出現,促使用戶去買一個新的手機才是一個更大的變化。
硅谷的科技巨頭股價都已經漲了那么多,真的要挑一個能用媽媽養老的錢買的公司股票,我可能還是愿意買 Apple,雖然估值也不便宜。
張小珺:為什么 Apple 這次發布會以后股價大漲了 7 個點?
Guangmi Li:因為大家發現 OpenAI 沒有顛覆巨頭,并且最后都要求著巨頭。
張小珺:Google 呢?
Guangmi Li:Google 的模型進展好像是不是很樂觀。從 Gemini 1.5 之后大幅的提升是沒有的。Google 的流量優勢還是很強的,但好像模型還是差一點意思。不知道具體原因是什么。
張小珺:英偉達呢?
Guangmi Li:英偉達現在 3 個 T 的市值和股價已經提前 price-in 了未來一年半到兩年的預期。大家對英偉達的股價爭議還是比較大的。
其實今天從股價角度討論英偉達已經超出了可分析性,有特別多人對英偉達極其有信仰,其實越來越多人今天討論英偉達和 2021 年討論比特幣一樣,都在討論信仰。但確實從實際角度來講,英偉達沒有競爭對手。全球范圍的模型公司 train 模型,除了 Google 用自己的 TPU train model 以外,幾乎所有人都是用 GPU 來 train LLM 大模型。未來兩三年的競爭格局也是極其穩的,不太會有新的公司,完全顛覆英偉達了。
但是 AI 的變化是很快的,敘事上變化也是很快的,可能會影響大家對它的預期。長期英偉達肯定還是極其重要的公司,是整個 AGI 基建中最關鍵的一個要素。就像 Elon Musk 說的 GPU 定生死,英偉達還是一個最重要的角色。
張小珺:Amazon 呢?
Guangmi Li:我們之前有一個感覺是模型 to 企業側最大的客戶是云平臺,因為云與企業建立了最深的信任。先前也有說法是在大模型上花一塊錢,就會在云上帶來 5 塊錢的營收。我們一直想把這個假設調研清楚,但是一直沒有找到太多的 facts。企業除了測試以外,在 cloud spending 層面還沒有大規模的新東西出來,因此可能還是需要花一些時間。但是云還是很穩的,很多企業客戶不是直接調用 GPT、Claude 的 API,而是調云廠商的 API。因為云更穩定,可信度更高。Azure 之前的聲音很大,但比較下來 AWS 的技術積累與客戶積累還是很 solid 的。
張小珺:Meta 呢?
Guangmi Li:Llama 3 400B 的模型一直還沒有發出來,據說是內部還沒搞清楚 MoE 怎么做。Meta 好像一直在 train,train 到一個好的結果再發出來。這個模型不一定會開源了,因為這么大的模型如果再開源,很多人是用不起來的,而且成本比較高,是一個 400B 的 dense model。
張小珺:微軟呢?
Guangmi Li:首先,Copilot 距離先前的預期還是要差一些。我印象最深的還是微軟和 OpenAI 提出了星際之門,投入 1000 億美金造一個最大的超級計算機,具體會怎么實施,以及到底能帶來什么樣的突破,這兩點會是最有意思的。
張小珺:Tesla 的變化是什么?
Guangmi Li:EV 的銷售競爭是很激烈的,所以車本身是很被動的。FSD 每隔幾個月就有一個大幅提升, xAI 未來一段時間可能有很多間接的技術助力。我感覺 FSD 的進度可能是比 AGI 要更快的。
今天對特斯拉一個比較大的爭議是特斯拉到底是一個車的公司還是一個 AI 的公司?但目前 AI 的 revenue 還是沒有的。如果是作為車企的話那可能就是一個比較低的估值。AI 怎么體現出來是比較重要的,而且 100 美金每個月的 FSD 定價是比較高的,如果說 FSD 免費了,或者說通過車險來間接付費,可能會是一個更好的做法。因為 FSD 對車險未來的沖擊還是比較大。
張小珺:臺積電呢?
Guangmi Li:全球 100% 的 H100 都是臺積電參與生產,這個公司的重要性是極強的,因為過去卷了云端的數據中心,下一步又要卷手機上的芯片, Apple 還是臺積電的最大客戶。所以感覺這么大體量了每年還能有 50%的增速是極其厲害的。臺積電未來幾年也是不可替代的。
其實我們聊的這幾個大的公司,潛在都還是受益的。拿著這幾個大的公司做一個?Passive 的指數,是能跑贏很多其他產品的,反而這一波是強者恒強的局面。AI 公司并沒有真的顛覆大的公司,而且是依附于大公司。
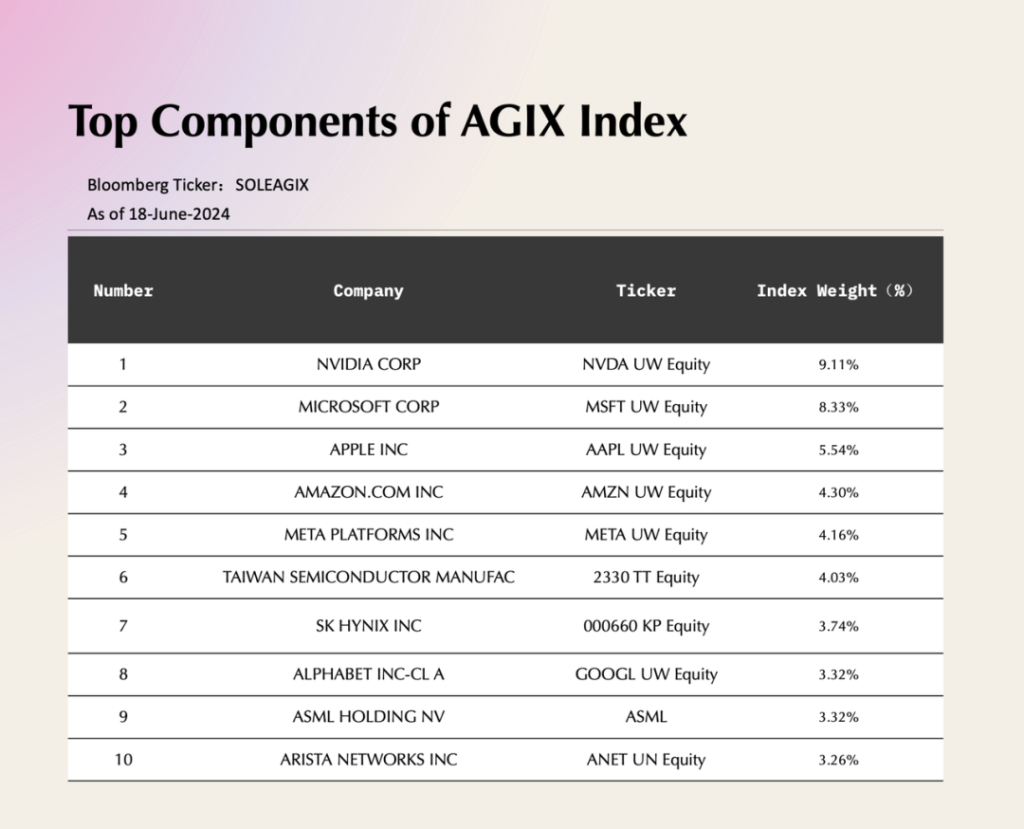
AGIX Index Top10 Components
張小珺:今天的 AI 公司都活在巨頭的陰影下,這是為什么?
Guangmi Li:第一,太燒錢了。第二, AI 的能力還是一個小學生、初中生的水平,還需要時間慢慢長大,還要大公司給錢繼續再養著,估計還得養一段時間。
創業公司和大公司不是顛覆關系,而是依賴關系。第一,AI 公司還是太花錢了。第二,巨頭的卡位太好。今天 OpenAI 是沒法撒開腿跑的,因為它逃離不了幾個科技巨頭的覆蓋。GPU 受限于英偉達,如果英偉達不提前給 OpenAI 卡,或者說英偉達給第二名、第三名模型公司卡,那 OpenAI 也會卡不足。GPU 的集群的搭建是受限于微軟的,微軟還是 49% 的大股東,金主,微軟的 Azure 是 GPT 觸達企業客戶最重要的一個渠道。
C端還是逃離不了蘋果,最后還要求著蘋果集成 ChatGPT。蘋果其實還是可以分分鐘換掉 ChatGPT 的,所以 OpenAI 如果真的顛覆,目前也只能挑戰一下。
張小珺:AGI 時代 VC 投資變難了嗎?
Guangmi Li:我覺得是變難了。現階段面對的很多問題是科學問題,不是一個可分析的數學問題或數字問題。如果今天投大模型,依然是兩條標準,第一,這個公司是不是一個做 AGI 的團隊?是不是真的奔著 AGI 在前進、 有 Vision,也有團隊基礎?第二,有沒有大腿支持做 AGI。模型公司每年要買 10- 20 萬張卡,要幾個 Billion 的投入。背后是有一個巨大、長期的資源支持問題,這個是非常重要的。AGI 競賽的正賽還沒有正式開始,大事還沒有發生。
比如很多人提 RAG,幾十家公司在做 RAG 這個方向,其實今天還是很難分析哪一家公司一定能跑出來,因為應用還沒有大爆發。那今天的 RAG 產品還沒有經歷過大的考驗,經歷過大的考驗后殺出來的公司才是比較重要的。
張小珺:為什么突然開始提 RAG 提的比較多?
Guangmi Li:有人說 RAG 是階段性需求,因為企業內有很多樣的各種信息要檢索, LLM 只用通用的東西是回答不了的,所以需要有檢索增強,把企業內的各種知識能檢索、排序理解得比較好。因為沒落地,那就要一個 RAG 的產品來幫它,但發現加了 RAG 之后,首先今天還沒有太多人能做好 RAG,第二,做好了之后依然還沒有弄好。RAG 做得最好的還是 Perplexity 里,它是檢索網頁檢索的最好的。
張小珺:RAG 的核心難點是什么?Perplexity 為什么做得好?
Guangmi Li:RAG 是一個工程問題,有十幾個環節都要優化。一個公司優化好一個環節比較容易,但是要優化好 10 個環節其實是很難的。
張小珺:對比下來你看美國和國內這兩邊的創新生態在 AI 上有什么差異?
Guangmi Li:硅谷 0 到 1 還是比較多的,而中國的創業者 1 到 100 非常多。這是一個非常明顯的體感差異,背后是資本的充裕程度。硅谷長期能 0 到 1 創新挺重要的背后是容忍了非常多的失敗。即使有人失敗了后,他的公司依然還能被收購、還能退出。硅谷的收購環境也比較好,感覺硅谷還是一個創新的溫室,很多人可以異想天開,因為有比較充足的 VC 資本支持 0 到 1 的創新。
國內 1 到 100 更多,這里面會導致一個問題:技術辨識度還是比較低,而且創業的玩家比較多。內卷有很大的原因是技術辨識度比較低,比如今天沒有公司與 SpaceX 競爭,甚至說今天要買一個無人機,人們不知道大疆的第二名是誰?大疆是有技術辨識度的。我是期待更多的 0 到 1 創新的,創業者能提出一些更不一樣的,也需要更多長期的風險資本的支持。
張小珺:最后我們來做一個展望, 2024 年下半年你會更愿意把時間花在哪里、會重點關注哪些問題?
Guangmi Li:第一是關于成本下降,因為這是一個高度確定的事情,那我希望圍繞成本下降速度提升,哪些應用原本不 work,最后 work 了,這是值得期待的。
第二個比較期待端側,手機上能加哪些新的東西,尤其是國產手機,包括新的消費設備,可能是對手機一個很好的補充,比如像 Meta 眼鏡可能就是一個多模態的入口,與手機有一個更好的輔助,那端側可能會出來很多東西。
第三是通用機器人,通用機器人需要的時間會很長,但是會很有意思,因為多模態模型在進步。中國創業者的機會還是很多的。
文章轉自微信公眾號@海外獨角獸







