
什么是GPT-4?完整指南
圖 1.DB-GPT-Hub 的架構(gòu)流程圖
如圖一所示:DB-GPT-Hub 項目重點關(guān)注在數(shù)據(jù)預(yù)處理 – 數(shù)據(jù)集構(gòu)建 – 模型微調(diào) – 模型預(yù)測 – 模型驗證部分,微調(diào)得到的模型可以無縫銜接部署到 DB-GPT 框架中,然后結(jié)合知識問答和數(shù)據(jù)分析等能力展示模型在 Text2SQL 領(lǐng)域的優(yōu)越性能。
具體功能:
數(shù)據(jù)集構(gòu)建:將原生的 text2SQL 數(shù)據(jù)處理成合適的格式(Text Representation Format)以微調(diào) LLM。這包括將問題和數(shù)據(jù)庫 schema 的描述集成到提示中作為指令(instruction),以及各種問題表示以提高訓(xùn)練和評估期間的性能。此外,將選擇不同的 few-shot 策略(例如 example selection 和 organization)來構(gòu)建評估數(shù)據(jù)集訓(xùn)練:的代碼庫支持使用 PEFT 策略對開源 LLM 進行微調(diào)。支持大多數(shù)公共架構(gòu),模型規(guī)模從小到大,例如 Qwen、Llama、Baichuan 和 ChatGLM預(yù)測:的代碼庫支持開源 LLM 的微調(diào)版本和閉源 LLM 的 SQL 查詢推理。支持使用少樣本和零樣本方法來生成特定場景的 SQL評估:同時,支持不同的評測指標(biāo)(EX、EM)來從不同角度評估生成的 SQL 的性能。以開源數(shù)據(jù)集 Spider 為例做一個詳細的介紹,Spider 數(shù)據(jù)集是一個多數(shù)據(jù)庫、多表、單輪查詢的 Text2SQL 數(shù)據(jù)集,是 Text2SQL 任務(wù)中最具挑戰(zhàn)性的數(shù)據(jù)集之一,由耶魯大學(xué)的 LILY 實驗室于 2018 年發(fā)布,具有如下特點:

圖 2: 不同數(shù)據(jù)集的語法分布
spider 數(shù)據(jù)集將 SQL 生成分成了四個等級:
為了充分利用數(shù)據(jù)庫中的表和字段等相關(guān)信息,對 Spider 中的原始數(shù)據(jù)進行處理,用自然語言表示數(shù)據(jù)庫包含的表結(jié)構(gòu)以及表結(jié)構(gòu)包含的字段以及相應(yīng)的主鍵和外鍵等,經(jīng)過數(shù)據(jù)預(yù)處理后,可以得到如下的數(shù)據(jù)格式:
{"instruction": "concert_singer(數(shù)據(jù)庫名) contains tables(表) such as stadium, singer, concert, singer_in_concert. Table stadium has columns(列) such as stadium_id, location, name, capacity, highest, lowest, average. stadium_id is the primary key(主鍵). Table singer has columns such as singer_id, name, country, song_name, song_release_year, age, is_male. singer_id is the primary key. Table concert has columns such as concert_id, concert_name, theme, stadium_id, year. concert_id is the primary key. Table singer_in_concert has columns such as concert_id, singer_id. concert_id is the primary key. The year of concert is the foreign key(外鍵)of location of stadium. The stadium_id of singer_in_concert is the foreign key of name of singer. The singer_id of singer_in_concert is the foreign key of concert_name of concert.",
"input": "How many singers do we have?",
"response": "select count(*) from singer"}{"instruction": "concert_singer(數(shù)據(jù)庫名)包含表(表),例如stadium, singer, concert, singer_in_concert。表體育場有列(列),如stadium_id、位置、名稱、容量、最高、最低、平均。Stadium_id是主鍵(主鍵)。表singer有這樣的列:singer_id、name、country、song_name、song_release_year、age、is_male。Singer_id為主鍵。表concert有如下列:concert_id、concert_name、theme、stadium_id、year。Concert_id是主鍵。表singer_in_concert有如下列:concert_id, singer_id。Concert_id是主鍵。演唱會年份是場館位置的外鍵(外鍵)。singer_in_concert的stadium_id是歌手名的外鍵。singer_in_concert的singer_id是concert的concert_name的外鍵。
"input": "我們有多少歌手?"
"response": "select count(*) from singer"}同時,為了更好的利用大語言模型的理解能力,定制了 prompt dict 以優(yōu)化輸入,如下所示:
SQL_PROMPT_DICT = {
"prompt_input": (
"I want you to act as a SQL terminal in front of an example database. "
"Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\n"
"###Instruction:\n{instruction}\n\n###Input:\n{input}\n\n###Response: "
),
"prompt_no_input": (
"I want you to act as a SQL terminal in front of an example database. "
"Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\n"
"###Instruction:\n{instruction}\n\n### Response: "
),
}將從基礎(chǔ)模型和微調(diào)方式來進行
目前支持的模型結(jié)構(gòu)如下所示,包含了當(dāng)下主流的中外開源模型系列,比如 Llama 系列、Baichuan 系列、GLM 系列、Qwen 系列等,覆蓋面廣,同時 benchmark 橫跨 7b/13B/70B 的規(guī)模。

圖 5: 不同模型的微調(diào)模式
Text2SQL微調(diào)主要包含以下流程:
在大語言模型對特定任務(wù)或領(lǐng)域進行微調(diào)任務(wù)時,重新訓(xùn)練所有模型參數(shù)將會帶來昂貴的訓(xùn)練成本,因此出現(xiàn)了各種優(yōu)化的微調(diào)方案,綜合評估模型微調(diào)速度和精度,實現(xiàn)了當(dāng)下流行的 LoRA(Low-Rank Adaptation 的簡寫) 方法和 QLoRA(量化 + lora)方法。 LoRA 的基本原理是在凍結(jié)原模型參數(shù)的情況下,通過向模型中加入額外的網(wǎng)絡(luò)層,并只訓(xùn)練這些新增的網(wǎng)絡(luò)層參數(shù)。由于這些新增參數(shù)數(shù)量較少,這樣不僅 finetune 的成本顯著下降,還能獲得和全模型微調(diào)類似的效果,如下圖所示:

圖三. LoRA 微調(diào)示意圖
QLoRA 方法使用一種低精度的存儲數(shù)據(jù)類型(NF4)來壓縮預(yù)訓(xùn)練的語言模型。通過凍結(jié) LM 參數(shù),將相對少量的可訓(xùn)練參數(shù)以 Low-Rank Adapters 的形式添加到模型中,LoRA 層是在訓(xùn)練期間更新的唯一參數(shù),使得模型體量大幅壓縮同時推理效果幾乎沒有受到影響。從 QLoRA 的名字可以看出,QLoRA 實際上是 Quantize+LoRA 技術(shù)。

圖 4:QLora 示意圖
模型微調(diào)完后,基于保存的權(quán)重和基座大模型,對 spider 數(shù)據(jù)集的 dev 測試集進行測試,可以得到模型預(yù)測的 sql。 預(yù)測的 dev_sql.json 總共有 1034 條數(shù)據(jù),同樣需要經(jīng)過數(shù)據(jù)預(yù)處理后,再拿給模型預(yù)測結(jié)果。
{"instruction": "concert_singer contains tables such as stadium, singer, concert, singer_in_concert. Table stadium has columns such as stadium_id, location, name, capacity, highest, lowest, average. stadium_id is the primary key. Table singer has columns such as singer_id, name, country, song_name, song_release_year, age, is_male. singer_id is the primary key. Table concert has columns such as concert_id, concert_name, theme, stadium_id, year. concert_id is the primary key. Table singer_in_concert has columns such as concert_id, singer_id. concert_id is the primary key. The stadium_id of concert is the foreign key of stadium_id of stadium. The singer_id of singer_in_concert is the foreign key of singer_id of singer. The concert_id of singer_in_concert is the foreign key of concert_id of concert.", "input": "How many singers do we have?", "output": "select count(*) from singer"}模型預(yù)測的核心代碼如下:
def inference(model: ChatModel, predict_data: List[Dict], **input_kwargs):
res = []
# test
# for item in predict_data[:20]:
for item in tqdm(predict_data, desc="Inference Progress", unit="item"):
response, _ = model.chat(query=item["input"], history=[], **input_kwargs)
res.append(response)
return res模型預(yù)測得到 sql 后,需要和 spider 數(shù)據(jù)集的標(biāo)準(zhǔn)答案對比,使用 EX(execution accuracy)和 EM(Exact Match)指標(biāo)進行評估 EX 指標(biāo)是計算 SQL 執(zhí)行結(jié)果正確的數(shù)量在數(shù)據(jù)集中的比例,公示如下所示:
EM 指標(biāo)是計算模型生成的 SQL 和標(biāo)注 SQL 的匹配程度。
的 benchmark 在 bird 和 spirder 兩個數(shù)據(jù)上構(gòu)建:
整體代碼適配 WikiSQL,CoSQL 等數(shù)據(jù)集。
更多內(nèi)容參考:NL2SQL基礎(chǔ)系列(1):業(yè)界頂尖排行榜、權(quán)威測評數(shù)據(jù)集及LLM大模型(Spider vs BIRD)全面對比優(yōu)劣分析[Text2SQL、Text2DSL]

表 1.Spider 的 EX 準(zhǔn)確率表,L 代表 LoRA,QL 代表 QLoRA

表 2.Spider 的 EM 準(zhǔn)確率表,L 代表 LoRA,QL 代表 QLoRA

表 3.BIRD 的 EX 準(zhǔn)確率表,L 代表 LoRA,QL 代表 QLoRA

表 4.BIRD 的 EM 準(zhǔn)確率表,L 代表 LoRA,QL 代表 QLoRA
如下圖所示,以三個 7B 模型為例,展示了調(diào)整后的 LLM 針對一系列 SQL 生成難度級別的有效性。對于所有三個微調(diào)后的模型,結(jié)果都表明性能提升的大小與 SQL 復(fù)雜性呈負相關(guān),并且微調(diào)對簡單 SQL 的改進更為顯著。

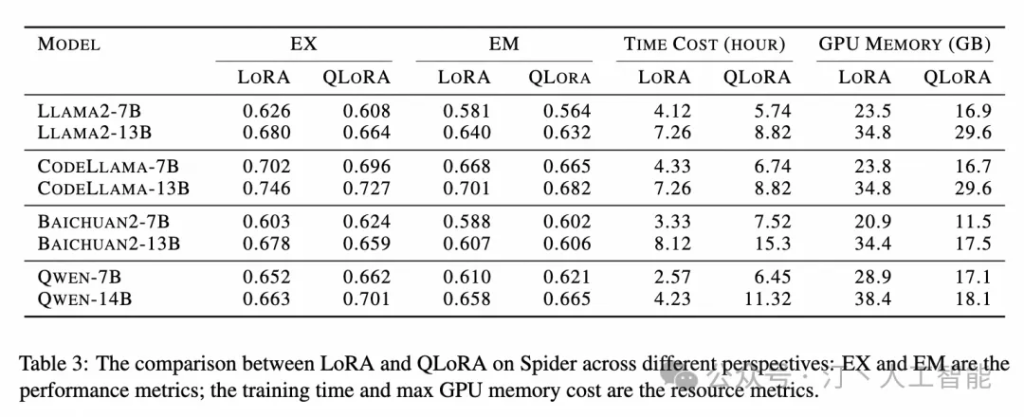
如下表所示,總結(jié) Lora 和 QLora 在 EX、EM、時間成本和 GPU 內(nèi)存指標(biāo)之間的差異。首先,發(fā)現(xiàn)使用 LoRA 和 QLoRA 調(diào)整的模型在生成性能(以 EX 和 EM 衡量)方面差異有限。其次,與量化機制一致,QLoRA 需要更多時間才能收斂,而 GPU 內(nèi)存較少。例如,與 Qwen-14B-LoRA 相比,其 QLoRA 對應(yīng)模型僅需要 2 倍的時間和 50%GPU 內(nèi)存
本文章轉(zhuǎn)載微信公眾號@汀丶人工智能







