
如何快速實現REST API集成以優化業務流程
論文地址:https://arxiv.org/pdf/2403.05313
Github地址:https://github.com/CraftJarvis/RAT
Demo地址:https://huggingface.co/spaces/jeasinema/RAT
北京大學、加州大學洛杉磯分校和北京通用人工智能研究院的研究人員探索如何在信息檢索的幫助下迭代修改思想鏈提高大型語言模型在長生成任務中的推理和生成能力,同時極大地減輕幻覺。特別是,所提出的方法——檢索增強的思想(RAT):利用檢索到的與任務查詢相關的信息逐一修正每個思考步驟,在生成初始零樣本CoT之后,將RAT應用于GPT-3.5、GPT-4和CodeLLaMA-7b大大提高了它們在各種長期范圍內的性能生成任務;平均而言,代碼生成的評分相對提高了13.63%,16.96%在數學推理方面,19.2%的人在創造性寫作方面,42.78%的人在具體任務計劃方面。
? ? ? ?大語言模型(LLM)在各種自然語言推理任務上取得了豐碩的進展,尤其是當將大模型與復雜的提示策略相結合時,比如思維鏈(CoT)提示。然而,人們越來越擔心LLM推理的事實正確性,經常會出現所謂的“幻覺”(hallucination)——模型會生成看似合理但實際上并不準確的信息,尤其是在長任務推理中。當涉及到零樣本CoT提示時,這個問題變得更加重要。“let’s think step-by-step”和需要多步驟和上下文感知推理的長期生成任務,包括代碼生成、任務規劃、數學推理等。事實上有效的中間思想可能對成功完成這些任務至關重要。
? ? ? ?為解決長任務推理問題,研究人員提出了各種方法旨在改進 LLM 的推理過程。一些較早的方法嘗試將外部信息檢索與模型生成的內容相結合,以確保模型輸出的事實準確性。然而,這些方法通常無法動態地改進推理過程,導致產生的結果雖然有所改善,卻仍然未能達到理想的上下文理解和準確性水平。
? ? ? ?來自北京大學、加州大學洛杉磯分校和北京通用人工智能研究院的研究人員提出的 Retrieval Augmented Thoughts (RAT) 方法,直覺是幻覺在中間推理過程可以通過外部知識的幫助來緩解,RAT旨在直接解決 LLM 中的事實準確性問題,如圖1所示:
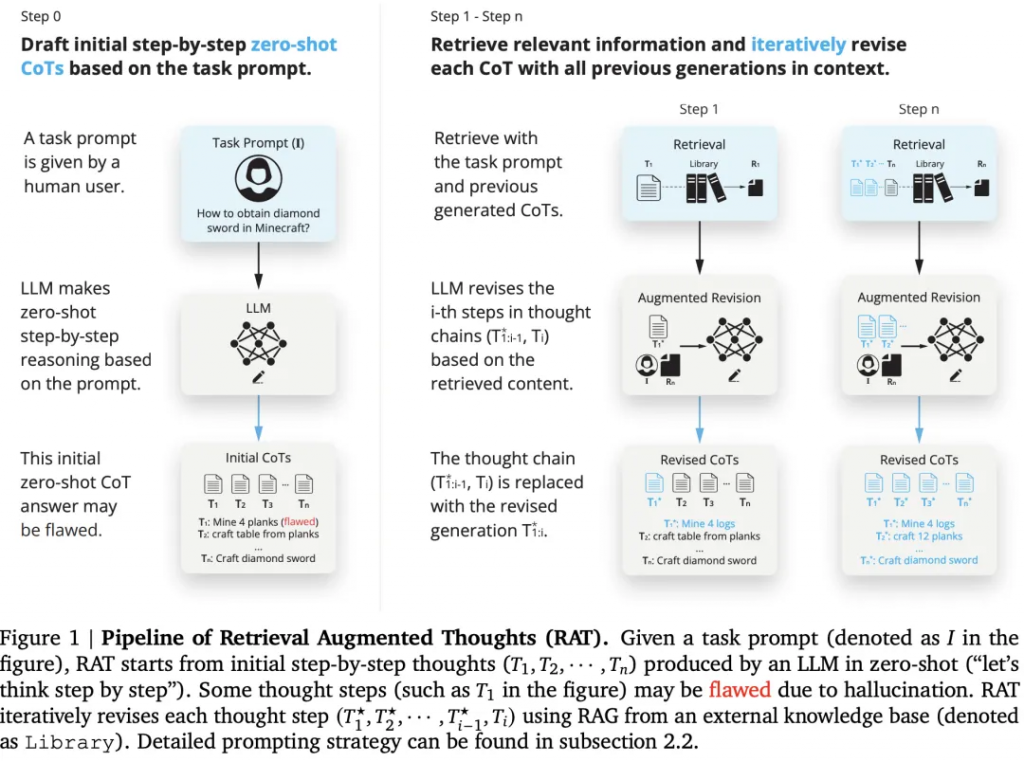
首先,LLM產生的初始零樣本CoT以及原始任務提示將被用作查詢,以檢索可能有助于修改可能有缺陷的CoT的信息。其次,設計一種漸進的方法,而不是用完整的CoT進行檢索和修改并立即產生最終響應,其中LLM在CoT(一系列子任務)之后逐步生成響應,并且只有當前思維步驟將根據任務提示檢索到的信息、當前和過去的CoT進行修改。這種策略可以類比于人類的推理過程:在復雜的長期問題解決過程中,利用外部知識來調整我們的逐步思維。RAT和其他技術的對比,如圖2所示:
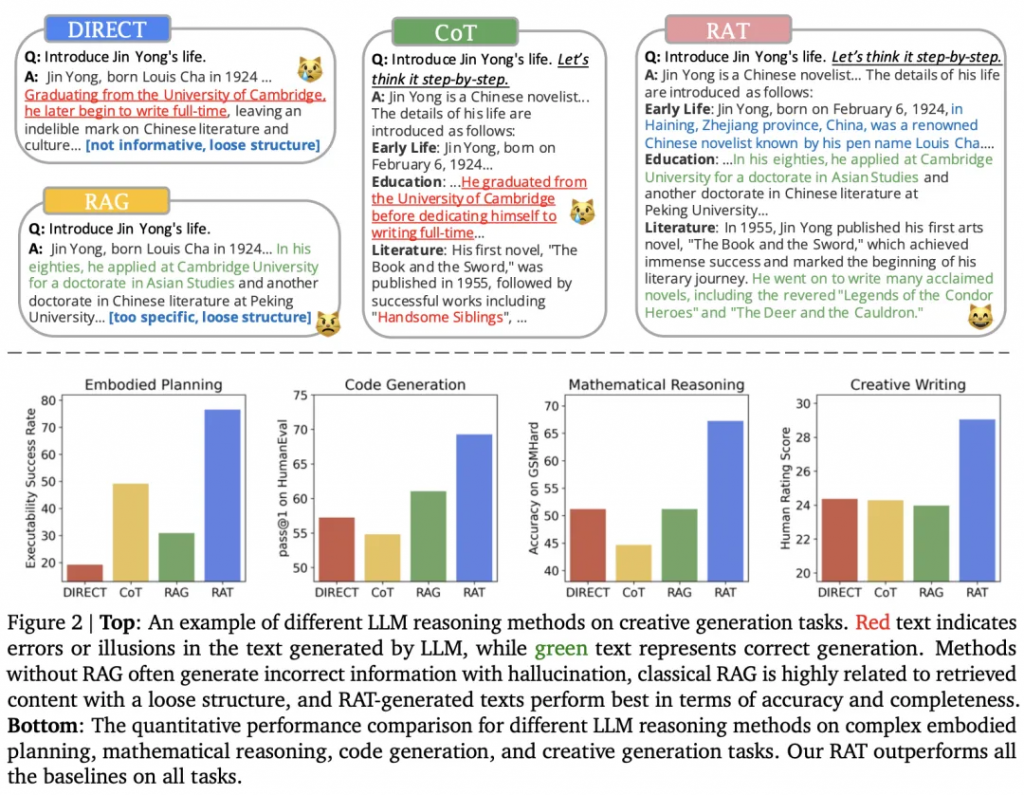
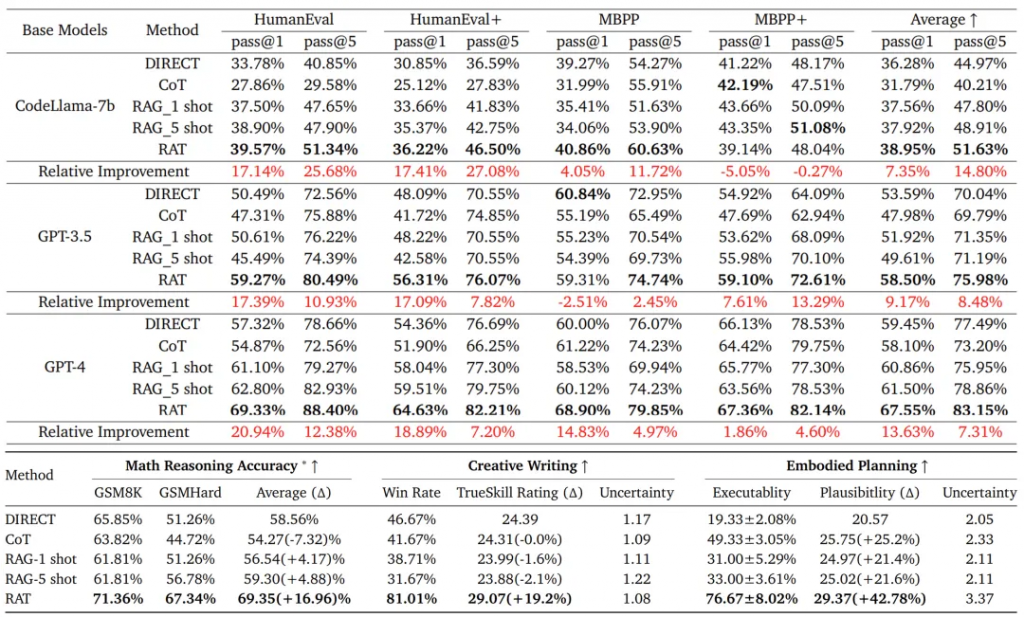
論文在一系列具有挑戰性的長期任務中評估RAT,包括代碼生成、數學推理、具體任務規劃和創造性寫作,使用了幾種不同規模的LLM:GPT-3.5、GPT-4、CodeLLaMA-7b。結果表明:與vanilla CoT提示和RAG方法相比,將RAT與這些LLM相結合具有強大的優勢,在如下任務中達到SOTA性能水平:
1)代碼生成:HumanEval(+20.94%)、HumanEval+(+18.89%)、MBPP(+14.83%)、MBPP+(+1.86%);
2) 數學推理問題:GSM8K(+8.36%)和GSMHard(+31.37%);
3) Minecraft任務規劃:(可執行性提高到2.96倍,合理性增加+51.94%);
4) 創造性寫作:(超過人類得分+19.19%)。
? ? ? 消融實驗研究進一步證實了RAT的兩個關鍵成分所起的關鍵作用:1)使用RAG修正CoT和2)逐步修正和生成。這項工作揭示了LLM如何修改他們的推理在外部知識的幫助下,以零樣本的方式進行過程,就像人類所做的那樣。

使用RAG修正CoT產生的每一個思維步驟提示,算法如圖1和算法1所示。具體來說,給定任務提示I、 我們首先讓LLM以zero-shot(“let’s think step-by-step”)逐步生成思考??,???? 代表第??步思考。在長生成任務中,?? 可以是中間推理步驟,例如代碼生成中帶有注釋的偽代碼,創造性寫作中的文章提綱等,或草稿響應本身,例如包含的子目標列表任務規劃,如圖1所示。
? ? ? ?由于?? 可能有缺陷(例如,包含幻覺),因此需要繼續使用RAG來修改生成思想步驟,然后根據這些思想生成最終響應。具體來說,假設已經修復了之前的思考步驟現在即將修訂??,我們首先將文本??轉換到查詢中????,公式如下所示:
???? = ToQuery( ),
? ? ? ?其中ToQuery(·)可以是文本編碼器,也可以是轉換任務提示I,當前和過去的思維步驟??為檢索系統處理的一個查詢???? 。作者采用RAG使用????檢索相關文件????,最后生成修改后的思考步驟提示??
? ? ? ?最后,根據實際任務,修訂思維步驟??可以簡單地用作最后模型的響應,例如具體任務規劃。對于代碼生成或創造性寫作等任務,LLM將被進一步提示生成每個人的完整回應(代碼、段落)逐步修正思想步驟。
? ? ? ?在修正第??個思考步驟????,而不是僅使用當前步驟????,或完整的思想鏈??來生成RAG的查詢,我們確保查詢????由當前的思維步驟????以及之前修改的思維步驟??生成的。即我們使用RAG采用因果推理來修正思想,公式如下所示:
???? = ToQuery( ),
本文章轉載微信公眾號@ArronAI







