
如何快速實現(xiàn)REST API集成以優(yōu)化業(yè)務(wù)流程
接下來就有一下問題:如何合并這樣子查詢的答案呢?
簡單地說,我們可以將檢索到的文檔集連接起來,并在生成答案時將它們作為上下文提供給LLM。我們可能完全不知道我們展示檢索到的文檔的順序。或者,我們可以做得更好。
在LlamaIndex中提供了Sub Question Query Engine[2]來提升RAG檢索性能。對于每個檢索到的文檔集,都會生成相應(yīng)子問題的答案。然后,LLM會根據(jù)這些子答案,而不是檢索到的文檔本身,得出最終答案。
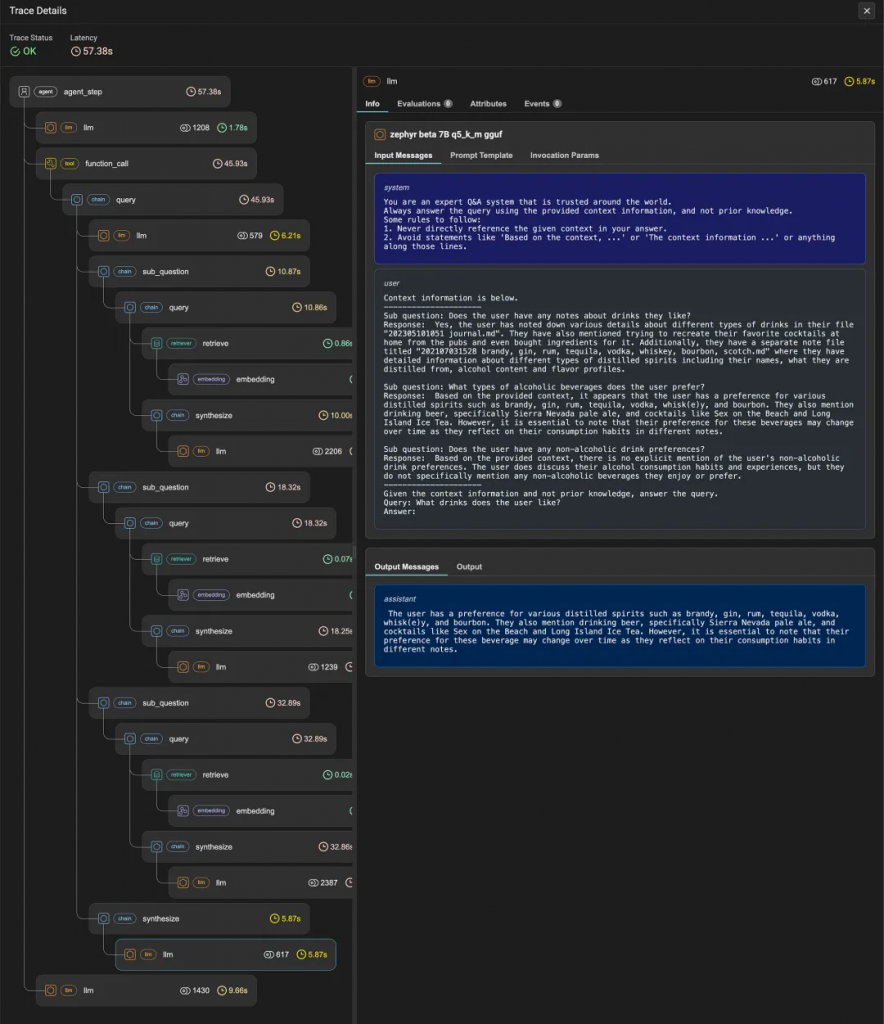
RAG-Fusion[3]仍然將文檔作為上下文提供給LLM。首先,它根據(jù)每個文檔出現(xiàn)的回憶集數(shù)量對文檔進(jìn)行排序。這種技術(shù)被稱為Reciprocal Rank Fusion (RRF)。RRF假設(shè):
RRF允許人們通過不同的搜索方法來組合結(jié)果,這種模式通常被稱為“混合搜索”。
提供給RRF的各種搜索方法的不同之處僅在于它們?nèi)绾蔚竭_(dá)它們的回憶集,而不是具有可供選擇的不相交的文檔集。至關(guān)重要的是,文檔首先必須有機(jī)會出現(xiàn)在單獨(dú)的回憶集中,然后才能通過相互出現(xiàn)來重新排序。
RAG-end2nd[8]提出了Dense Passage Retrieval(DPR;“RAG”中的“R”)方法,對編碼器(比如BERTs)進(jìn)行一些微調(diào),性能超過BM25 25%。
LoRA是大模型微調(diào)的技術(shù)之一,它來自論文《LoRA: Low-Rank Adaptation of Large Language Models》[9],基本原理是凍結(jié)大模型參數(shù),在原始模型中添加少量的可訓(xùn)練參數(shù)AB矩陣來適應(yīng)特定領(lǐng)域知識,由于微調(diào)的參數(shù)量較少,比較適合低資源的場景和用戶。
在這篇短文中,回顧了四種提高RAG管道相關(guān)性的技術(shù)。其中兩種依賴于分解原始查詢并利用LLM的生成能力,而另外兩種則致力于利用特定領(lǐng)域的知識進(jìn)一步增強(qiáng)模型本身。
[1] https://lmy.medium.com/four-ways-to-improve-the-retrieval-of-a-rag-system-91626ab2ad65
[2] https://docs.llamaindex.ai/en/stable/examples/query_engine/sub_question_query_engine.html
[3] https://github.com/Raudaschl/rag-fusion
[4] https://learn.microsoft.com/en-us/azure/search/hybrid-search-overview
[5] https://eugeneyan.com/writing/obsidian-copilot/
[6] https://obsidian.md/
[7] https://www.pinecone.io/learn/hybrid-search-intro/
[8] https://arxiv.org/abs/2210.02627
[9] https://arxiv.org/abs/2106.09685
本文章轉(zhuǎn)載微信公眾號@ArronAI



鍵.png)



