
如何快速實現REST API集成以優化業務流程
本文對文本RAG涉及到的主要12種關鍵“超參數”進行簡單總結,主要包括攝取階段(數據清洗、數據分塊、embedding模型選擇、元數據過濾、多重索引和索引算法)和推理階段【檢索和生成】(查詢轉換、檢索參數、高級檢索策略、重排序、大模型和Prompt工程)。下面將分別進行介紹:
? ? ? ?攝取階段是構建RAG管道的準備步驟,類似于ML管道中的數據清理和預處理步驟。通常,攝入階段包括以下步驟:
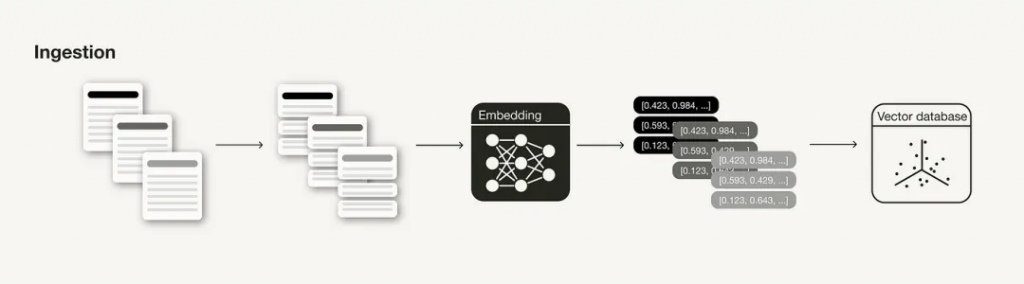
? ? ? ?與任何數據科學管道一樣,數據的質量嚴重影響RAG管道的結果。在繼續執行以下任何步驟之前,請確保您的數據符合以下標準:
1)數據干凈:可以應用一些自然語言處理中常用的基本數據清理技術,例如確保所有特殊字符都正確編碼;
2)數據準確:確保信息一致且事實準確,以避免信息沖突誤導LLM
對文檔進行分塊是RAG管道中引入外部知識源的一個重要準備步驟,通常是將長文檔分解成更小的部分(但它也可以將較小的片段組合成連貫的段落)。
在LangChain中,支持不同的text splitters[1],比如字符、令牌等。這取決于您擁有的數據類型,例如,如果您的輸入數據是代碼,而不是Markdown文件,則需要使用不同的分塊技術。
塊的理想長度(chunk_size)取決于具體用例:如果你的用例是問答,你可能需要更短的塊;但如果你的案例是摘要,你可能會需要更長的塊。此外,如果一個區塊太短,它可能沒有包含足夠的上下文。另一方面,如果一個塊太長,它可能包含太多不相關的信息。
此外,還需要考慮塊(重疊)之間的“滾動窗口”,這樣可以保證塊之間的語義連貫性。
嵌入模型是檢索的核心,嵌入的質量嚴重影響檢索結果。通常,生成嵌入的維度越高,嵌入的精度就越高。
可以在 Massive Text Embedding Benchmark (MTEB)排行榜[2]查看可用的文本嵌入模型,該排行榜涵蓋164個文本嵌入模型(在撰寫本文時)。
雖然可以開箱即用地使用通用嵌入模型,但在某些情況下,可以根據用戶的特定用例微調嵌入模型,這樣可以避免領域外問題。根據LlamaIndex進行的實驗,微調嵌入模型可以使檢索評估指標的性能提高5%-10%。
請注意,無法對所有嵌入模型進行微調(例如,OpenAI的text-ebmedding-ada-002目前無法進行微調)。
將矢量嵌入存儲在矢量數據庫中時,某些矢量數據庫允許將它們與元數據(或未矢量化的數據)一起存儲。用元數據注釋矢量嵌入有助于對搜索結果進行額外的后處理,如元數據過濾(添加元數據,如日期、章節或分章引用)。
如果元數據不足以提供額外的信息來從邏輯上分離不同類型的上下文,可能需要嘗試使用多個索引,例如,可以對不同類型的文檔使用不同的索引。
為了實現大規模相似性搜索,矢量數據庫和矢量索引庫使用近似最近鄰(ANN)搜索,而不是k最近鄰(kNN)搜索。顧名思義,ANN算法近似于最近的鄰居,因此可能不如kNN算法精確。
這里有不同的ANN算法可以參考,如Facebook Faiss[3](聚類)、Spotify Annoy[4](樹)、Google ScaNN[5](矢量壓縮)和HNSWLIB[6](接近圖)。此外,這些ANN算法中的許多都有一些參數可以調整,例如HNSW[1]的ef、efConstruction和maxConnections。
此外,還可以為這些索引算法啟用矢量壓縮。與人工神經網絡算法類似,矢量壓縮會損失一些精度。然而,根據矢量壓縮算法的選擇及其調整,也可以對此進行優化。
? ? ? 然而,這些參數已經由向量數據庫和向量索引庫的研究團隊在基準測試實驗期間進行了調整,而不是由RAG系統的開發人員進行調整。然而,如果想自己嘗試使用這些參數來壓榨一點性能,建議可以參考這篇文章[7]。
? ? ? ?RAG管道的主要組成部分是檢索和生成組成部分。本節主要討論改進檢索的策略(查詢轉換、檢索參數、高級檢索策略和重新排序模型),因為這是兩者中更具影響力的組成部分。也會談到了一些改進生成的策略(LLM和Prompt工程)。
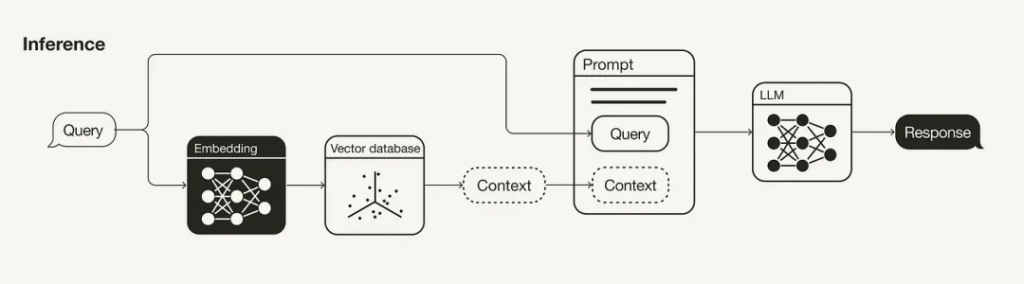
? ? ? ?由于在RAG管道中檢索附加上下文的搜索查詢也會嵌入到向量空間中,因此其措辭也會影響搜索結果。因此,如果您的搜索查詢沒有得到令人滿意的搜索結果,您可以嘗試各種查詢轉換技術[8],例如:
檢索是RAG管道的重要組成部分。首先要考慮的是語義搜索是否足以滿足您的用例,或者您是否想嘗試混合搜索[9]。
在后一種情況下,需要在混合搜索中對稀疏和密集檢索方法的聚合進行加權實驗。因此,有必要調整參數alpha,該參數控制語義(alpha=1)和基于關鍵字的搜索(alpha=0)之間的權重。
此外,要檢索的搜索結果的數量也將發揮重要作用。檢索到的上下文的數量將影響所用上下文窗口的長度。此外,如果您使用的是重新排序模型,則需要考慮向該模型輸入多少上下文。
請注意,雖然用于語義搜索的所用相似性度量是一個可以更改的參數,不需要進行實驗,而應該根據所使用的嵌入模型進行設置(例如,text-embedding-ada-002支持余弦相似性或multi-qa-MiniLM-l6-cos-v1支持余弦相似、點積和歐幾里得距離)。
本節的基本思想是,用于檢索的塊不一定與用于生成的塊相同。理想情況下,應該嵌入較小的塊便于檢索,而應該檢索較大的上下文。
雖然語義搜索根據上下文與搜索查詢的語義相似性來檢索上下文,但“最相似”并不一定意味著“最相關”。重新排序模型,如Cohere[10]的重新排序模型可以通過計算每個檢索到的上下文的查詢相關性得分來幫助消除不相關的搜索結果。
|“most similar” doesn’t necessarily mean “most relevant”
? ? ? ?如果使用的是重新排序器模型,則可能需要重新調整重新排序器輸入的搜索結果數量,以及希望將多少重新排序的結果輸入LLM。
與嵌入模型一樣,同樣可以對重新排序器進行微調。
? ? ? ?LLM是生成響應的核心組件,根據用戶的需求,可以有多種LLM可供選擇,可以考慮例如開源模型或專有模型、推理成本、上下文長度等因素來選擇大模型。
? ? ? ?如何表達或設計你的提示將對LLM的完成產生重大影響。此外,在提示中使用一些few-shot示例可以提高生成的質量。
? ? ? ?如Retrieval parameters中所述,輸入到提示中的上下文數量是一個超參數。雖然RAG管道的性能可以隨著相關上下文的增加而提高,但如果相關上下文位于許多上下文的中間,則LLM也不會識別相關上下文,因此也可能會遇到“中間丟失”效應。
參考文獻:
[1] https://python.langchain.com/docs/modules/data_connection/document_transformers/
[2] https://huggingface.co/spaces/mteb/leaderboard
[3] https://github.com/facebookresearch/faiss
[4] https://github.com/spotify/annoy
[5] https://github.com/google-research/google-research/tree/master/scann
[6] https://github.com/nmslib/hnswlib
[7] https://weaviate.io/blog/rag-evaluation?source=post_page—–7ca646833439——————————–#indexing-knobs
[8] https://gpt-index.readthedocs.io/en/v0.6.9/how_to/query/query_transformations.html
[9] https://towardsdatascience.com/improving-retrieval-performance-in-rag-pipelines-with-hybrid-search-c75203c2f2f5?source=post_page—–7ca646833439——————————–
[10]?https://cohere.com/rerank?ref=txt.cohere.com&__hstc=14363112.8fc20f6b1a1ad8c0f80dcfed3741d271.1697800567394.1701091033915.1701173515537.7&__hssc=14363112.1.1701173515537&__hsfp=3638092843
本文章轉載微信公眾號@ArronAI







