
如何快速實現(xiàn)REST API集成以優(yōu)化業(yè)務(wù)流程
#import required libraries
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate)
#
import chainlit as cl
import PyPDF2
from io import BytesIO
from getpass import getpass
#
import os
from configparser import ConfigParser
env_config = ConfigParser()
# Retrieve the openai key from the environmental variables
def read_config(parser: ConfigParser, location: str) -> None:
assert parser.read(location), f"Could not read config {location}"
#
CONFIG_FILE = os.path.join("./env", "env.conf")
read_config(env_config, CONFIG_FILE)
api_key = env_config.get("openai", "api_key").strip()
#
os.environ["OPENAI_API_KEY"] = api_key
# Chunking the text
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=100)
#
#system template
system_template = """Use the following pieces of context to answer the user's question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
ALWAYS return a "SOURCES" part in your answer.
The "SOURCES" part should be a reference to the source of the document from which you got your answer.
Begin!
----------------
{summaries}"""
messages = [SystemMessagePromptTemplate.from_template(system_template),HumanMessagePromptTemplate.from_template("{question}"),]
prompt = ChatPromptTemplate.from_messages(messages)
chain_type_kwargs = {"prompt": prompt}
#Decorator to react to the user websocket connection event.
@cl.on_chat_start
async def init():
files = None
# Wait for the user to upload a PDF file
while files is None:
files = await cl.AskFileMessage(
content="Please upload a PDF file to begin!",
accept=["application/pdf"],
).send()
file = files[0]
msg = cl.Message(content=f"Processing {file.name}...")
await msg.send()
# Read the PDF file
pdf_stream = BytesIO(file.content)
pdf = PyPDF2.PdfReader(pdf_stream)
pdf_text = ""
for page in pdf.pages:
pdf_text += page.extract_text()
# Split the text into chunks
texts = text_splitter.split_text(pdf_text)
# Create metadata for each chunk
metadatas = [{"source": f"{i}-pl"} for i in range(len(texts))]
# Create a Chroma vector store
embeddings = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
docsearch = await cl.make_async(Chroma.from_texts)(
texts, embeddings, metadatas=metadatas
)
# Create a chain that uses the Chroma vector store
chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0,
openai_api_key=os.environ["OPENAI_API_KEY"]),
chain_type="stuff",
retriever=docsearch.as_retriever(),
)
# Save the metadata and texts in the user session
cl.user_session.set("metadatas", metadatas)
cl.user_session.set("texts", texts)
# Let the user know that the system is ready
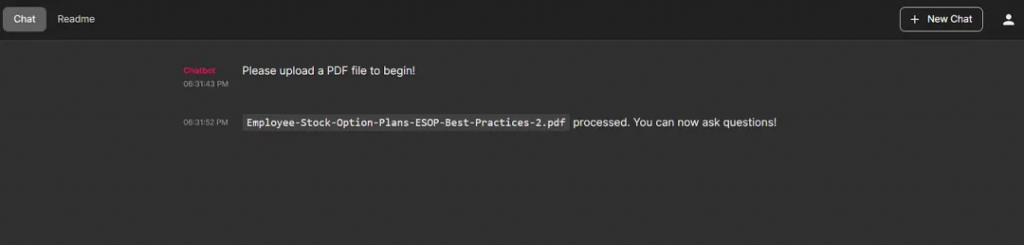
msg.content = f"{file.name} processed. You can now ask questions!"
await msg.update()
cl.user_session.set("chain", chain)
# react to messages coming from the UI
@cl.on_message
async def process_response(res):
chain = cl.user_session.get("chain") # type: RetrievalQAWithSourcesChain
cb = cl.AsyncLangchainCallbackHandler(
stream_final_answer=True, answer_prefix_tokens=["FINAL", "ANSWER"])
cb.answer_reached = True
res = await chain.acall(res, callbacks=[cb])
print(f"response: {res}")
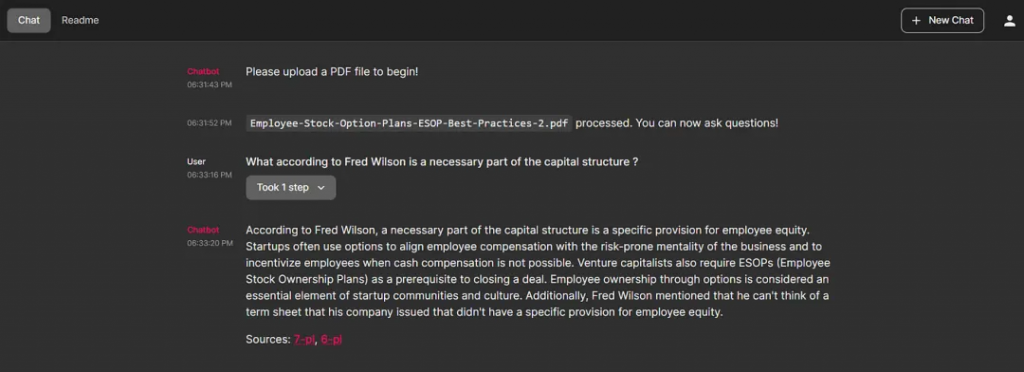
answer = res["answer"]
sources = res["sources"].strip()
source_elements = []
# Get the metadata and texts from the user session
metadatas = cl.user_session.get("metadatas")
all_sources = [m["source"] for m in metadatas]
texts = cl.user_session.get("texts")
if sources:
found_sources = []
# Add the sources to the message
for source in sources.split(","):
source_name = source.strip().replace(".", "")
# Get the index of the source
try:
index = all_sources.index(source_name)
except ValueError:
continue
text = texts[index]
found_sources.append(source_name)
# Create the text element referenced in the message
source_elements.append(cl.Text(content=text, name=source_name))
if found_sources:
answer += f"\nSources: {', '.join(found_sources)}"
else:
answer += "\nNo sources found"
if cb.has_streamed_final_answer:
cb.final_stream.elements = source_elements
await cb.final_stream.update()
else:
await cl.Message(content=answer, elements=source_elements).send()chainlit run <name of the python script>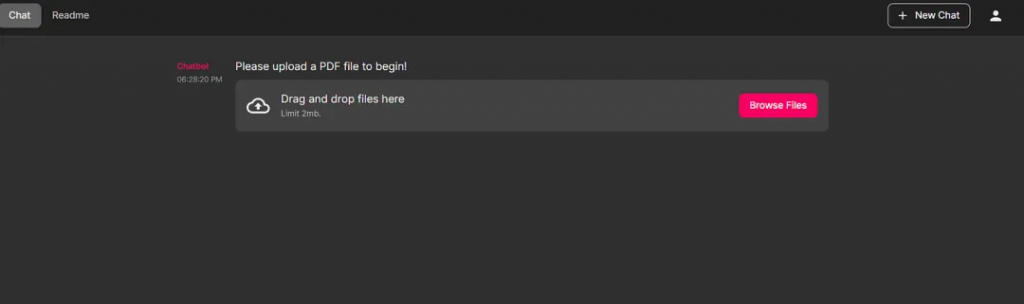
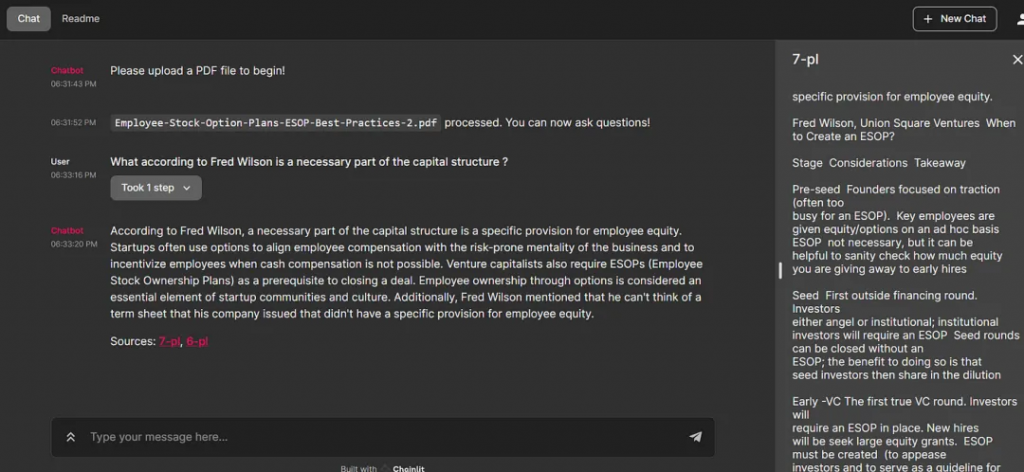
點擊返回的頁碼,詳細(xì)說明所引用的文檔內(nèi)容。
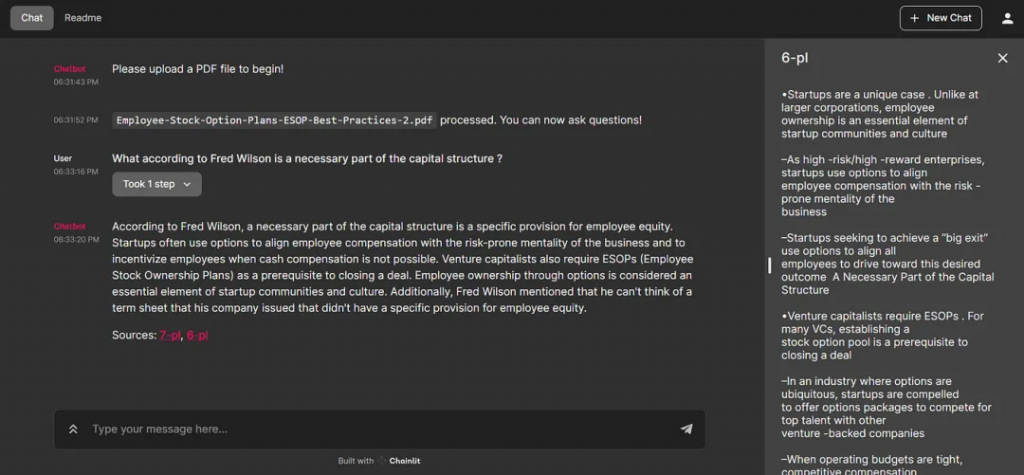
我們也可以更改設(shè)置。

[1]?https://medium.aiplanet.com/building-llm-application-for-document-question-answering-using-chainlit-d15d10469069
文章轉(zhuǎn)自微信公眾號@ArronAI



鍵.png)



