
如何快速實現REST API集成以優化業務流程
LangChain 從兩個方面幫助我們做到這一點:
– 整合,將外部數據,如本地文件、其他應用程序和api數據,輸入指定LLM
– 代理,允許LLMs通過決策與它所處環境互動,使用LLMs來幫助決定下一步要采取的行動,類似RPA
LangChain 的優點:
– 組件化,LangChain 容易替換語言模型需要的抽象和組件
– 自定義鏈,LangChain 為使用和自定義”chain”(串在一起的一系列actions)提供了開箱即用的支持
– 更新快,LangChain 團隊更新速度非常快,開發者更快體驗最新的LLM功能。
– 社區支持,精彩的討論交流區和社區支持
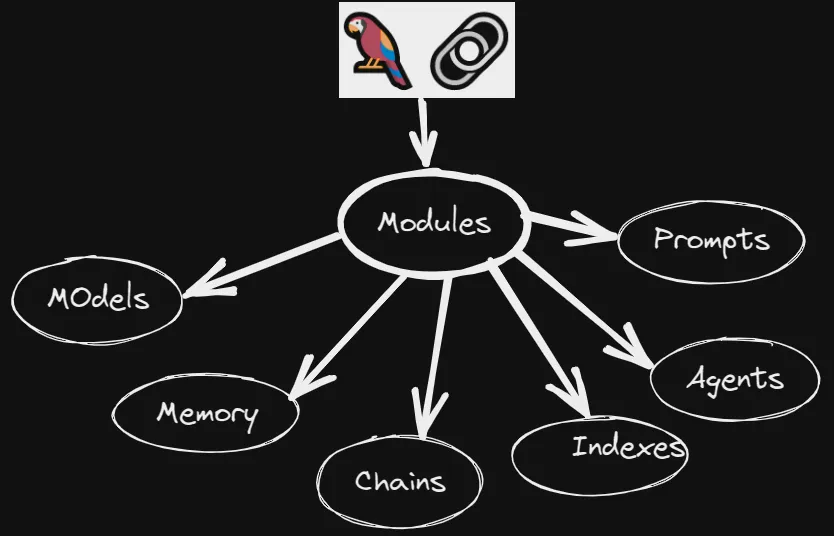
LangChain將構建語言模型驅動的應用程序中必要組件或過程模塊化,包括提示模塊(Prompts)、代理模塊(Agents)、模型(Models)、記憶模塊(Memory)、鏈(Chains)、文本處理與向量存貯與索引模塊(Indexes),極大提高開發效率。
前置環節,設置openai?key
import os
os.environ["OPENAI_API_KEY"] = "..."2.1.1 Text —— 字符串
以自然語言字符串作為LLMs輸入
my_text = "What day comes after Friday?"指定消息所屬角色類別 (System, Human, AI)
– System – 告訴AI所處背景環境以及要去做的事情的背景信息
– Human – 人類用戶信息
– AI?–?AI回答信息
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
chat = ChatOpenAI(temperature=.7)
chat(
[
SystemMessage(content="You are a nice AI bot that helps a user figure out what to eat in one short sentence"),
HumanMessage(content="I like tomatoes, what should I eat?")
]
)
# 輸出
# AIMessage(content='You could try making a tomato salad with fresh basil and mozzarella cheese.', additional_kwargs={})也可增加和AI的聊天記錄,例如
chat(
[
SystemMessage(content="You are a nice AI bot that helps a user figure out where to travel in one short sentence"),
HumanMessage(content="I like the beaches where should I go?"),
AIMessage(content="You should go to Nice, France"),
HumanMessage(content="What else should I do when I'm there?")
]
)
# 輸出
# AIMessage(content='You can take a stroll along the Promenade des Anglais, visit the historic Castle Hill, and explore the colorful Old Town.', additional_kwargs={}2.1.3 Documents —— 文檔
以文檔形式保存文本塊(chunks)及其所屬信息的對象
from langchain.schema import Document
Document(page_content="This is my document. It is full of text that I've gathered from other places",
metadata={
'my_document_id' : 234234,
'my_document_source' : "The LangChain Papers",
'my_document_create_time' : 1680013019
})# 輸出
Document(page_content="This is my document. It is full of text that I've gathered from other places", metadata={'my_document_id': 234234, 'my_document_source': 'The LangChain Papers', 'my_document_create_time': 1680013019})2.2.1?Language?Model?——?輸入輸出均為文本
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-ada-001")
llm("What day comes after Friday?")
# 輸出: '\n\nSaturday.'2.2.2?Chat?Model?——?輸入一系列文本消息,輸出文本消息
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
chat = ChatOpenAI(temperature=1)
chat(
[
SystemMessage(content="You are an unhelpful AI bot that makes a joke at whatever the user says"),
HumanMessage(content="I would like to go to New York, how should I do this?")
]
)
# 輸出
# AIMessage(content="Have you tried walking there? It's only a couple thousand miles or so.", additional_kwargs={})2.2.3?Text?Embedding?Model?——?文本向量化
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text = "Hi! It's time for the beach"
text_embedding = embeddings.embed_query(text)
print (f"Your embedding is length {len(text_embedding)}")
print (f"Here's a sample: {text_embedding[:5]}...")# 輸出
Your embedding is length 1536
Here's a sample: [-0.00017436751566710776, -0.0031537775329516507, -0.0007205927056327557, -0.019407861884521316, -0.015138132716961442]...2.3.1?Prompt?——?傳遞給底層模型的提示內容
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003")
# I like to use three double quotation marks for my prompts because it's easier to read
prompt = """
Today is Monday, tomorrow is Wednesday.
What is wrong with that statement?
"""
llm(prompt)
# 輸出
# '\nThe statement is incorrect. The day after Monday is Tuesday.'2.3.2 Prompt Template —— 提示模板
Prompt Template是一個根據用戶輸入、非靜態信息和固定模板字符串組合創建提示的對象,可動態傳入變量。
from langchain.llms import OpenAI
from langchain import PromptTemplate
llm = OpenAI(model_name="text-davinci-003")
# Notice "location" below, that is a placeholder for another value later
template = """
I really want to travel to {location}. What should I do there?
Respond in one short sentence
"""
prompt = PromptTemplate(
input_variables=["location"],
template=template,
)
final_prompt = prompt.format(location='Rome')
print (f"Final Prompt: {final_prompt}")
print ("-----------")
print (f"LLM Output: {llm(final_prompt)}")Final Prompt:
I really want to travel to Rome. What should I do there?
Respond in one short sentence
-----------
LLM Output: Visit the Colosseum, the Trevi Fountain, St. Peter's Basilica, and the Pantheon.2.3.3 Example Selectors —— 相似例子選擇
輸入一組例子,再從給定大量例子中選擇相近例子,允許動態內容以傳參形式寫入提示內容。
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003")
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Example Input: {input}\nExample Output: {output}",
)
# Examples of locations that nouns are found
examples = [
{"input": "pirate", "output": "ship"},
{"input": "pilot", "output": "plane"},
{"input": "driver", "output": "car"},
{"input": "tree", "output": "ground"},
{"input": "bird", "output": "nest"},
]
# SemanticSimilarityExampleSelector will select examples that are similar to your input by semantic meaning
example_selector = SemanticSimilarityExampleSelector.from_examples(
# This is the list of examples available to select from.
examples,
# This is the embedding class used to produce embeddings which are used to measure semantic similarity.
OpenAIEmbeddings(),
# This is the VectorStore class that is used to store the embeddings and do a similarity search over.
FAISS,
# This is the number of examples to produce.
k=2
)
similar_prompt = FewShotPromptTemplate(
# The object that will help select examples
example_selector=example_selector,
# Your prompt
example_prompt=example_prompt,
# Customizations that will be added to the top and bottom of your prompt
prefix="Give the location an item is usually found in",
suffix="Input: {noun}\nOutput:",
# What inputs your prompt will receive
input_variables=["noun"],
)
# Select a noun!
my_noun = "student"
print(similar_prompt.format(noun=my_noun))
llm(similar_prompt.format(noun=my_noun))Give the location an item is usually found in
Example Input: driver
Example Output: car
Example Input: pilot
Example Output: plane
Input: student
Output:
' classroom'2.3.4?Output Parsers —— 格式化輸出對模型輸出的結果進行格式化處理,用于要求輸出數據結構化的場景,包含格式說明(Format Instructions)和解析器(Parser)兩個概念。Format Instructions 通過描述生成prompt,告訴LLMs按需格式化模型輸出;Parser 將模型輸出結果結構化包裝,例如將字符結果轉json。以下代碼指定LLM輸出格式,并通過描述生成提示詞,讓模型對輸入存在問題的文本實現格式矯正,并結輸出結構化數據。
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003")
# How you would like your reponse structured. This is basically a fancy prompt template
response_schemas = [
ResponseSchema(name="bad_string", description="This a poorly formatted user input string"),
ResponseSchema(name="good_string", description="This is your response, a reformatted response")
]
# How you would like to parse your output
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
# See the prompt template you created for formatting
format_instructions = output_parser.get_format_instructions()
print (format_instructions)
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
prompt = PromptTemplate(
input_variables=["user_input"],
partial_variables={"format_instructions": format_instructions},
template=template
)
promptValue = prompt.format(user_input="welcom to califonya!")
print(promptValue)
llm_output = llm(promptValue)
print(llm_output)
output_parser.parse(llm_output)The output should be a markdown code snippet formatted in the following schema:
```json
{
"bad_string": string // This a poorly formatted user input string
"good_string": string // This is your response, a reformatted response
}
```
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
The output should be a markdown code snippet formatted in the following schema:
```json
{
"bad_string": string // This a poorly formatted user input string
"good_string": string // This is your response, a reformatted response
}
```
% USER INPUT:
welcom to califonya!
YOUR RESPONSE:
```json
{
"bad_string": "welcom to califonya!",
"good_string": "Welcome to California!"
}
```
{'bad_string': 'welcom to califonya!', 'good_string': 'Welcome to California!'}2.4.1 Document?Loaders?—— 文件加載
from langchain.document_loaders import HNLoader
loader = HNLoader("https://news.ycombinator.com/item?id=34422627")
data = loader.load()
print (f"Found {len(data)} comments")
print (f"Here's a sample:\n\n{''.join([x.page_content[:150] for x in data[:2]])}")2.4.2 Text?Splitters?——?長文本分塊
from langchain.text_splitter import RecursiveCharacterTextSplitter
# This is a long document we can split up.
with open('data/interview.txt') as f:
pg_work = f.read()
print (f"You have {len([pg_work])} document")
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 150,
chunk_overlap = 20,
)
texts = text_splitter.create_documents([pg_work])
print (f"You have {len(texts)} documents")2.4.3?Retrievers?——?檢索推薦
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
loader = TextLoader('data/interview.txt')
documents = loader.load()
# Get your splitter ready
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
# Split your docs into texts
texts = text_splitter.split_documents(documents)
# Get embedding engine ready
embeddings = OpenAIEmbeddings()
# Embedd your texts
db = FAISS.from_documents(texts, embeddings)
# Init your retriever. Asking for just 1 document back
retriever = db.as_retriever()
docs = retriever.get_relevant_documents("what types of things did the author want to build?")
print("\n\n".join([x.page_content[:200] for x in docs[:1]]))2.4.4 VectorStores —— 向量存貯
數據向量化存貯數據庫,如Pinecome、Weaviate等,Chroma、Faiss易于本地使用。存貯內部包含Embedding和Metadata如下
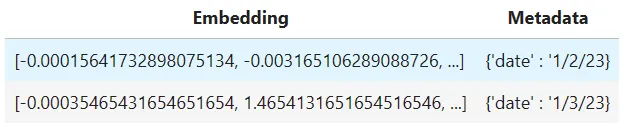
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
loader = TextLoader('data/interview.txt')
documents = loader.load()
# Get your splitter ready
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
# Split your docs into texts
texts = text_splitter.split_documents(documents)
# Get embedding engine ready
embeddings = OpenAIEmbeddings()
embedding_list = embeddings.embed_documents([text.page_content for text in texts])
print (f"You have {len(embedding_list)} embeddings")
print (f"Here's a sample of one: {embedding_list[0][:3]}...")You have 29 embeddings
Here's a sample of one: [0.02098408779071363, -0.00444188727815012, 0.029791279689326114]...給模型注入歷史信息,幫助他回憶有用信息,這里對記憶并沒有嚴格定義,可以是過去的對話信息,也可以是復雜的信息檢索,應用于聊天機器人,分長期和短期記憶,以便確定適合自己場景的類型。ChatMessageHistory類負責記住所有以前的聊天交互。然后,這些可以直接傳遞回模型,以某種方式總結,或某種組合。
from langchain.memory import ChatMessageHistory
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0)
history = ChatMessageHistory()
history.add_ai_message("hi!")
history.add_user_message("what is the capital of france?")
ai_response = chat(history.messages)
history.add_ai_message(ai_response.content)
history.messages[AIMessage(content='hi!', additional_kwargs={}),
HumanMessage(content='what is the capital of france?', additional_kwargs={}),
AIMessage(content='The capital of France is Paris.', additional_kwargs={})]Chains 涉及的概念和實際用途均很廣,可抽象理解為對模組及其行為的序列化封裝,實現特定功能,可以直接使用LangChain封裝的程式,也可以自定義程式。Chains可用于輸入文本的處理轉化TransformChain;可用于處理LLMs模型間參數依賴,A模型輸出作為B模型的輸入,模型間涉及到多個輸入輸出時,分為SimpleSequentialChain 和 Sequential Chain;可用于對輸入文檔端到端的程序化處理AnalyzeDocumentChain,自動實現輸入文檔-文檔拆分-文檔總結;可用于圖譜的檢索與查詢GraphQAChain;Chain可被序列化save到disk,再通過load_chain加載。
2.6.1 Simple Sequential Chains —— 簡單有序鏈
Chains=[A, B],其中A模型輸出直接作為B模型的輸入,如下
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChain
llm = OpenAI(temperature=1)
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_location"], template=template)
# Holds my 'location' chain
location_chain = LLMChain(llm=llm, prompt=prompt_template)
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_meal"], template=template)
# Holds my 'meal' chain
meal_chain = LLMChain(llm=llm, prompt=prompt_template)
overall_chain = SimpleSequentialChain(chains=[location_chain, meal_chain], verbose=True)
review = overall_chain.run("Rome")> Entering new SimpleSequentialChain chain...
Spaghetti Carbonara, a classic Roman dish made of spaghetti, guanciale (Italian type of bacon), eggs, parmesan cheese, and black pepper.
Ingredients:
- 8 ounces of Spaghetti
- 6 ounces Guanciale (Italian bacon), diced
- 3 whole Eggs
- 2/3 cup Parmesan cheese, grated
- 2 tablespoons Fresh Ground Black Pepper
Instructions:
1. Bring a large pot of salted water to a boil, then add the spaghetti and cook according to the instructions on the packaging.
2. Meanwhile, cook the guanciale in a large skillet over medium-high heat, stirring occasionally until crispy.
3. In a medium bowl, whisk together the eggs, Parmesan cheese, and black pepper until combined.
4. Once the spaghetti is cooked, reserve 1/2 cup of the cooking liquid, then drain the spaghetti and add it to the skillet.
5. Pour the egg mixture over the spaghetti and guanciale and toss to combine.
6. Add the reserved cooking liquid to create a creamy sauce.
7. Serve and enjoy!
> Finished chain.2.6.2 Summarization Chain —— 總結鏈
使用load_summarize_chain,非常容易對長文檔內容進行總結
from langchain.chains.summarize import load_summarize_chain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
llm = OpenAI(temperature=1)
loader = TextLoader('data/interview.txt')
documents = loader.load()
# Get your splitter ready
text_splitter = RecursiveCharacterTextSplitter(chunk_size=700, chunk_overlap=50)
# Split your docs into texts
texts = text_splitter.split_documents(documents)
# There is a lot of complexity hidden in this one line.
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=True)
chain.run(texts)Agents官方定義
“Some applications will require not just a predetermined chain of calls to LLMs/other tools, but potentially an unknown chain that depends on the user’s input. In these types of chains, there is a “agent” which has access to a suite of tools. Depending on the user input, the agent can then decide which, if any, of these tools to call. ”
Agents使用LLM決定執行哪些動作以及這些動作按照什么順序執行,動作可以是使用某個工具,也可以是返回響應結果給用戶,這也說明了,LLM不僅用于文本輸出,還可用于決策制定,即LLMs可視為很好的推理引擎,這是值得大家注意的。(Agents可以作為RPA技術的替代方案)
2.7.1 Agents —— 模型裝飾器
“An Agent is a wrapper around a model, which takes in user input and returns a response corresponding to an “action” to take and a corresponding “action input”. “,Agent 接受用戶輸入、指定動作,動作輸入及響應等,其類型如下:
– zero-shot-react-description
– react-docstore
– self-ask-with-search
– conversational-react-description
2.7.2 Tools —— 代理可使用的工具
代理用于和外界交互的工具,包括自定義工具和常見通用工具,通用工具包含Bash(執行sh命令)、Bing?Search、Google?Search、ChatGPT?Plugins、Python?REPL(執行python命令)、Wikipedis?API、WolframAlpha(計算知識引擎,支持強大的數學計算功能,如因式分解、向量運算、求導、可視化、積分微分、解方程,還涉及物理、化學、生物、人文、金融等領域)、Requests、OpenWeatherMap?API(全球各城市的氣象數據,包括4天小時級、16天日級、30天預測等)、Zapier?Natural?Language?Actions?API(支持5k+?apps?和?20k+?基于自然語言理解的動作執行)、IFTTT?WebHooks、Human?as?a?tool(人機交互)、SearxNG?Search?API(自建搜索引擎及與web交互)、Apify(爬蟲與數據提取云平臺)、SerpAPI(谷歌搜索API)
以wolfram解方程為例子
import os
os.environ["WOLFRAM_ALPHA_APPID"] = ""
from langchain.utilities.wolfram_alpha import WolframAlphaAPIWrapper
wolfram = WolframAlphaAPIWrapper()
wolfram.run("What is 2x+5 = -3x + 7?")
# 輸出 'x = 2/5'2.7.3 Toolkit —— 解決特定問題的工具箱
CSV Agent(讀取CSV,并支持調用python命令,對CSV文件進行分析,例如行數、列數、數據關聯等);JSON Agent(讀取JSON,解析并查詢該json,適用于大的json文件);OpenAPI agents(構造代理來消費任意的api,這里的api符合OpenAPI/Swagger規范);Natural Language APIs(自然語言?API?工具包(NLAToolkits)允許?LangChain?代理在端點之間高效地進行計劃和組合調用)
;Pandas Dataframe Agent(和pandas交互);Python Agent(編寫python代碼,執行python腳本);SQL Database Agent(編寫sql語句,執行sql);Vectorstore Agent(支持對一個或多個向量存貯源文件的檢索)。。。
from langchain.agents import create_csv_agent
agent = create_csv_agent(OpenAI(temperature=0), 'titanic.csv', verbose=True)
agent.run("how many rows are there?")> Entering new AgentExecutor chain...
Thought: I need to count the number of rows
Action: python_repl_ast
Action Input: len(df)
Observation: 891
Thought: I now know the final answer
Final Answer: There are 891 rows in the dataframe.
> Finished chain.
# 最終結果:'There are 891 rows in the dataframe.'2.7.4 Agent Executors —— 執行與推理
代理執行者使用代理和工具,并使用代理來決定調用哪些工具以及以什么順序調用,用serpapi找出成龍第一部參演電影中的角色特點,serapi對英文檢索效果更好,因此翻譯為“What?character?did?Jackie?Chan?play?in?his?first?film?”
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
import json
serpapi_api_key = "....."
llm = OpenAI(temperature=0)
toolkit = load_tools(["serpapi"], llm=llm, serpapi_api_key=serpapi_api_key)
agent = initialize_agent(toolkit, llm, agent="zero-shot-react-description", verbose=True, return_intermediate_steps=True)
response = agent({"input":"What character did Jackie Chan play in his first film?"})
print(json.dumps(response["intermediate_steps"], indent=2))代理推理過程,先找到成龍影視作品集—>成龍第一部電影——>角色特點
> Entering new AgentExecutor chain...
I should research Jackie Chan's filmography
Action: Search
Action Input: "Jackie Chan filmography"
Observation: Jackie Chan SBS MBE PMW is a Hong Kong actor, filmmaker, martial artist, and stuntman known for his slapstick acrobatic fighting style, comic timing, and innovative stunts, which he typically performs himself. Chan has been acting since the 1960s, performing in more than 150 films.
Thought: I should look for his first film
Action: Search
Action Input: "Jackie Chan first film"
Observation: Jackie Chan SBS MBE PMW is a Hong Kong actor, filmmaker, martial artist, and stuntman known for his slapstick acrobatic fighting style, comic timing, and innovative stunts, which he typically performs himself. Chan has been acting since the 1960s, performing in more than 150 films.
Thought: I should look for the character he played in his first film
Action: Search
Action Input: "Jackie Chan first film character"
Observation: Jackie Chan began his film career as an extra child actor in the 1962 film Big and Little Wong Tin Bar. Ten years later, he was a stuntman opposite Bruce Lee in 1972's Fist of Fury and 1973's Enter the Dragon.
Thought: I now know the final answer
Final Answer: Jackie Chan's first film was Big and Little Wong Tin Bar, and he played an extra child actor.
> Finished chain.
[
[
[
"Search",
"Jackie Chan filmography",
" I should research Jackie Chan's filmography\nAction: Search\nAction Input: \"Jackie Chan filmography\""
],
"Jackie Chan SBS MBE PMW is a Hong Kong actor, filmmaker, martial artist, and stuntman known for his slapstick acrobatic fighting style, comic timing, and innovative stunts, which he typically performs himself. Chan has been acting since the 1960s, performing in more than 150 films."
],
[
[
"Search",
"Jackie Chan first film",
" I should look for his first film\nAction: Search\nAction Input: \"Jackie Chan first film\""
],
"Jackie Chan SBS MBE PMW is a Hong Kong actor, filmmaker, martial artist, and stuntman known for his slapstick acrobatic fighting style, comic timing, and innovative stunts, which he typically performs himself. Chan has been acting since the 1960s, performing in more than 150 films."
],
[
[
"Search",
"Jackie Chan first film character",
" I should look for the character he played in his first film\nAction: Search\nAction Input: \"Jackie Chan first film character\""
],
"Jackie Chan began his film career as an extra child actor in the 1962 film Big and Little Wong Tin Bar. Ten years later, he was a stuntman opposite Bruce Lee in 1972's Fist of Fury and 1973's Enter the Dragon."
]
]檢索確認《Big?and?Little?Wong?Tin?Bar》即《大小黃天霸》,為成龍處女作

本文章轉載微信公眾號@野馬逐星







