
GitLabAPI上傳壓縮包的完整指南
Fast RCNN的厲害之處就在于它巧妙地避免了這種重復計算。跟傳統RCNN不一樣的是,Fast RCNN是先對整張圖像做一次卷積運算,提取出共享的特征圖,然后在這個特征圖上用ROI池化層來提取每個候選區域的特征。這樣一來,不僅計算時間大大縮短了,訓練和測試的效率也提高了不少。在Fast RCNN里,每個候選區域經過ROI池化層后都會變成一個固定長度的特征向量,然后再送到全連接層進行分類和邊界框回歸。

Fast RCNN的ROI池化是它的一個核心組件,它將來自不同大小區域的特征映射轉化為固定大小的特征圖,以便進行后續分類和邊界框回歸。
class ROIPool(nn.Module):
def __init__(self, output_size=(7, 7)):
super(ROIPool, self).__init__()
self.output_size = output_size
def forward(self, feature_map, rois):
# rois 是一個形狀為 (N, 4) 的 tensor,表示區域提議的邊界框 (x1, y1, x2, y2)
batch_size = feature_map.size(0)
pooled_features = []
for i in range(batch_size):
# 對每個區域提議進行池化
for roi in rois:
x1, y1, x2, y2 = roi
roi_feature = feature_map[i, :, y1:y2, x1:x2]
pooled = F.adaptive_max_pool2d(roi_feature, self.output_size)
pooled_features.append(pooled)
# 將池化后的特征連接在一起
pooled_features = torch.cat(pooled_features, dim=0)
return pooled_features可以說,Fast RCNN的關鍵創新就是“共享特征提取”,這招兒徹底解決了RCNN中重復計算的問題。而且,Fast RCNN還用了一個更高效的損失函數,把分類損失和回歸損失融合在一起,通過單獨的網絡結構來訓練,這讓整個訓練過程更加高效了。Fast RCNN這種又快又準的目標檢測方法,在實際應用中確實能大顯身手。
我們可以使用預訓練的 ResNet 或 VGG16 網絡來提取卷積特征。在 Fast RCNN 中,我們僅使用卷積層部分,不需要全連接層。
class FastRCNNFeatureExtractor(nn.Module):
def __init__(self):
super(FastRCNNFeatureExtractor, self).__init__()
# 選擇預訓練的 ResNet50 模型
self.resnet = models.resnet50(pretrained=True)
# 去掉 ResNet 的全連接層,只保留卷積層
self.features = nn.Sequential(*list(self.resnet.children())[:-2])
def forward(self, x):
return self.features(x)總體的Fast RCNN實現如下:
class FastRCNN(nn.Module):
def __init__(self, num_classes, output_size=(7, 7)):
super(FastRCNN, self).__init__()
# 特征提取部分
self.feature_extractor = FastRCNNFeatureExtractor()
# ROI池化
self.roi_pool = ROIPool(output_size)
# 分類和邊界框回歸
self.fc_class = nn.Linear(2048 * output_size[0] * output_size[1], num_classes)
self.fc_bbox = nn.Linear(2048 * output_size[0] * output_size[1], 4)
def forward(self, x, rois):
# 提取圖像特征
features = self.feature_extractor(x)
# 通過 ROI池化得到固定尺寸的特征
pooled_features = self.roi_pool(features, rois)
# 將特征展平并通過全連接層
pooled_features = pooled_features.view(pooled_features.size(0), -1)
# 分類任務
class_logits = self.fc_class(pooled_features)
# 邊界框回歸任務
bbox_pred = self.fc_bbox(pooled_features)
return class_logits, bbox_pred在訓練 Fast RCNN 時,我們需要準備一個損失函數來訓練模型。我們可以使用交叉熵損失(用于分類)和回歸損失(用于邊界框回歸)。
# 定義交叉熵損失和邊界框回歸損失
def fast_rcnn_loss(class_logits, bbox_pred, labels, bbox_targets):
# 分類損失:交叉熵損失
class_loss = F.cross_entropy(class_logits, labels)
# 邊界框回歸損失:平滑L1損失
bbox_loss = F.smooth_l1_loss(bbox_pred, bbox_targets)
return class_loss + bbox_loss完整的訓練流程:
def train(model, dataloader, optimizer, num_epochs=10):
model.train()
for epoch in range(num_epochs):
for images, rois, labels, bbox_targets in dataloader:
# 將輸入轉換為 torch.Tensor
images = Variable(images).cuda()
rois = Variable(rois).cuda()
labels = Variable(labels).cuda()
bbox_targets = Variable(bbox_targets).cuda()
# 前向傳播
class_logits, bbox_pred = model(images, rois)
# 計算損失
loss = fast_rcnn_loss(class_logits, bbox_pred, labels, bbox_targets)
# 反向傳播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch [{epoch}/{num_epochs}], Loss: {loss.item()}")
def test(model, dataloader):
model.eval()
with torch.no_grad():
for images, rois, labels, bbox_targets in dataloader:
# 測試時的前向傳播
images = Variable(images).cuda()
rois = Variable(rois).cuda()
class_logits, bbox_pred = model(images, rois)
# 獲取最大概率類作為預測結果
_, predicted_classes = torch.max(class_logits, 1)
# 在這里可以進一步進行評估和計算準確率、IoU等數據加載(偽代碼):
from torch.utils.data import DataLoader, Dataset
class CustomDataset(Dataset):
def __init__(self, image_paths, rois, labels, bbox_targets):
self.image_paths = image_paths
self.rois = rois
self.labels = labels
self.bbox_targets = bbox_targets
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image = cv2.imread(self.image_paths[idx]) # 讀取圖片
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = image.transpose(2, 0, 1) # 調整為 CxHxW 格式
image = torch.tensor(image, dtype=torch.float32)
rois = self.rois[idx] # 區域提議
labels = self.labels[idx] # 目標類別標簽
bbox_targets = self.bbox_targets[idx] # 邊界框回歸目標
return image, rois, labels, bbox_targets測試模型:
# 初始化模型和優化器
model = FastRCNN(num_classes=21) # 假設有21個類(包括背景)
model.cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005)
# 初始化數據加載器
train_dataset = CustomDataset(image_paths, rois, labels, bbox_targets)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
# 訓練模型
train(model, train_loader, optimizer)
# 測試模型
test(model, test_loader)不過嘛,Fast RCNN雖說提高了效率,但候選區域生成這事兒還是個難題。選擇性搜索這個過程耗時比較長,尤其是在處理大規模圖像數據集的時候。為了進一步提升目標檢測的速度和精度,研究者們就繼續想辦法,這時候Faster RCNN就橫空出世了。
Faster RCNN可不是簡單地對之前的版本做了點小修小補,而是徹底改變了整個模型的架構,讓計算速度和準確性都得到了質的飛躍。你可能聽說過RCNN和Fast RCNN,它們都是通過一個個提取圖像區域特征來做目標檢測的,但有個大問題——效率太低了,尤其是在生成候選區域的時候。想當初,RCNN得靠選擇性搜索來生成候選區域,那個過程慢得讓人抓狂。Fast RCNN雖然優化了特征共享,但還是得依賴外部的候選區域生成方法,計算上還是不夠快。雖然這些模型在目標檢測上都表現得不錯,但訓練和測試的速度還是跟不上實際應用的需求。

那么,Faster RCNN是怎么解決這些問題的呢?關鍵就在于它引入了一個叫區域提議網絡(RPN)的東西。RPN就像是一個能直接從卷積特征圖中生成候選區域的深度學習網絡。有了它,Faster RCNN就不需要依賴那些復雜的選擇性搜索算法了,自己就能高效地生成候選區域,而且這個過程是可以端到端訓練的。簡單來說,Faster RCNN不僅在計算速度上快了很多,檢測的準確性也有所提高。
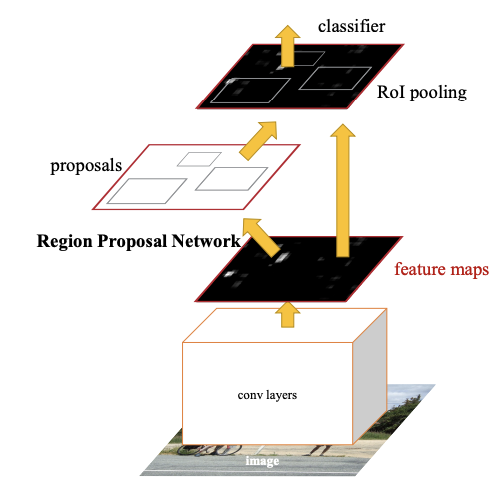
從Fast RCNN到Faster RCNN,這中間的關鍵變化就是RPN的引入。RPN利用卷積神經網絡學習怎么生成高質量的區域提議,并且還能通過回歸的方法調整邊界框,讓候選區域的位置更加準確。這個過程完全融入到了目標檢測的網絡里,實現了端到端的訓練。對開發者來說,這就意味著可以用一個統一的框架來訓練,不用來回傳輸數據和模型,提高了模型的精度和運行效率。
咱們再深入聊聊Faster RCNN的架構和工作原理。
首先,Faster RCNN用的卷積網絡(比如ResNet或VGG)負責從輸入圖像中提取深度特征。這些特征圖不僅用來做目標檢測,還是生成候選區域的基礎。

然后,RPN網絡接過這個活兒,通過對這些特征圖進行卷積操作,生成一組候選區域。你可以把RPN想象成在圖像上滑一個小窗口,這個窗口會為每個位置生成一組框,表示可能存在物體的位置和大小。
為了更準確地生成這些框,RPN還會根據每個框里有沒有目標物體來做出判斷,并通過邊界框回歸來進一步調整框的位置。

這里有個關鍵點,RPN會通過一個簡單的二分類網絡來判斷每個候選區域里有沒有目標物體。這么做的好處是,它把區域提議的生成和目標檢測任務放在了同一個網絡里,這樣就不需要像Fast RCNN那樣依賴選擇性搜索了,同時也讓模型能更好地理解目標物體的上下文,生成更準確的區域提議。
RPN的實現參考:
class RPN(nn.Module):
_feat_stride = [16, ]
anchor_scales = [8, 16, 32]
def __init__(self):
super(RPN, self).__init__()
self.features = VGG16(bn=False)
self.conv1 = Conv2d(512, 512, 3, same_padding=True)
self.score_conv = Conv2d(512, len(self.anchor_scales) * 3 * 2, 1, relu=False, same_padding=False)
self.bbox_conv = Conv2d(512, len(self.anchor_scales) * 3 * 4, 1, relu=False, same_padding=False)
# loss
self.cross_entropy = None
self.los_box = None
@property
def loss(self):
return self.cross_entropy + self.loss_box * 10
def forward(self, im_data, im_info, gt_boxes=None, gt_ishard=None, dontcare_areas=None):
im_data = network.np_to_variable(im_data, is_cuda=True)
im_data = im_data.permute(0, 3, 1, 2)
features = self.features(im_data)
rpn_conv1 = self.conv1(features)
# rpn score
rpn_cls_score = self.score_conv(rpn_conv1)
rpn_cls_score_reshape = self.reshape_layer(rpn_cls_score, 2)
rpn_cls_prob = F.softmax(rpn_cls_score_reshape)
rpn_cls_prob_reshape = self.reshape_layer(rpn_cls_prob, len(self.anchor_scales)*3*2)
# rpn boxes
rpn_bbox_pred = self.bbox_conv(rpn_conv1)
# proposal layer
cfg_key = 'TRAIN' if self.training else 'TEST'
rois = self.proposal_layer(rpn_cls_prob_reshape, rpn_bbox_pred, im_info,
cfg_key, self._feat_stride, self.anchor_scales)
# generating training labels and build the rpn loss
if self.training:
assert gt_boxes is not None
rpn_data = self.anchor_target_layer(rpn_cls_score, gt_boxes, gt_ishard, dontcare_areas,
im_info, self._feat_stride, self.anchor_scales)
self.cross_entropy, self.loss_box = self.build_loss(rpn_cls_score_reshape, rpn_bbox_pred, rpn_data)
return features, rois
def build_loss(self, rpn_cls_score_reshape, rpn_bbox_pred, rpn_data):
# classification loss
rpn_cls_score = rpn_cls_score_reshape.permute(0, 2, 3, 1).contiguous().view(-1, 2)
rpn_label = rpn_data[0].view(-1)
rpn_keep = Variable(rpn_label.data.ne(-1).nonzero().squeeze()).cuda()
rpn_cls_score = torch.index_select(rpn_cls_score, 0, rpn_keep)
rpn_label = torch.index_select(rpn_label, 0, rpn_keep)
fg_cnt = torch.sum(rpn_label.data.ne(0))
rpn_cross_entropy = F.cross_entropy(rpn_cls_score, rpn_label)
# box loss
rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights = rpn_data[1:]
rpn_bbox_targets = torch.mul(rpn_bbox_targets, rpn_bbox_inside_weights)
rpn_bbox_pred = torch.mul(rpn_bbox_pred, rpn_bbox_inside_weights)
rpn_loss_box = F.smooth_l1_loss(rpn_bbox_pred, rpn_bbox_targets, size_average=False) / (fg_cnt + 1e-4)
return rpn_cross_entropy, rpn_loss_box
@staticmethod
def reshape_layer(x, d):
input_shape = x.size()
# x = x.permute(0, 3, 1, 2)
# b c w h
x = x.view(
input_shape[0],
int(d),
int(float(input_shape[1] * input_shape[2]) / float(d)),
input_shape[3]
)
# x = x.permute(0, 2, 3, 1)
return x
@staticmethod
def proposal_layer(rpn_cls_prob_reshape, rpn_bbox_pred, im_info, cfg_key, _feat_stride, anchor_scales):
rpn_cls_prob_reshape = rpn_cls_prob_reshape.data.cpu().numpy()
rpn_bbox_pred = rpn_bbox_pred.data.cpu().numpy()
x = proposal_layer_py(rpn_cls_prob_reshape, rpn_bbox_pred, im_info, cfg_key, _feat_stride, anchor_scales)
x = network.np_to_variable(x, is_cuda=True)
return x.view(-1, 5)
@staticmethod
def anchor_target_layer(rpn_cls_score, gt_boxes, gt_ishard, dontcare_areas, im_info, _feat_stride, anchor_scales):
"""
rpn_cls_score: for pytorch (1, Ax2, H, W) bg/fg scores of previous conv layer
gt_boxes: (G, 5) vstack of [x1, y1, x2, y2, class]
gt_ishard: (G, 1), 1 or 0 indicates difficult or not
dontcare_areas: (D, 4), some areas may contains small objs but no labelling. D may be 0
im_info: a list of [image_height, image_width, scale_ratios]
_feat_stride: the downsampling ratio of feature map to the original input image
anchor_scales: the scales to the basic_anchor (basic anchor is [16, 16])
----------
Returns
----------
rpn_labels : (1, 1, HxA, W), for each anchor, 0 denotes bg, 1 fg, -1 dontcare
rpn_bbox_targets: (1, 4xA, H, W), distances of the anchors to the gt_boxes(may contains some transform)
that are the regression objectives
rpn_bbox_inside_weights: (1, 4xA, H, W) weights of each boxes, mainly accepts hyper param in cfg
rpn_bbox_outside_weights: (1, 4xA, H, W) used to balance the fg/bg,
beacuse the numbers of bgs and fgs mays significiantly different
"""
rpn_cls_score = rpn_cls_score.data.cpu().numpy()
rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights = \
anchor_target_layer_py(rpn_cls_score, gt_boxes, gt_ishard, dontcare_areas, im_info, _feat_stride, anchor_scales)
rpn_labels = network.np_to_variable(rpn_labels, is_cuda=True, dtype=torch.LongTensor)
rpn_bbox_targets = network.np_to_variable(rpn_bbox_targets, is_cuda=True)
rpn_bbox_inside_weights = network.np_to_variable(rpn_bbox_inside_weights, is_cuda=True)
rpn_bbox_outside_weights = network.np_to_variable(rpn_bbox_outside_weights, is_cuda=True)
return rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights
def load_from_npz(self, params):
# params = np.load(npz_file)
self.features.load_from_npz(params)
pairs = {'conv1.conv': 'rpn_conv/3x3', 'score_conv.conv': 'rpn_cls_score', 'bbox_conv.conv': 'rpn_bbox_pred'}
own_dict = self.state_dict()
for k, v in pairs.items():
key = '{}.weight'.format(k)
param = torch.from_numpy(params['{}/weights:0'.format(v)]).permute(3, 2, 0, 1)
own_dict[key].copy_(param)
key = '{}.bias'.format(k)
param = torch.from_numpy(params['{}/biases:0'.format(v)])
own_dict[key].copy_(param)當RPN生成了候選區域后,這些區域就會進入Fast RCNN進行最后的分類和邊界框回歸。這個過程和Fast RCNN里很像,只不過現在用的候選區域是RPN自己生成的,所以整個流程更高效,訓練和測試的時間也大大縮短了。
你可能會問,為什么RPN這么重要,能提高檢測精度呢?這跟它生成區域提議的方式有關。傳統的方法(如選擇性搜索)通過圖像分割和聚類來生成區域,雖然有效,但沒有利用到深度網絡的強大特征提取能力。而RPN是通過卷積神經網絡直接在特征圖上滑動窗口來生成區域的,它不僅能在不同尺度上做出準確的判斷,還能通過回歸來不斷優化候選區域的位置。這樣一來,RPN生成的候選區域質量更高,還能捕捉到更多細節。
那Faster RCNN的具體架構是怎樣的呢?簡單來說,它包括以下幾個部分:
Faster RCNN的訓練是通過聯合損失函數來實現的,包括分類損失和邊界框回歸損失。分類損失用的是交叉熵損失函數,回歸損失用的是平滑L1損失。這兩個損失函數的結合確保了模型既能準確預測物體類別,又能精確定位物體位置。
下面給一個Faster RCNN的調用例子:
import torch
import torchvision
import torchvision.transforms as T
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.datasets import VOCDetection
# 定義數據預處理函數
def get_transform():
# 預處理包括將圖像轉換為 tensor 和進行標準化
return T.Compose([
T.ToTensor(),
])
# 下載 PASCAL VOC 數據集并定義訓練集
train_dataset = VOCDetection(root='./data', year='2012', image_set='train', download=True, transform=get_transform())
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=4)
# 加載預訓練的 Faster RCNN 模型
model = fasterrcnn_resnet50_fpn(pretrained=True)
# 需要修改模型以適應 VOC 數據集(類別數為 21)
num_classes = 21 # VOC 數據集類別數(包括背景)
in_features = model.roi_heads.box_predictor.cls_score.in_features
# 替換最后一層分類頭,以適應 VOC 數據集
model.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
# 使用 SGD 優化器
optimizer = optim.SGD(model.parameters(), lr=0.005, momentum=0.9, weight_decay=0.0005)
# 定義訓練函數
def train(model, dataloader, optimizer, num_epochs=10):
model.train()
for epoch in range(num_epochs):
for images, targets in dataloader:
# 將輸入數據移動到 GPU
images = [image.cuda() for image in images]
targets = [{k: v.cuda() for k, v in t.items()} for t in targets]
# 清空梯度
optimizer.zero_grad()
# 前向傳播
loss_dict = model(images, targets)
# 計算總損失
losses = sum(loss for loss in loss_dict.values())
# 反向傳播
losses.backward()
# 更新模型參數
optimizer.step()
# 輸出當前的損失
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {losses.item()}")
# 訓練模型
model.cuda()
train(model, train_loader, optimizer, num_epochs=5)
# 定義測試函數
def test(model, dataloader):
model.eval()
with torch.no_grad():
for images, targets in dataloader:
images = [image.cuda() for image in images]
# 獲得模型的預測結果
prediction = model(images)
# 可視化檢測結果
for i in range(len(images)):
image = images[i].cpu().numpy().transpose(1, 2, 0)
plt.imshow(image)
boxes = prediction[i]['boxes'].cpu().numpy()
labels = prediction[i]['labels'].cpu().numpy()
scores = prediction[i]['scores'].cpu().numpy()
# 篩選出得分較高的預測框
high_score_idx = scores > 0.5
boxes = boxes[high_score_idx]
labels = labels[high_score_idx]
for box in boxes:
plt.gca().add_patch(plt.Rectangle((box[0], box[1]), box[2] - box[0], box[3] - box[1],
fill=False, color='red', linewidth=2))
plt.show()
# 使用測試集進行評估
test(model, train_loader)在實際應用中,Faster RCNN的速度和精度都很不錯。它在COCO和PASCAL VOC等數據集上表現優異,特別是在高精度目標檢測任務中,經常成為基準模型。比如在COCO數據集上,Faster RCNN的mAP能達到36.2%以上,在PASCAL VOC上的表現也很棒。
總的來說,Faster RCNN解決了目標檢測中的很多關鍵問題,讓速度和精度都有了很大的提升。它不再依賴傳統的候選區域生成方法,而是通過RPN實現了端到端的訓練,效率大大提高。雖然Faster RCNN已經很成熟了,但在實時檢測和大規模數據集上還有提升的空間。隨著技術的發展,相信目標檢測模型會越來越好。每一次算法的進步,都是對計算能力、數據處理、網絡架構等多方面的深入理解和優化的結果。相信在未來,目標檢測會變得更加智能、更加高效!
本文章轉載微信公眾號@Chal1ceAI







