
如何快速實(shí)現(xiàn)REST API集成以優(yōu)化業(yè)務(wù)流程
就可以對(duì)著麥克風(fēng)說(shuō)話聽(tīng)到自己的聲音了。對(duì)上述來(lái)源數(shù)據(jù)流的處理被設(shè)計(jì)成一個(gè)個(gè)的節(jié)點(diǎn)(Node),具有模塊化路由的特點(diǎn),需要添加什么樣的效果添加什么樣的node,例如一個(gè)最常見(jiàn)的操作是通過(guò)把輸入的采樣數(shù)據(jù)放大來(lái)達(dá)到擴(kuò)音器的作用(GainNode),示例代碼:
// 創(chuàng)建音頻上下文
const audioContext = new AudioContext();
// 創(chuàng)建一個(gè)增益Node
const gainNode = audioCtx.createGain();
// 獲取設(shè)備麥克風(fēng)流
stream = await navigator.mediaDevices
.getUserMedia({ audio: true})
.catch(function (error) {
console.log(error);
});
// 創(chuàng)建來(lái)自麥克風(fēng)的流的聲音源
const sourceNode = audioContext.createMediaStreamSource(stream);
// 將聲音經(jīng)過(guò)gainNode處理
sourceNode.connect(gainNode);
// 將聲音連接的揚(yáng)聲器
gainNode.connect(audioContext.destination);
// 設(shè)置聲音增益,放大聲音
gainNode.gain.value = 2.0;以上只是連接了聲音放大的node,如果想要增加其它效果,可以繼續(xù)往上添加node連接connect,例如濾波器(BiquadFilterNode)、立體聲控制(StereoPannerNode)、對(duì)信號(hào)進(jìn)行扭曲(WaveShaperNode)等等。這種模塊化設(shè)計(jì)提供了靈活的創(chuàng)建動(dòng)態(tài)效果和復(fù)合音頻的方法,是不是有種變魔法的感覺(jué),哪里修改點(diǎn)哪里(添加Node)非常方便。例如,以下展示了一個(gè)利用?AudioContext?創(chuàng)建四項(xiàng)濾波器節(jié)點(diǎn)(Biquad filter node)的例子:
var audioCtx = new (window.AudioContext || window.webkitAudioContext)();
// 創(chuàng)建多個(gè)不同作用功能的node節(jié)點(diǎn)
var analyser = audioCtx.createAnalyser();
var distortion = audioCtx.createWaveShaper();
var gainNode = audioCtx.createGain();
var biquadFilter = audioCtx.createBiquadFilter();
var convolver = audioCtx.createConvolver();
// 將所有節(jié)點(diǎn)連接在一起
source = audioCtx.createMediaStreamSource(stream);
source.connect(analyser);
analyser.connect(distortion);
distortion.connect(biquadFilter);
biquadFilter.connect(convolver);
convolver.connect(gainNode);
gainNode.connect(audioCtx.destination);
// 控制雙二階濾波器
biquadFilter.type = "lowshelf";
biquadFilter.frequency.value = 1000;
biquadFilter.gain.value = 25;可以看到為聲音流添加處理效果就像穿項(xiàng)鏈一樣,一個(gè)接一個(gè),最后得到最終效果,實(shí)現(xiàn)效果可以參考官方樣例voice-change-o-matic。一個(gè)簡(jiǎn)單而典型的 web audio 流程如下:

首先回顧一下聲音的基礎(chǔ)知識(shí),聲音是由物體振動(dòng)產(chǎn)生的機(jī)械波,常接觸到的有以下三個(gè)特性:
這里說(shuō)的變聲效果是改變聲音的音調(diào),變聲效果根據(jù)不同的場(chǎng)景可以分為變速不變調(diào)、變調(diào)不變速以及變調(diào)又變速 3 種。變速是指把一個(gè)語(yǔ)音在時(shí)域上拉長(zhǎng)或縮短,而聲音的采樣率、基頻以及共振峰都沒(méi)有發(fā)生變化。變調(diào)是指把語(yǔ)音的基因頻率降低或升高,共振峰做出相應(yīng)的改變,采樣頻率不變。各種方案應(yīng)用場(chǎng)景如下:
前兩種實(shí)現(xiàn)都要求對(duì)聲音知識(shí)領(lǐng)域有更深的了解,聲音時(shí)域、頻域,信號(hào)的傅里葉變換變化都要去重新去復(fù)習(xí)一下,學(xué)習(xí)成本比較高,這里使用第3種方式,比較好接入。要改變聲音的播放速率,Web Audio API中提供了AudioBufferSourceNode有playbackRate屬性,可以設(shè)置音頻的播放速率,使用音頻上下文AudioContext.createBufferSource獲得實(shí)例,示例代碼如下:
const play = ()=> {
const audioSrc = ref("src/assets/sample_orig.mp3")
const url = audioSrc.value
const request = new XMLHttpRequest()
request.open('GET', url, true)
request.responseType = 'arraybuffer'
request.onload = function() {
const audioData = request.response
const audioCtx = new (window.AudioContext || window.webkitAudioContext)();
audioCtx.decodeAudioData(audioData, (audioBuffer) => {
let source = audioCtx.createBufferSource();
source.buffer = audioBuffer;
// 改變聲音播放速率,2倍播放
source.playbackRate.value = 2;
source.connect(audioCtx.destination);
source.start(0);
});
}
request.send()
}可以調(diào)整source.playbackRate.value的值來(lái)改變音調(diào),大于1提高音調(diào),小于1降低音調(diào)。
雖然實(shí)現(xiàn)了變聲效果,但是這種方式只適合播放音頻文件,或者能獲取到完整音頻流的情況,對(duì)于獲取麥克風(fēng)這種持續(xù)輸入的聲音流并不適用,類似的還有SoundTouchJS,它是某大佬實(shí)現(xiàn)的SoundTouch的JS版本,使用也是要獲取完整音頻的數(shù)據(jù)流,作者也做了相應(yīng)的解釋,參考鏈接

如何處理麥克風(fēng)獲取的實(shí)時(shí)音頻流呢,這里可以借助Web Audio API中的ScriptProcessorNode,它允許使用 JavaScript 生成、處理、分析音頻。處理流程圖如下:
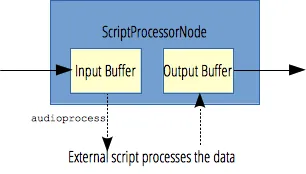
利用它將實(shí)時(shí)音頻流數(shù)據(jù)處理一下,得到慢放或加速的聲音流數(shù)據(jù)。示例代碼如下:
const audioprocess = async () => {
const audioContext = new AudioContext();
// 采集麥克風(fēng)輸入聲音流
let stream = await navigator.mediaDevices
.getUserMedia({ audio: true})
.catch(function (error) {
console.log(error);
});
const sourceNode = audioContext.createMediaStreamSource(stream);
const processor = audioContext.createScriptProcessor(4096, 1, 1);
processor.onaudioprocess = async event => {
// 處理回調(diào)中拿到輸入聲音數(shù)據(jù)
const inputBuffer = event.inputBuffer;
// 創(chuàng)建新的輸出源
const outputSource = audioContext.createMediaStreamDestination();
const audioBuffer = audioContext.createBufferSource();
audioBuffer.buffer = inputBuffer;
// 設(shè)置聲音加粗,慢放0.7倍
audioBuffer.playbackRate.value = 0.7
audioBuffer.connect(outputSource);
audioBuffer.start();
// 返回新的 MediaStream
const newStream = outputSource.stream;
const node = audioContext.createMediaStreamSource(newStream)
// 連接到揚(yáng)聲器播放
node.connect(audioContext.destination)
};
// 添加處理節(jié)點(diǎn)
sourceNode.connect(processor);
processor.connect(audioContext.destination)
}另外,還有一個(gè)利用Google開(kāi)源jungle實(shí)現(xiàn)的改變音調(diào)的庫(kù),并且還有各種混響效果,音頻可視化等炫酷功能,也是使用的Web Audio API實(shí)現(xiàn),github鏈接地址放在這里了,有興趣也可以體驗(yàn)下,畫面長(zhǎng)這樣
以上就是對(duì)Web Audio API的簡(jiǎn)單介紹和使用的分析,以及采用Web Audio API實(shí)現(xiàn)聲音簡(jiǎn)單變聲效果的幾種實(shí)現(xiàn),大家有哪些更好的實(shí)現(xiàn)方案歡迎評(píng)論區(qū)一起交流!
https://developer.mozilla.org/en-US/docs/Web/API/Web_Audio_API
https://github.com/cwilso/Audio-Input-Effects
https://mdn.github.io/voice-change-o-matic/
https://github.com/cutterbl/SoundTouchJS
https://cloud.tencent.com/developer/news/818606
https://zhuanlan.zhihu.com/p/110278983
https://www.nxrte.com/jishu/3146.html
文章轉(zhuǎn)自微信公眾號(hào)@奇舞精選
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)


安全的關(guān)鍵.png)



