
使用NestJS和Prisma構建REST API:身份驗證
預檢索優化主要包括提高數據索引或知識數據庫中信息的質量和可檢索性。這里所需的技術和工作量在很大程度上取決于數據的性質、來源和規模。例如,優化信息密度可以提高用戶體驗,通過生成更準確的響應并減少token數來降低成本。但是,我們如何在系統之間進行優化變化呢?針對旅行行業聊天機器人增強檢索的優化可能會在金融人工智能助手中產生驚人的逆效果,因為每個系統依賴于不同性質和獨特監管框架的信息。在預檢索階段,LLMs為我們提供了許多優化信息的方式,使我們能夠根據目標測試和微調不同的方法。以下是五種值得在預檢索階段探索的基于LLM的高級RAG技術。
您可以通過使用LLMs在存儲之前處理、清潔和標記數據,顯著提高RAG系統的性能。這種改進是因為來自異構數據源(例如PDF、抓取的網絡數據、音頻轉錄)的非結構化數據未必為RAG系統而構建,會導致以下問題:
低信息密度會迫使RAG系統向LLM上下文窗口中插入更多塊以正確回答用戶查詢,增加token使用和成本。此外,低信息密度會使相關信息稀釋到LLM可能錯誤回復的程度。當使用低于70,000個token時,GPT-4似乎相對抵抗這個問題,但其他模型可能沒有那么強大。以下是我們最近遇到的一個場景,當在RAG系統上工作時可能很容易發生:我們作為主要數據源抓取了數百個網頁,但原始HTML包含大量不相關信息(例如CSS類、頁眉/頁腳導航、HTML標記、頁面之間的冗余信息)。即使在程序化剝離CSS和HTML后,信息密度仍然很低。因此,為了提高我們塊中的信息密度,我們嘗試使用GPT-4作為從文檔中提取相關信息的事實提取器。在剝離CSS和HTML標記后,我們使用了類似下面的LLM調用來處理每個抓取的網頁,然后將它們分塊并插入到我們的知識庫中。
fact_extracted_output = openai.ChatCompletion.create(
model=”gpt-4”,
messages=[
{
“role”: “system”,
“content”: “You are a data processing assistant. Your task is to
extract meaningful information from a scraped web page from XYZ
Corp. This information will serve as a knowledge base for further
customer inquiries. Be sure to include all possible relevant
information that could be queried by XYZ Corp’s customers. The output
should be text-only (no lists) separated by paragraphs.”,
},
{“role”: “user”, “content”: <scraped web page>},
],
temperature=0)以下是經過我們管道處理的匿名抓取??內容?例。從左列開始,我們發現原始 HTML 代碼段 的有?信息密度較低。

在程序化剝離CSS、JS和HTML后,中央片段的情況有所改善,但仍不包含高質量信息。現在,看看右側片段,其中包含經過GPT-4處理的事實提取內容,注意信息密度的飛躍。這是我們在分塊和嵌入過程中使用的方法。值得注意的是,單個網頁文本在不同階段的token計數如下:
盡管token數量最顯著的減少(20倍)是通過對CSS、JS和HTML進行編程剝離實現的,但應用于剝離后的HTML的GPT-4事實提取步驟始終將標記數量進一步減少了500%。我們嘗試了一個流程,其中保留HTML標記,以防HTML結構中存在某種語義含義,但在我們的案例中,我們的RAG評估指標顯示,去除標記后性能有所提升。警告:信息丟失的?險使用大型語言模型(LLMs)增加信息密度的風險在于可能丟失關鍵信息。減輕這一風險的一種策略是確保事實提取LLM輸出的最大大小要么a)沒有限制,要么b)小于輸入內容的大小,以防輸入內容已經非常豐富且100%有用。
通過利用LLM生成的摘要,可以通過多層檢索系統使搜索變得更有效。分層索引檢索的實踐利用文檔摘要來簡化識別用于響應生成的相關信息。
前一節著重于提高信息密度而不丟失相關信息,類似于無損壓縮。然而,在生成文檔摘要時,LLMs執行的更類似于有損壓縮。
這些摘要文檔支持對大型數據庫的高效搜索。與僅創建由文檔塊組成的單個數據索引不同,由文檔摘要組成的額外數據索引創建了一個第一層過濾機制,該機制排除了具有與搜索查詢無關的摘要的文檔塊。
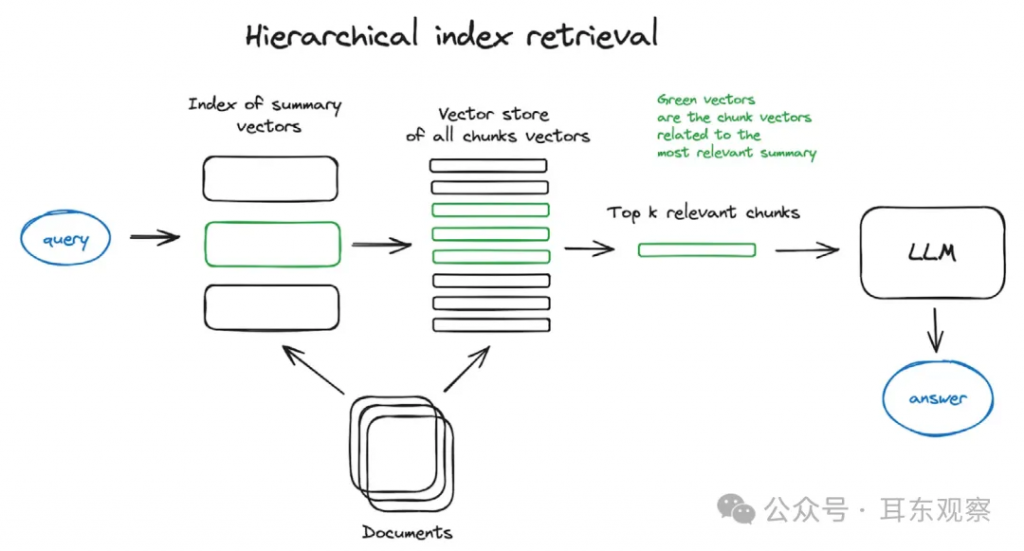
LLMs還可以將文檔轉換為對于嵌入模型和RAG系統中使用的查詢都最優的格式。一種方法是使用GPT-4為每個文檔生成一組假設/可能的問題和答案對,然后使用生成的問題作為要嵌入以進行檢索的塊。在檢索時,系統將檢索問題及其相應的答案,并將它們提供給LLM。因此,查詢的嵌入很可能與生成的問題的嵌入具有更高的余弦相似度。這種相似性降低了在分塊過程中丟失相關上下文的風險。每個問答對因此是獨立的,并在理論上將包含所有所需的上下文。查詢和用于檢索的文檔之間的不對稱在RAG系統中是一個常見問題。查詢通常是簡短的問題,比如:“XYZ金融機構提供的最佳旅行信用卡是什么?”然而,針對該查詢的相關文檔塊要長得多(例如,包含所有由XYZ金融機構提供的信用卡的詳細內容的段落)。這個金融服務示例為語義搜索提出了問題:如果查詢與文檔塊明顯不同(即,不對稱性過大),語義相似性可能很低,這可能導致搜索結果不佳,并使系統偏向錯誤的信息。下?的圖表說明了我們如何使?假設問題索引:

這是我們使?的提?:
generated_question_answer_pairs = openai.ChatCompletion.create(
model=”gpt-4”,
messages=[
{
“role”: “system”,
“content”: “Analyze the provided text or html from Example bank’s
Here’s a diagram illustrating how we used a hypothetical question index:
website and create questions an Example bank customer could ask a
chatbot about the information in the text. You should not create
a question if it does not have a useful/informative answer to it
that would be helpful for a customer. For every question, please
formulate answers based strictly on the information in the text.
Use Q: for questions and A: for answers. Do not write any other
commentary. Questions should not reference html sections or links.
Create as many useful Q&A pairings as possible.”,
},
{“role”: “user”, “content”: <scraped web page>},
],
temperature=0)利用LLMs生成問答對對于RAG系統的基準測試和評估也可能是有益的。這些問答對可以作為問題和期望答案的黃金標準數據集,整個RAG系統應該能夠回答這些問題。
至于減少塊大小,該方法只能走得這么遠,因為塊必須保持最小尺寸以保留足夠的上下文信息以便有用。即使使用更大的塊大小,始終存在在分塊過程中丟失關鍵上下文信息的風險。可以通過基于諸如大小和重疊比率之類的分塊考慮進行實驗來減輕(但無法消除)這種風險。注意事項:假設性問題索引的風險和替代方案信息丟失仍然是這種先進的RAG技術的風險。對于高度信息密集的文檔,LLMs可能無法生成足夠的問答對來覆蓋用戶可能對文檔中信息的各種查詢。此外,根據您的文檔存儲大小,使用LLM處理和轉換每個文檔以減輕查詢-文檔不對稱可能成本過高。最后,根據您的RAG系統的流量,一個更有效的解決方案可能是一種名為假設性文檔嵌入(HyDE)的反向方法,用于轉換用戶查詢而不是文檔。我們將在下面的檢索技術部分進一步討論HyDE。
使用LLMs作為信息去重器可以提高數據索引的質量。LLM通過將塊精簡為較少的塊來去重信息,提高了獲得理想響應的幾率。這是一項有價值的技術,因為根據情況不同,數據索引中的信息重復可能有助于或阻礙RAG系統的輸出。一方面,如果用于回答查詢所需的正確信息在LLM生成響應的上下文窗口中重復,那么LLM產生理想響應的可能性增加。相反,如果重復的程度削弱甚至完全排除了LLM上下文窗口中的所需信息,那么用戶可能會收到非答案,甚至更糟糕,是來自RAG系統的AI幻覺。我們可以通過在嵌入空間中對塊進行k均值聚類,使每個塊簇中的聚合token數適合LLM的有效上下文窗口。從這里,我們可以讓LLM從原始簇中簡單地輸出一組經過精簡的新塊,以去除重復信息。如果一個給定的簇包含N個塊,我們應該期望這個去重提示輸出小于或等于N個新塊,其中新塊中刪除了任何多余信息。以下圖顯示了信息去重之前和之后在嵌入空間中的塊。
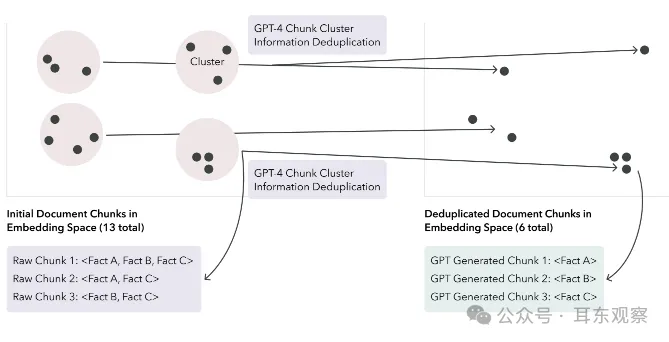
注意:這個過程使得在您的RAG系統中包含任何引用系統變得更加困難,因為新的塊可能包含來自多個文檔的信息。此外,信息丟失的風險仍然存在,以及降低信息重復在檢索系統中可能受益的風險。
上述技術強調了分塊策略的重要性。但是,最佳的分塊策略是特定于用例的,許多因素影響著它。找到最佳的分塊策略的唯一方法是廣泛地對您的RAG系統進行A/B測試。在測試時需要考慮以下一些最重要的因素。
1、嵌入模型:
不同的嵌入模型在不同的輸入大小下具有不同的性能特征。例如,來自句子轉換器的嵌入模型在嵌入單個句子時表現出色,而text-embedding-ada-002可以處理更大的輸入。塊的大小應該理想地根據所使用的具體嵌入模型進行定制,反之亦然。
2、要嵌入的內容的性質:根據文檔的信息密度、格式和復雜性,塊可能需要具有一定的最小尺寸才能包含足夠的上下文信息以便LLM使用。然而,這是一個平衡的過程。如果塊太大,它們可能會在嵌入中稀釋相關信息,降低在語義搜索期間該塊的檢索概率。如果您的文檔沒有自然的斷點(例如,用子標題分割的教科書章節),并且文檔是基于任意字符限制(例如,500個字符)進行分塊的,那么存在關鍵上下文信息被分割的風險。在這種情況下,應該考慮重疊。例如,具有50%重疊比率的分塊策略意味著文檔中兩個相鄰的500字符塊將相互重疊250個字符。在決定重疊比率時,應考慮信息重復和嵌入更多數據的成本。
3、查詢的復雜性或嵌入類型如果您的RAG系統處理以大段落提出的查詢,那么將數據分塊成大段落是有意義的。然而,如果查詢只有幾個詞長,大塊大小可能不利于最佳信息檢索。4、LLM的能力、上下文窗口和成本雖然GPT-4似乎能夠處理許多大塊,但更小的生成模型可能表現不佳。此外,在許多大塊上運行推斷可能成本高昂。5、要嵌入的數據量嵌入必須存儲在某個地方,而較小的塊大小會導致相同數據量的更多嵌入,這意味著增加的存儲需求和成本。更多的嵌入還可能增加用于語義搜索的計算資源,這取決于您的語義搜索是如何實現的(精確最近鄰 vs. 近似最近鄰)。我們的經驗通過借助我們基于LLM的RAG評估系統進行廣泛的A/B測試,我們可以為我們的每個用例評估最佳的分塊策略。
我們主要在由GPT-4處理的改進信息密集文檔上測試了以下分塊策略:
在構建我們的金融服務AI助手時,我們發現分塊策略的選擇并沒有太大影響(請參見下表中的結果)。具有重疊200個字符的1,000字符塊策略表現略優于其他策略。

我們對分塊策略為何顯著影響我們的用例提出的假設包括:
然而,只要我們對應用程序進行了一次改變,比如為更復雜的領域構建,我們很可能會看到不同的結果。
我們渴望測試更先進的RAG技術,用于預檢索和數據索引。這些技術包括遞歸檢索,通過迭代一個檢索步驟的輸出并將其用作另一個步驟的輸入來支持復雜的多步查詢。通過句子窗口和父子塊檢索進行上下文豐富化也讓我們感興趣,這是一種改進搜索和豐富LLM響應的方式。
以上分享的5種高級RAG技巧,主要是面向預檢索和數據索引方向,后面會陸續針對RAG檢索中、檢索后、生成中等方向分享另外的10種RAG技巧。
文章轉自微信公眾號@耳東觀察






