
如何快速實(shí)現(xiàn)REST API集成以優(yōu)化業(yè)務(wù)流程
? ? ? ?前面的章節(jié)展示了如何將額外信息輸入給UNet,以實(shí)現(xiàn)對(duì)生成圖像的控制,這種方法稱為條件生成。以文本為條件進(jìn)行控制圖像的生成是在推理階段,我們可以輸入期望圖像的文本描述(Prompt),并把純?cè)肼晹?shù)據(jù)作為起點(diǎn),然后模型對(duì)噪聲數(shù)據(jù)進(jìn)行“去噪”,從而生成能夠匹配文本描述的圖像。那么這個(gè)過(guò)程是如何實(shí)現(xiàn)的呢?
? ? ? 我們需要對(duì)文本進(jìn)行編碼表示,然后輸入給UNet作為生成條件,文本嵌入表示如下圖ENCODER_HIDDEN_STATES
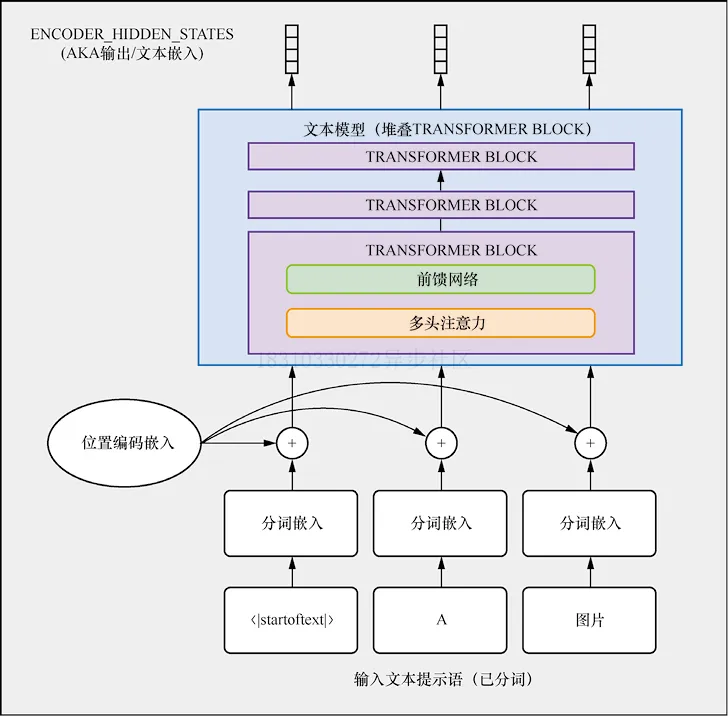
Stable Diffusion使用CLIP對(duì)文本描述進(jìn)行編碼,首先對(duì)輸入文本描述進(jìn)行分詞,然后輸入給CLIP文本編碼器,從而為每個(gè)token產(chǎn)生一個(gè)768維(Stable Diffusion 1.x版本)或者1024維(Stable Diffusion 2.x版本)向量,為了使輸入格式一致,文本描述總是被補(bǔ)全或者截?cái)酁?7個(gè)token。
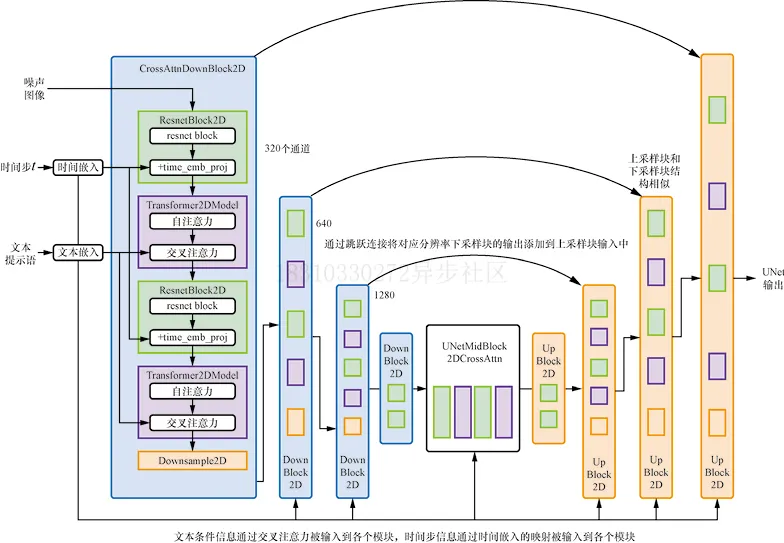
? ? ? ?那么,如何將這些條件信息輸入給UNet進(jìn)行預(yù)測(cè)呢?答案是使用交叉注意力(cross-attention)機(jī)制。UNet網(wǎng)絡(luò)中的每個(gè)空間位置都可以與文本條件中的不同token建立注意力(在稍后的代碼中可以看到具體的實(shí)現(xiàn)),如下圖所示:
第2節(jié)我們提到可以使用CLIP編碼文本描述來(lái)控制圖像的生成,但是實(shí)際使用中,每個(gè)生成的圖像都是按照文本描述生成的嗎?當(dāng)然不一定,其實(shí)是大模型的幻覺(jué)問(wèn)題,原因可能是訓(xùn)練數(shù)據(jù)中圖像與文本描述相關(guān)性弱,模型可能學(xué)著不過(guò)度依賴文本描述,而是從大量圖像中學(xué)習(xí)來(lái)生成圖像,最終達(dá)不到我們的期望,那如何解決呢?
? ? ? ?我們可以引入一個(gè)小技巧-無(wú)分類器引導(dǎo)(Classifier-Free Guidance,CFG)。在訓(xùn)練時(shí),我們時(shí)不時(shí)把文本條件置空,強(qiáng)制模型去學(xué)習(xí)如何在無(wú)文字信息的情況下對(duì)圖像“去噪”。在推理階段,我們分別進(jìn)行了兩個(gè)預(yù)測(cè):一個(gè)有文字條件,另一個(gè)則沒(méi)有文字條件。這樣我們就可以利用兩者的差異來(lái)建立一個(gè)最終的預(yù)測(cè)了,并使最終結(jié)果在文本條件預(yù)測(cè)所指明的方向上依據(jù)一個(gè)縮放系數(shù)(引導(dǎo)尺度)更好的生成文本描述匹配的結(jié)果。從下圖看到,更大的引導(dǎo)尺度能讓生成的圖像更接近文本描述。

其實(shí)除了使用文本描述作為條件生成圖像,還有其他不同類型的條件可以控制Stable Diffusion生成圖像,比如圖片到圖片、圖片的部分掩碼(mask)到圖片以及深度圖到圖片,這些模型分別使用圖片本身、圖片掩碼和圖片深度信息作為條件來(lái)生成最終的圖片。
? ? ? ?Img2Img是圖片到圖片的轉(zhuǎn)換,包括多種類型,如風(fēng)格轉(zhuǎn)換(從照片風(fēng)格轉(zhuǎn)換為動(dòng)漫風(fēng)格)和圖片超分辨率(給定一張低分辨率圖片作為條件,讓模型生成對(duì)應(yīng)的高分辨率圖片,類似Stable Diffusion Upscaler)。Inpainting又稱圖片修復(fù),模型會(huì)根據(jù)掩碼的區(qū)域信息和掩碼之外的全局結(jié)構(gòu)信息生成連貫的圖片。Depth2Img采用圖片的深度新作為條件,模型生成與深度圖本身相似的具有全局結(jié)構(gòu)的圖片,如下圖所示:

? ? ? DreamBooth可以微調(diào)文本到圖像的生成模型,最初是為Google的Imagen Model開發(fā)的,很快被應(yīng)用到Stable Diffusion中。它可以根據(jù)用戶提供的一個(gè)主題3~5張圖片,就可以生成與該主題相關(guān)的圖像,但它對(duì)于各種設(shè)置比較敏感。
安裝python庫(kù)
pip install -Uq diffusers ftfy accelerate
pip install -Uq git+https://github.com/huggingface/transformers數(shù)據(jù)準(zhǔn)備
import torch
import requests
from PIL import Image
from io import BytesIO
from matplotlib import pyplot as plt
# 這次要探索的管線比較多
from diffusers import (
StableDiffusionPipeline,
StableDiffusionImg2ImgPipeline,
StableDiffusionInpaintPipeline,
StableDiffusionDepth2ImgPipeline
)
# 因?yàn)橐玫降恼故緢D片較多,所以我們寫了一個(gè)旨在下載圖片的函數(shù)
def download_image(url):
response = requests.get(url)
return Image.open(BytesIO(response.content)).convert("RGB")
# Inpainting需要用到的圖片
img_url = "https://raw.githubusercontent.com/CompVis/latent-
diffusion/main/data/inpainting_examples/overture-creations-
5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-
diffusion/main/data/ inpainting_examples/overture-creations-
5sI6fQgYIuo_mask.png"
init_image = download_image(img_url).resize((512, 512))
mask_image = download_image(mask_url).resize((512, 512))
device = (
"mps"
if torch.backends.mps.is_available()
else "cuda"
if torch.cuda.is_available()
else "cpu"
)? ? ? ?加載Stable Diffusion Pipeline,當(dāng)然可以通過(guò)model_id切換Stable Diffusion版本
# 載入管線
model_id = "stabilityai/stable-diffusion-2-1-base"
pipe = StableDiffusionPipeline.from_pretrained(model_id).to(device)如果GPU顯存不足,可以嘗試以下方法來(lái)減少GPU顯存的使用
pipe = StableDiffusionPipeline.from_pretrained(model_id,
revision="fp16",torch_dtype=torch.float16).to(device)pipe.enable_attention_slicing()# 給生成器設(shè)置一個(gè)隨機(jī)種子,這樣可以保證結(jié)果的可復(fù)現(xiàn)性
generator = torch.Generator(device=device).manual_seed(42)
# 運(yùn)行這個(gè)管線
pipe_output = pipe(
prompt="Palette knife painting of an autumn cityscape",
# 提示文字:哪些要生成
negative_prompt="Oversaturated, blurry, low quality",
# 提示文字:哪些不要生成
height=480, width=640, # 定義所生成圖片的尺寸
guidance_scale=8, # 提示文字的影響程度
num_inference_steps=35, # 定義一次生成需要多少個(gè)推理步驟
generator=generator # 設(shè)定隨機(jī)種子的生成器
)
# 查看生成結(jié)果,如圖6-7所示
pipe_output.images[0]
主要參數(shù)介紹:
width和height:用于指定生成圖片的尺寸,他們必須可以被8整除,否則VAE不能整除工作;
num_inference_steps:會(huì)影響生成圖片的質(zhì)量,采用默認(rèn)50即可,用戶也可以嘗試不同的值來(lái)對(duì)比一下效果;
negative_prompt:用于強(qiáng)調(diào)不希望生成的內(nèi)容,該參數(shù)一般在無(wú)分類器引導(dǎo)的情況下使用。列出一些不想要的特征,以幫助模型生成更好的結(jié)果;
guidance_scale:決定了無(wú)分類器引導(dǎo)的影響強(qiáng)度。增大這個(gè)參數(shù)可以使生成的內(nèi)容更接近給出的文本描述,但是參數(shù)值過(guò)大,則可能導(dǎo)致結(jié)果過(guò)于飽和,不美觀,如下圖所示:
cfg_scales = [1.1, 8, 12]
prompt = "A collie with a pink hat"
fig, axs = plt.subplots(1, len(cfg_scales), figsize=(16, 5))
for i, ax in enumerate(axs):
im = pipe(prompt, height=480, width=480,
guidance_scale=cfg_scales[i], num_inference_steps=35,
generator=torch.Generator(device=device).manual_seed(42)).
images[0]
ax.imshow(im); ax.set_title(f'CFG Scale {cfg_scales[i]}')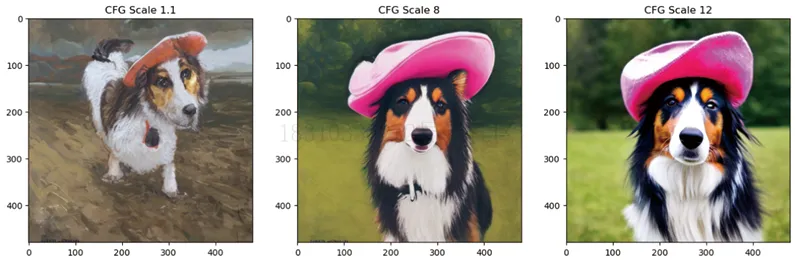
文章轉(zhuǎn)自微信公眾號(hào)@ArronAI
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)


安全的關(guān)鍵.png)



