
如何快速實現(xiàn)REST API集成以優(yōu)化業(yè)務(wù)流程
之所以會有限流這個問題,是因為我們生活在一個資源有限的社會當(dāng)中,當(dāng)資源供不應(yīng)求的時候,就會引發(fā)一系列的問題。為了避免資源問題,我們通常會增加對資源的限制,比如交通限行。回到 API 這個概念上同樣如此。
常見的 API 限流應(yīng)用場景主要包含以下 4 點:
現(xiàn)在我們大致了解了 API 限流主要解決的問題,我們也對 API 限流需要具備的能力做一些總結(jié)和歸納。
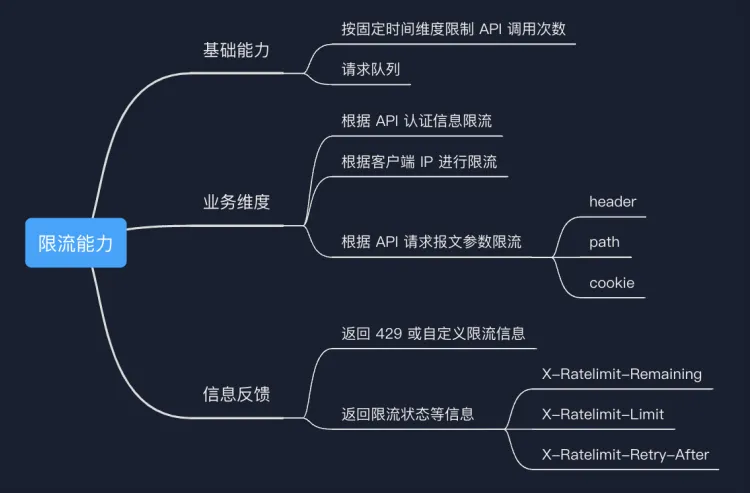
我將它分成了三類:
接下來,我們將會介紹限流中的幾種非常常見的算法,主要包括:
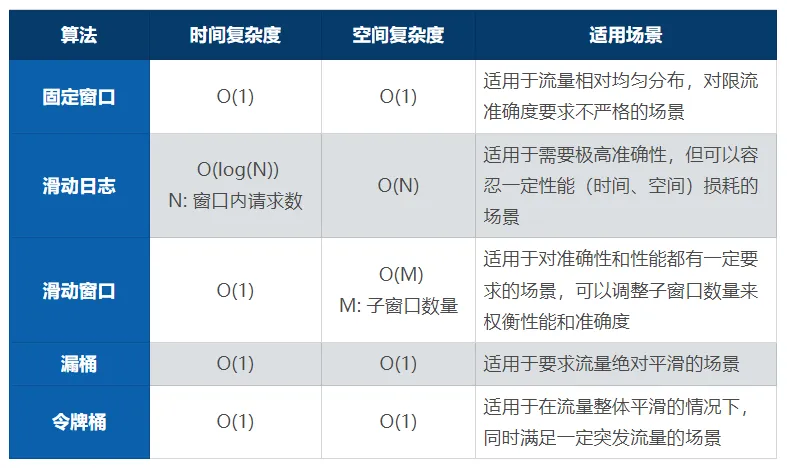
固定窗口是最常見的限流算法之一。其中窗口的概念,對應(yīng)限流場景當(dāng)中的限流時間單元。
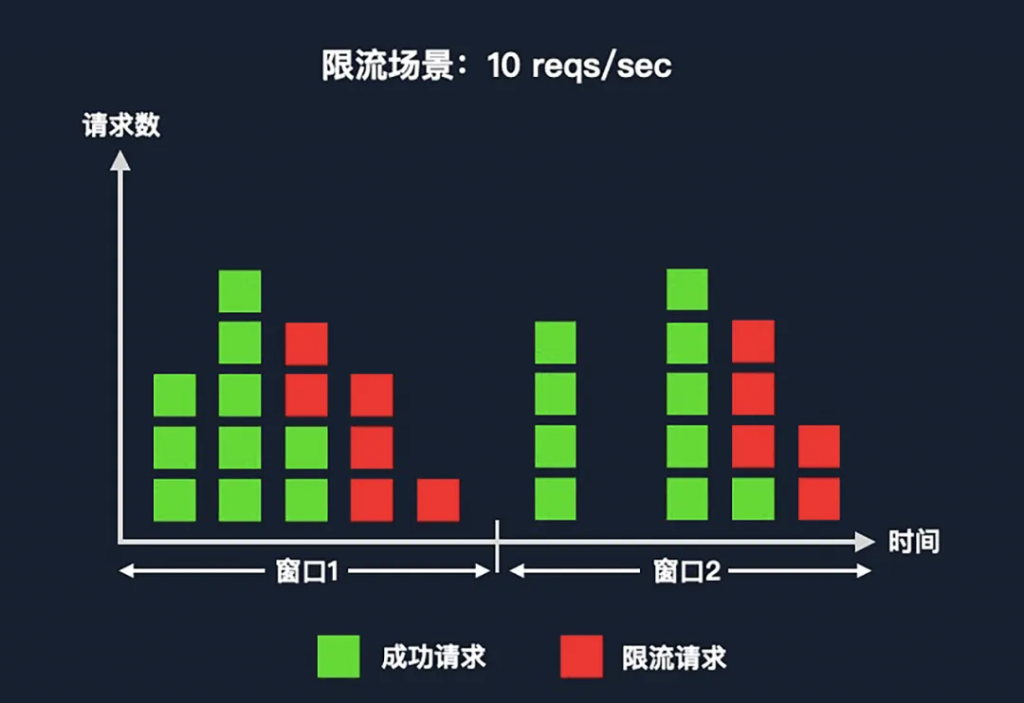
如上圖中的場景是每秒鐘限流 10 次,那么窗口大小就是 1 秒。可以看到,在第一個窗口當(dāng)中每一個方塊代表一個請求。綠色的方塊代表可以放通給后端的請求,紅色的方塊代表被限流的請求。在每秒鐘限流 10 次這個場景當(dāng)中,因為從左到右是時間維度,所以在窗口 1 中,先進來的 10 個請求會被放通,之后的請求會被限流(紅色方塊)。
優(yōu)勢
劣勢
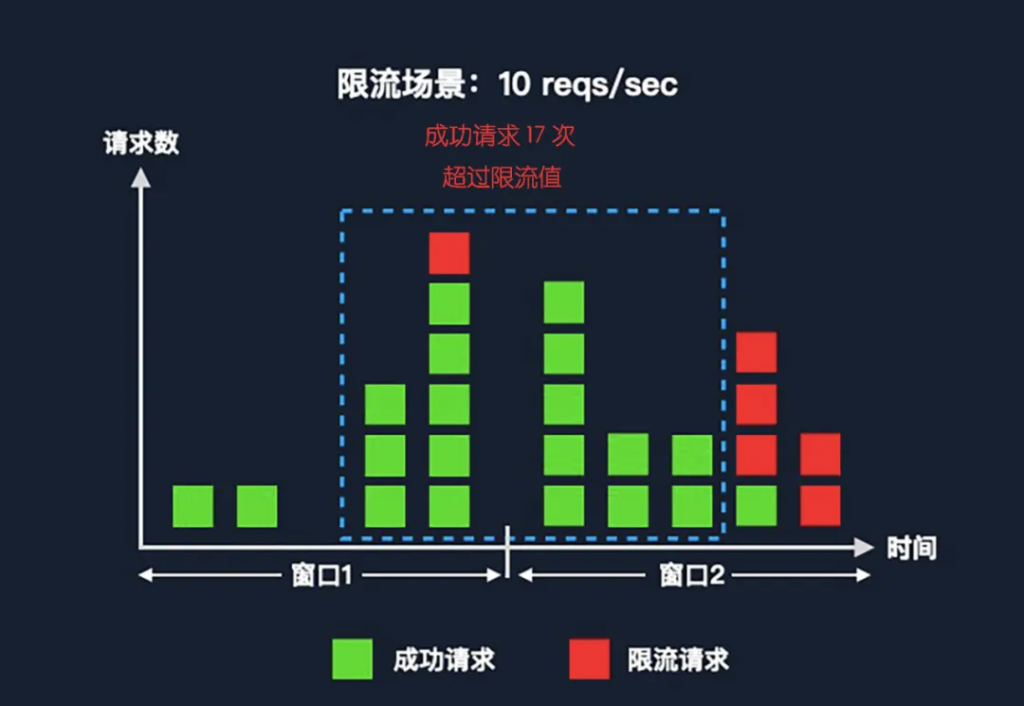
如上圖,分別看兩個固定窗口,窗口內(nèi)的有效請求都沒有超過限流值。但是我們?nèi)绻诖翱诮唤缣幗厝∫粋€新的窗口,窗口中的有效請求會超過我們限流的 10 次。極端情況下,至多會有兩倍于限流值的有效請求。這個問題在請求速率相對比較平穩(wěn)時,影響不大。但是由于我們通常沒有辦法控制客戶端的請求行為,所以說極端情況下,還是會對后端產(chǎn)生一些影響的。
這個問題出現(xiàn)的主要原因是窗口是固定的,那么我們?nèi)绻汛翱诟某蓜討B(tài)的,是否能解決?答案是肯定的。
在滑動日志算法中,我們需要維護每一條請求的日志。每當(dāng)一個新的請求過來之后,我們會根據(jù)該請求動態(tài)計算出來當(dāng)前窗口起始的邊界。因為我們已經(jīng)有時間戳了,所以向前遍歷就可以簡單地拿到邊界值,之后我們會根據(jù)窗口中請求計數(shù),和限流的值去對比,就能得出當(dāng)前請求是要被限流,還是要放通。
優(yōu)勢
劣勢
滑動窗口
滑動日志算法和固定窗口算法的優(yōu)缺點幾乎是完全相反的。那么我們將兩個算法折中一下,就有了第三個算法——滑動窗口。
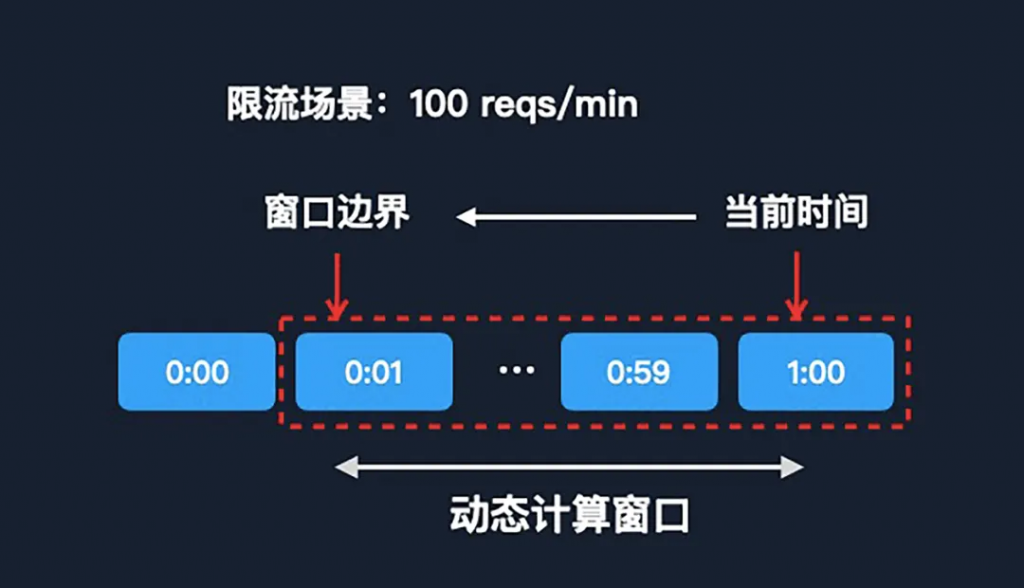
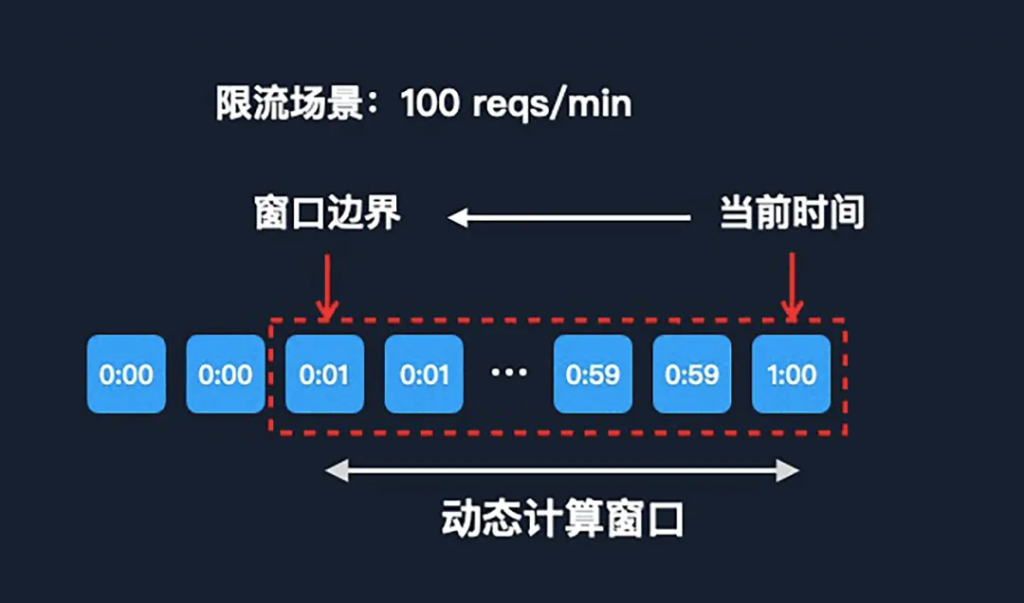
在滑動窗口的算法中,同樣需要針對當(dāng)前的請求來動態(tài)查詢窗口。但窗口中的每一個元素,不再是請求日志,而是子窗口。子窗口的概念類似于方案一中的固定窗口,子窗口的大小是可以動態(tài)調(diào)整的。
比如上圖中的場景是每分鐘限流 100 次。我們可以把每一個子窗口的時間維度設(shè)置為 1 秒,那么一分鐘的窗口,就有 60 個子窗口。這樣每當(dāng)一個請求來了之后,我們?nèi)討B(tài)計算這個窗口的時候,我們向前最多只需找 60 次。這樣時間復(fù)雜度,就可以從線性變成常量級了,時間的復(fù)雜度相對來說也會更低了。
滑動窗口算法是前兩個算法的折中,它在性能上明顯優(yōu)于第二種,但是它的準(zhǔn)確度又差于第二種,所以它是一個比較平衡的算法。漏桶算法
接下來要介紹兩種算法,都跟桶有關(guān),第一種叫漏桶算法。
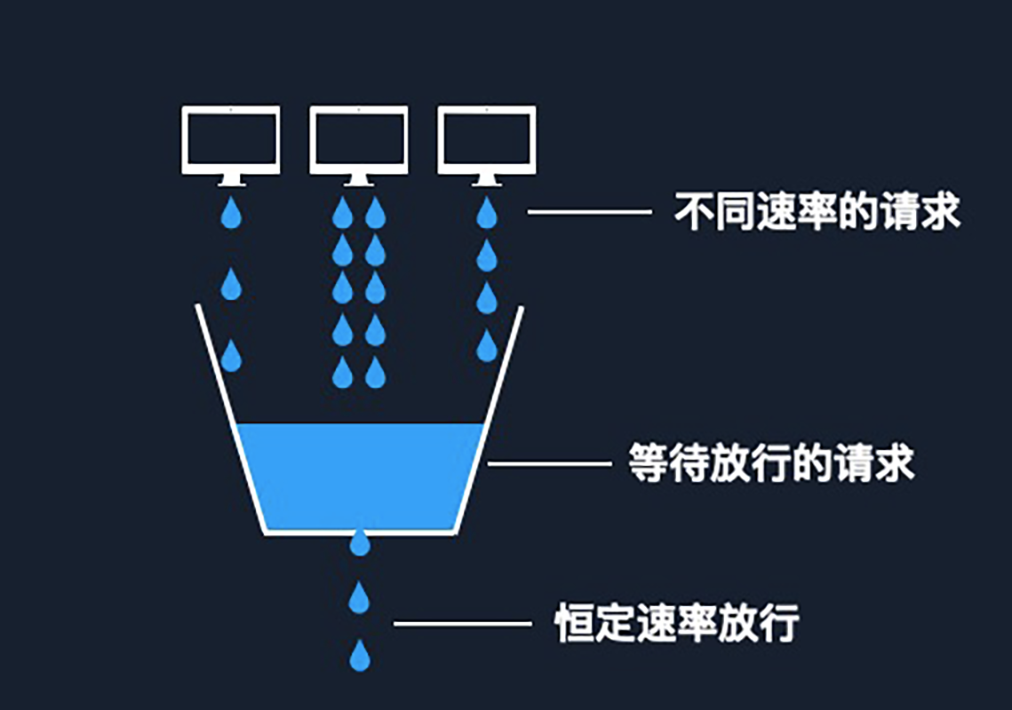
如圖所示,在漏桶算法中,我們把每一次請求當(dāng)成一個小水滴,水滴到限流組件后,我們會先把它儲存在一個桶中。這個桶的底部有一個洞,會勻速地向外漏水。我們把漏水的過程當(dāng)成請求放通的過程,請求進來的速率是不能控制的,不同客戶端可能有不同的速率請求。但是由于桶洞的大小可控,所以我們能保證請求轉(zhuǎn)發(fā)的速率上限。
在漏桶算法當(dāng)中,桶的大小控制了系統(tǒng)能夠處理的最大并發(fā)數(shù),而實際的限流值是取決于桶最終往外漏水的流速。雖然我們把它具象成了一個桶,但從技術(shù)角度理解,它更像是一個 FIFO 隊列。
優(yōu)勢
劣勢
令牌桶
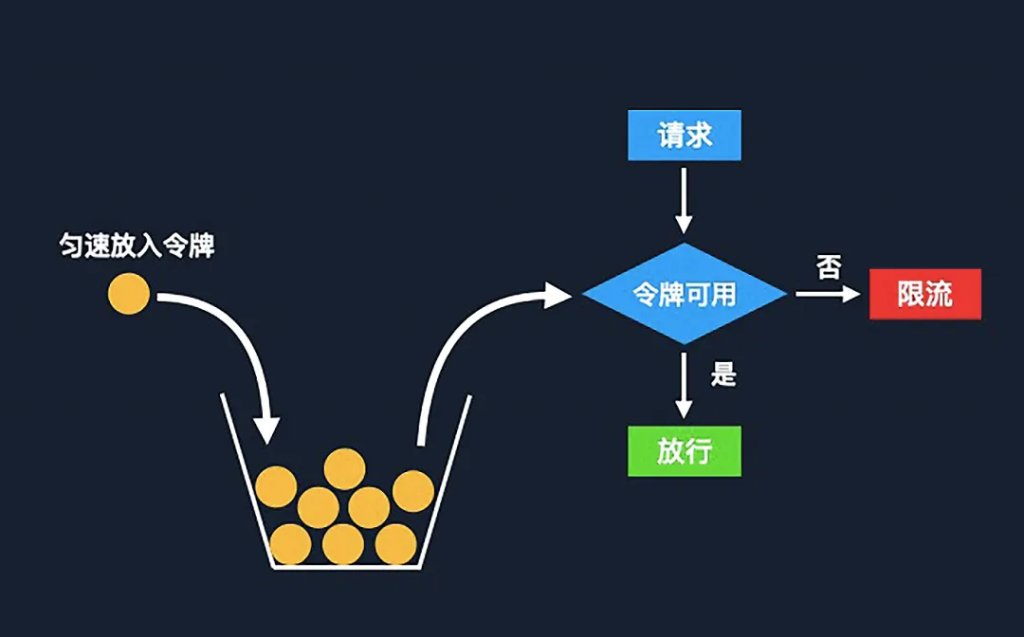
令牌桶算法是基于漏桶之上的一種改進版本,在令牌桶中,令牌代表當(dāng)前系統(tǒng)允許的請求上限,令牌會勻速被放入桶中。當(dāng)桶滿了之后,新的令牌就會被丟棄。每當(dāng)有一個新的請求過來的時候,我們就嘗試去桶中拿取一個令牌。如果桶中有空閑令牌,請求就可以放通;如果沒有,請求將會被限流。
這個算法跟漏桶比起來,最大的區(qū)別就是我們可以允許短時間的流量突增。因為在漏桶算法中,不管同時進來多少個請求,我們只能勻速地放行。但是在令牌桶當(dāng)中,我們可以同時往后放行的請求數(shù)取決于桶中最大的令牌數(shù)量,也就是桶的容量。
優(yōu)勢
劣勢
小結(jié):各算法的適用場景
剛才介紹到的幾種限流算法,就像在學(xué)習(xí)一門劍法時,我們掌握了的基本劍術(shù),比如砍、劈、刺等。那么為了將這些基本的劍法應(yīng)用到最終的實戰(zhàn)當(dāng)中,就需要要結(jié)合具體的實戰(zhàn)場景來針對性分析。在分布式限流的場景當(dāng)中,我們設(shè)計方案前,先要看一下限流設(shè)計時要考慮的要點。準(zhǔn)確性
首先要關(guān)注的就是多次提到的準(zhǔn)確性。在分布式架構(gòu)當(dāng)中,同一個數(shù)據(jù)的多次操作可能在不同的節(jié)點上執(zhí)行。這個時候我們就需要保證分布式系統(tǒng)中數(shù)據(jù)的一致性,這樣才能保障多次操作的準(zhǔn)確性。
另外,我們要保證限流操作的原子性。在分布式架構(gòu)當(dāng)中,同一個業(yè)務(wù)操作往往包含多個子命令,子命令之間如果有其他操作干擾,會導(dǎo)致每次執(zhí)行的結(jié)果不確定,那么就無法保證業(yè)務(wù)操作的準(zhǔn)確性。
舉個例子,在固定窗口算法當(dāng)中,我們需要先判斷當(dāng)前計數(shù)器窗口是否過期。如果是還在當(dāng)前窗口,就直接計數(shù)加一;如果已經(jīng)過期,我們就需要重新創(chuàng)建一個新的窗口。
if redis.call('ttl', KEY) < 0 then # 檢查限流 Key 是否過期
2 redis.call('set', KEY, COUNT, 'EX', EXP) # 設(shè)置 Key 的初始值以及過期時間
3 return COUNT
4 end
5
6 return redis.call('incrby', KEY, 1) # 計數(shù)這里有一次讀和一次寫,如果在讀寫過程當(dāng)中又有其他的操作,對操作的 Key 做了變更,可能使讀到的結(jié)果被改變,就可能會導(dǎo)致在限流過程中出現(xiàn)一些數(shù)據(jù)的誤判。所以,我們需要保證該讀寫操作的原子性。性能
第二點就是性能。雖然不是只有分布式架構(gòu)才需要關(guān)注性能,但在分布式架構(gòu)當(dāng)中很可能增加分布式邏輯以及額外的鏈路,我們需要考慮由于分布式引起的性能額外的開銷,對于業(yè)務(wù)來說是否可以接受。可擴展性
第三點是可擴展性。我們選擇分布式架構(gòu)一個主要的原因,就是為了架構(gòu)能夠平滑擴展。這里擴展主要包含兩個方面:橫向擴展、縱向擴展。
針對 API 限流的場景,橫向擴展是指當(dāng) API 數(shù)量增加后,需要平滑地支持更多 API 對象的限流。因為每個 API 對象的限流值不一樣,我們需要保證每一個 API 的限流實體能夠進行獨立的限流判斷,不能互相影響。縱向擴展是指特定 API 的調(diào)用量、并發(fā)量,由于業(yè)務(wù)增長,可能會從幾百增長到幾萬,那么我們的限流也需要能支撐相應(yīng)的請求量。可用性
最后一點就是可用性。我們知道限流是保護系統(tǒng)可用性的非常重要的一個環(huán)節(jié),其本身的可用性也是非常重要的。如果限流這個環(huán)節(jié)出現(xiàn)故障,很可能引發(fā)一系列的雪災(zāi)效應(yīng)。要保證限流系統(tǒng)的可用性,我這里列舉了幾個需要考量的點:
1. 避免鏈路上的單點故障
2. 如果出現(xiàn)故障,需要有相應(yīng)的降級策略
3.關(guān)鍵指標(biāo)的可觀測性
現(xiàn)在我們了解了 API 限流系統(tǒng)設(shè)計在分布式架構(gòu)中需要關(guān)注的主要技術(shù)點,接下來我們結(jié)合騰訊云 API 網(wǎng)關(guān)產(chǎn)品的案例,一起看下具體實踐的過程。API 網(wǎng)關(guān)限流需求分析
在我們設(shè)計系統(tǒng)方案之前,我們首先要明確需求,對于 API 網(wǎng)關(guān)這類產(chǎn)品來說,它主要的限流功能需求,大概可以分成了三類:
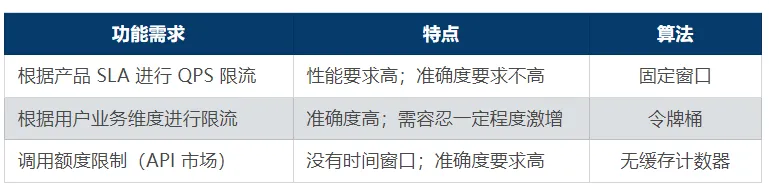
第一類是針對產(chǎn)品 SLA 的限流。因為 API 網(wǎng)關(guān)有不同規(guī)格的用戶實例,不同的實例對應(yīng)不同的 QPS 上限。這類需求的特點是:
結(jié)合之前介紹的算法特點,SLA 的需求場景下,我們采用的固定窗口的算法。
第二類需求是用戶業(yè)務(wù)維度的自定義限流。針對不同的 API 配置不同的限流值,保護對應(yīng)的后端。這類需求的特點是:
針對這類需求,使用令牌桶算法會更合適。
第三類需求是 API 市場的場景。比如,用戶可以將自己的 API 上架到市場,同時配置一定的調(diào)用額度,調(diào)用者每調(diào)用一次,都需要支付一定的費用。
這類需求對于準(zhǔn)確性要求極高,所以這里我們選擇的是計數(shù)器數(shù)據(jù)結(jié)構(gòu)。
除了功能需求之外,在性能上也需要提前規(guī)劃,比如單集群需要能夠支持百萬的 QPS,單 API 能支持十萬的 QPS,同時也需要能夠支持平滑地橫向擴展。方案一:基于 Redis 中心存儲
針對以上 API 網(wǎng)關(guān)產(chǎn)品需求,我們最終選擇的是基于 Redis 中心存儲的方案。其原因主要有:
當(dāng)然從技術(shù)的角度來看,也完全可以采用其他的 KV 存儲,比如 memcached + proxy 的方式,具體要結(jié)合實際業(yè)務(wù)和技術(shù)團隊的情況來做決策。
最初的方案在邏輯上是非常簡單,請求到達 API 網(wǎng)關(guān)后,網(wǎng)關(guān)會先通過 Redis 中的實時計算(針對不同的場景使用不同的限流算法),判斷是否要對本次 API 請求進行限流。
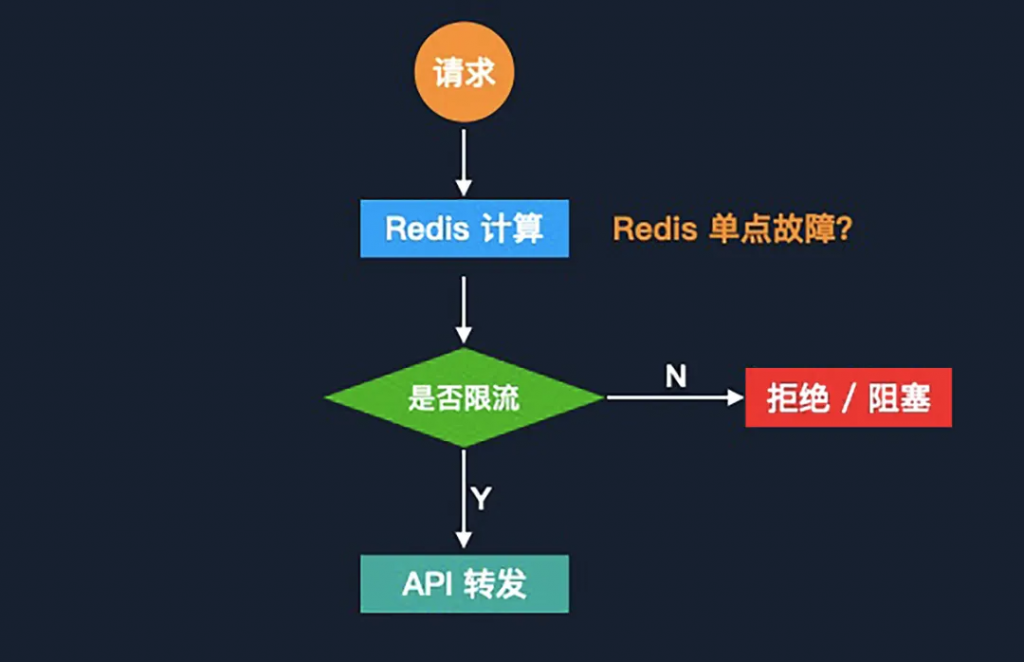
在這個鏈路當(dāng)中,Redis 成為了一個關(guān)鍵環(huán)節(jié),那么它本身的單點故障的風(fēng)險也需要被重點考慮。針對 Redis 單點故障的情況,我們會將限流降級到本地進程級別來處理。降級后,由于沒有了中心存儲保證數(shù)據(jù)一致性,所以我們需要通過提前計算節(jié)點數(shù)量和每個節(jié)點的進程數(shù)量,來計算每個進程的限流值,這些進程限流值累加起來會接近于分布式限流的限流值。
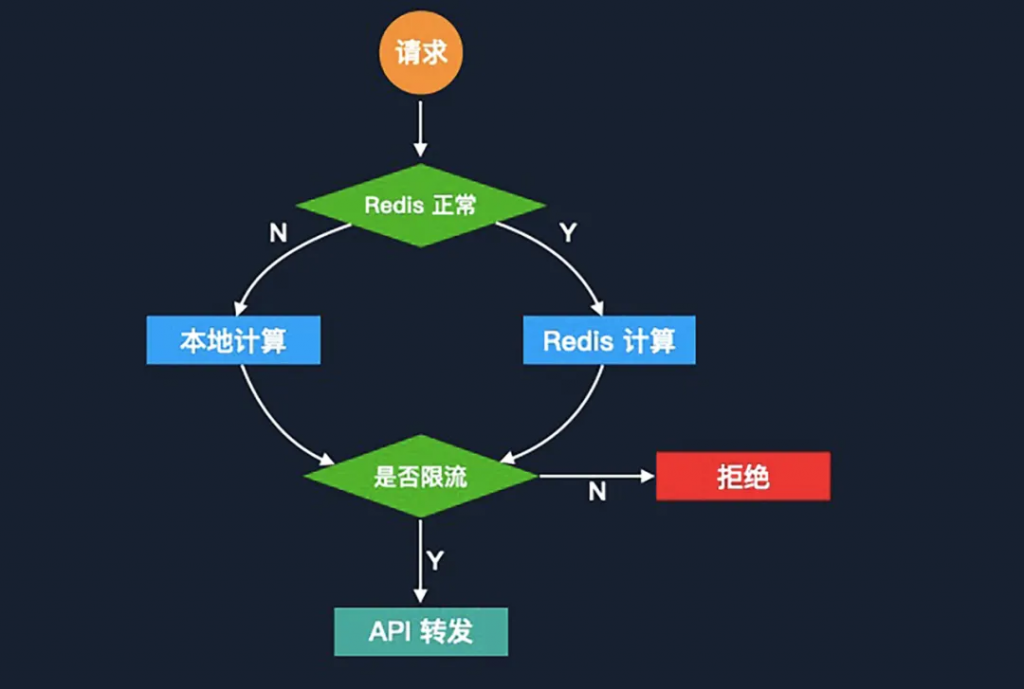
舉個例子,假設(shè)我們現(xiàn)在全局限流是每分鐘 1000 次。我們有兩個節(jié)點,每個節(jié)點有八個進程。這個時候可以做一個簡單的除法,就能得出來每個進程的限流值大約是 1000/2/8=62.5。但由于節(jié)點進程之間的流量無法保證完全均勻,所以它存在一定的準(zhǔn)確度下降的情況,但是在故障降級這種場景當(dāng)中是可以接受的。
還有一點非常重要,就是在 Redis 恢復(fù)之后,仍然是需要將本地的數(shù)據(jù)同步回 Redis,避免出現(xiàn)限流窗口被重置,影響后端業(yè)務(wù)的情況。方案要點
優(yōu)勢
劣勢
?性能優(yōu)化點:異步數(shù)據(jù)同步
針對上述提到的縱向擴展以及額外延遲的劣勢,我們對方案進行了優(yōu)化。
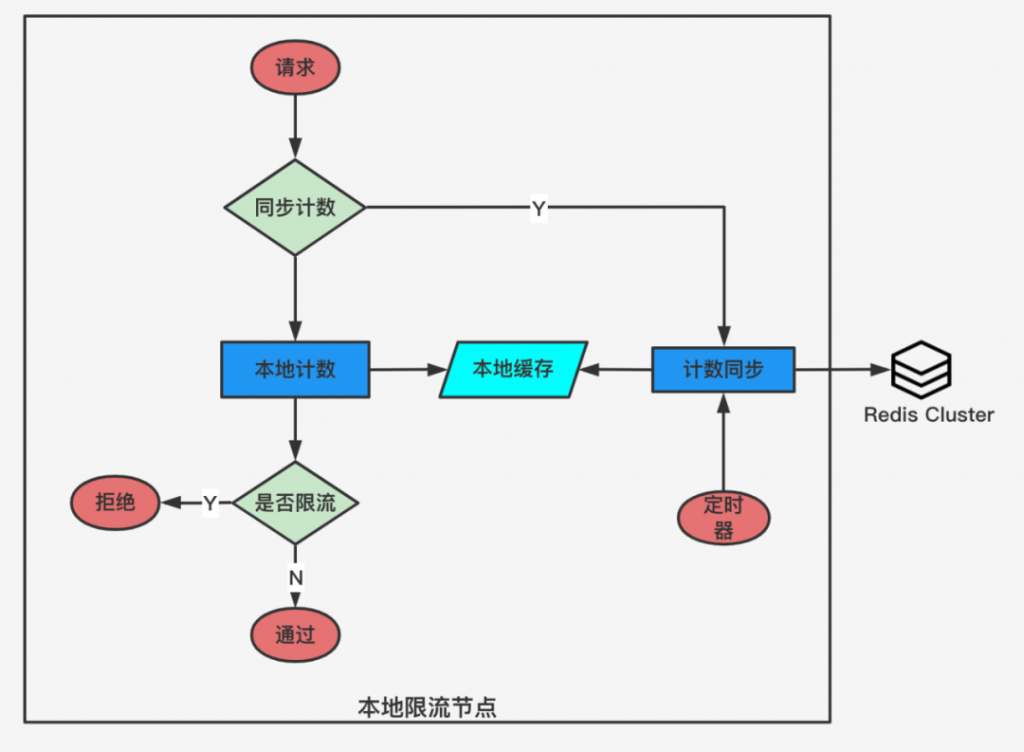
核心的優(yōu)化思路就是把同步限流計算變成異步批量同步,避免 Redis 成為瓶頸。限流主要包含兩個階段:
該方案的主要問題是,如果在異步同步前,網(wǎng)關(guān)接收到了大量并發(fā)請求,可能導(dǎo)致限流擊穿,引發(fā)后端的雪崩效應(yīng)。針對這個問題,我們增加了一個額外的環(huán)節(jié),叫做同步計數(shù)檢查。每一個請求來了之后,我們會先檢查本地計數(shù)器是否超過了全局限流閾值的一定百分比,如果超過了,那么要強制進行 Redis 限流計算和同步。
舉個例子,假設(shè)限流每分鐘 100 次請求,我們設(shè)置本地限流不能超過全局限流的 10%,如果本地內(nèi)存計數(shù)超過了 10 次,就會在請求過程中同步觸發(fā)一次強制的同步。通過這個機制,我們可以保證大部分請求的性能的同時,避免出現(xiàn)請求突增把限流打穿的場景。優(yōu)勢
劣勢
方案二:負載均衡 + 本地限流
除了中心存儲的方案之外,我也了解過幾種適用于分布式架構(gòu)的限流方案,各有特點。第二個要介紹的方案是基于負載均衡將請求分發(fā)給多個服務(wù)節(jié)點,通過每個服務(wù)節(jié)點上的反向代理網(wǎng)關(guān)實現(xiàn)本地節(jié)點限流。
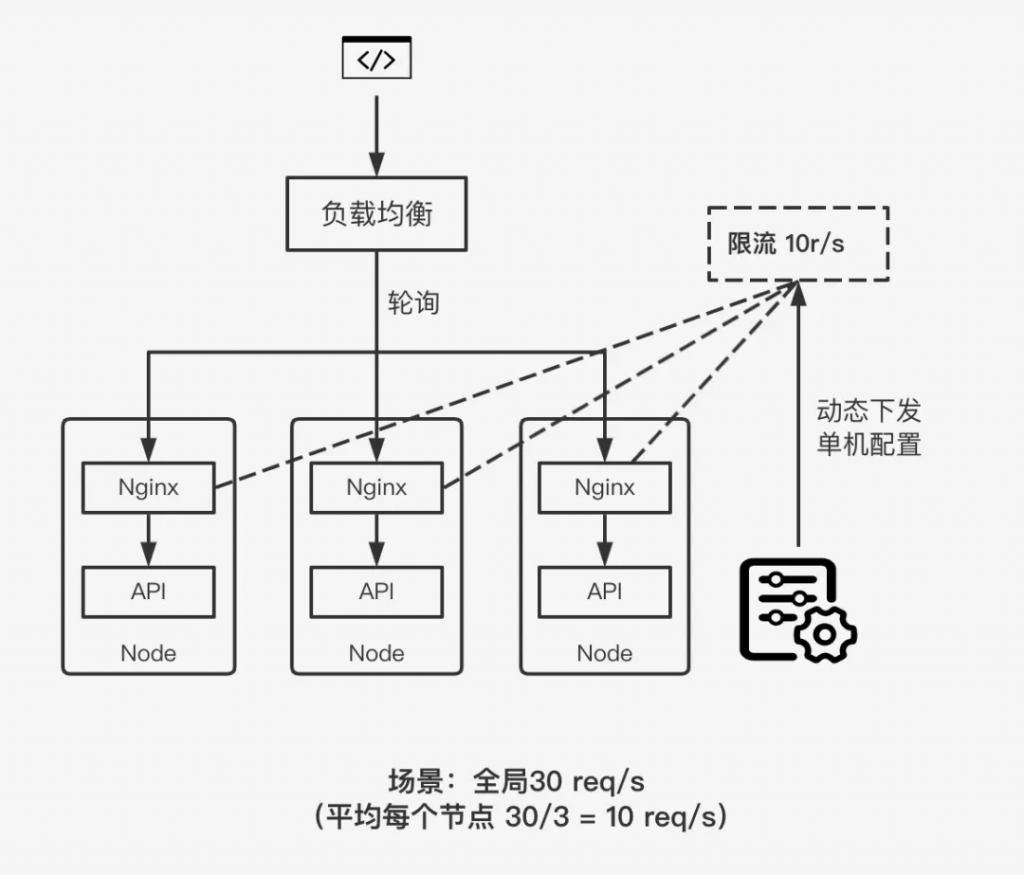
這個方案中,請求會通過負載均衡分發(fā)給不同的 API 服務(wù)節(jié)點。在每一個服務(wù)節(jié)點之上會部署一個 Nginx 的反應(yīng)代理服務(wù)器,通過 Nginx 的 limit_req 模塊配置本地限流。我們的核心思路是將一個分布式的限流負載均衡后轉(zhuǎn)化成了每個節(jié)點的本地限流。和上一個方案的本地限流場景類似,我們同樣需要根據(jù)節(jié)點數(shù)量來計算每個節(jié)點的限流值。優(yōu)勢
劣勢
方案三:一致性哈希
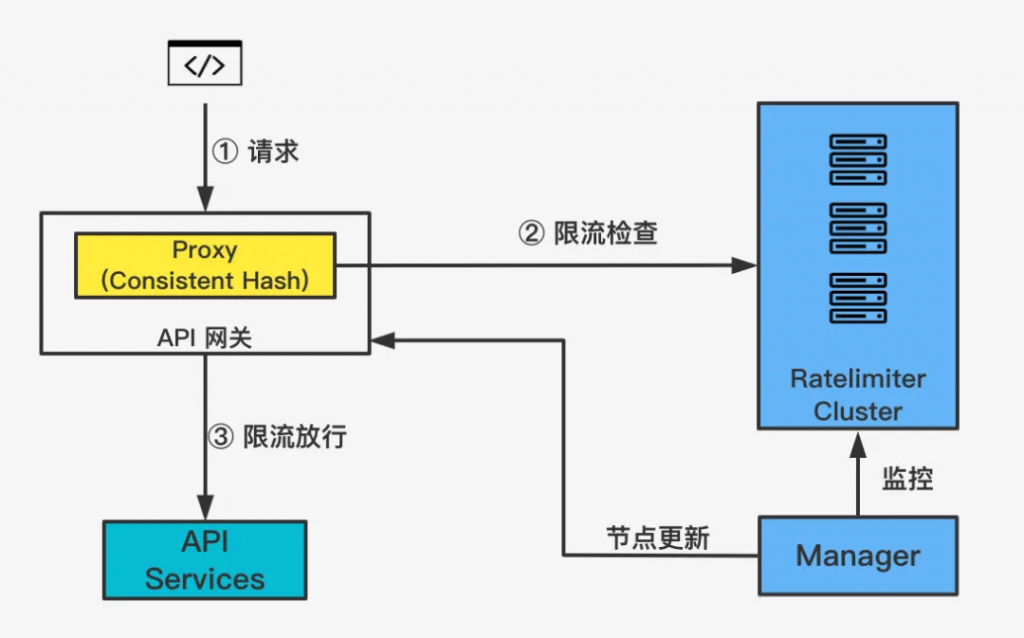
第三個方案跟第一個中心存儲的方案類似,都是采用了中心化限流的設(shè)計思路。這個方案沒有依賴中心存儲,而是通過一致性哈希算法對限流對象的 Key 哈希后分配到一個固定的限流節(jié)點上。這個 API 后續(xù)請求就都會落到同一個節(jié)點上,所以本質(zhì)上我們還是將分布式限流,轉(zhuǎn)化成了節(jié)點的本地限流來解決。優(yōu)勢
劣勢
方案四:客戶端限流
第四個方案是客戶端限流,可能有人會問,客戶端限流跟服務(wù)端的區(qū)別到底是什么?
我們可以通過一個現(xiàn)實的例子,來更好的理解這個問題。假設(shè)我計劃第二天去動物園,這個時候我有兩種方式購票。第一種是我第二天直接去動物園門口去買票,但有可能我到那之后發(fā)現(xiàn)票賣光了,會導(dǎo)致我在路上的時間都浪費掉了。另外一種方式就是我提前一天預(yù)約購票,這樣就可以提前確認是否可以成行,避免出現(xiàn)浪費時間的情況。
再回到客戶端限流這個場景中,如果我們把限流這個環(huán)節(jié)從服務(wù)端移到客戶端的話,我們可以盡早地避免這些被限流的請求發(fā)生,節(jié)約更多的資源。但是為了實現(xiàn)在客戶端側(cè)的限流,我們需要一些額外的機制。
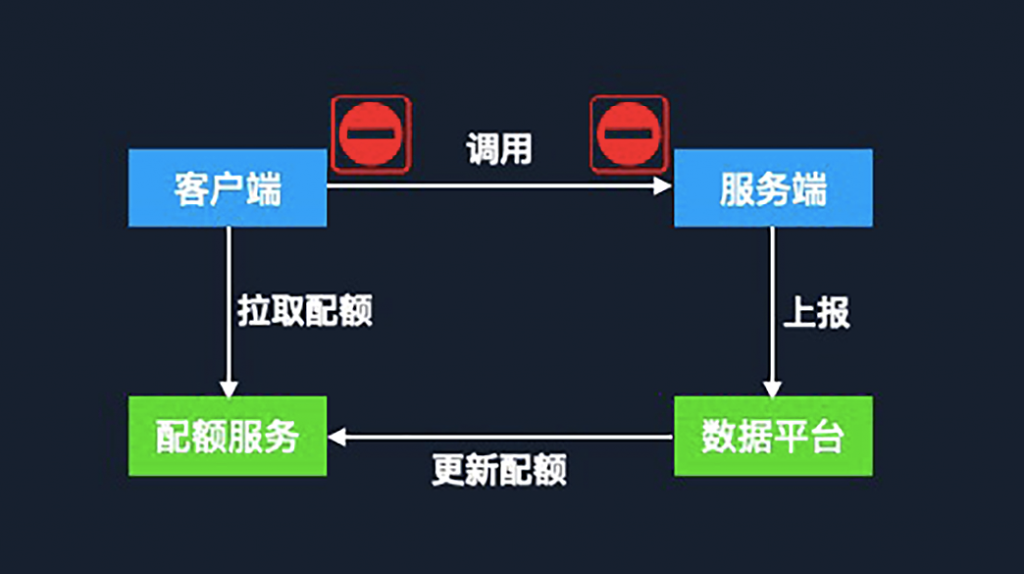
首先,我們需要一個配額服務(wù)來管理服務(wù)端能承載的最大配額,同時根據(jù)客戶端訴求,將配額分發(fā)給每個客戶端。這個配額服務(wù)就起到了協(xié)調(diào)器的作用,它能夠保證在整個服務(wù)調(diào)用鏈當(dāng)中所有的客戶端調(diào)用總和不超過服務(wù)端的配額大小。那它的配額從哪來呢?
我們還需要另外一個數(shù)據(jù)平臺,它從服務(wù)端采集到服務(wù)的負載狀態(tài)等信息,通過實時分析,計算出服務(wù)能夠承載的請求上限。之后再將數(shù)據(jù)更新到配額服務(wù)中,最后由配額服務(wù)重新復(fù)配給客戶端,這樣就完成了一個周期。
可以看到,它在架構(gòu)上相對前面的方案來說會增加一些復(fù)雜性,但同時更靈活,因為每個客戶端可以根據(jù)自己的屬性、標(biāo)簽來獲取它自己想要的配額。最終是否能分發(fā)給客戶端這么多配額,是由配額服務(wù)上面的一些配置策略決定的。我們甚至還可以基于 AI 算法通過歷史數(shù)據(jù)來預(yù)測未來的一些配額可能發(fā)生變化,來對配額進行預(yù)分配。
可以看到,在客戶端限流方案當(dāng)中,它需要客戶端是可控的,因為我們需要在客戶端側(cè)做很多邏輯。如果這個客戶端不可控,某一個客戶端沒有按照協(xié)定的配額來進行請求,則會打破整體的規(guī)則。優(yōu)勢
劣勢
思路參考—— Google Doorman:
https://github.com/youtube/doorman方案對比
前面介紹了四種分布式限流當(dāng)中的方案,每一種方案都有它的優(yōu)勢和缺點,沒有哪一種是完美的。所以在我們選擇方案時,還是要針對自己的業(yè)務(wù)需求,在多個方案的優(yōu)缺點中進行取舍,來選擇最適合的場景。

思考
在限流設(shè)計當(dāng)中,不管采用哪種方案,都會有些共性的設(shè)計考慮點:
最后我們還是要總結(jié)一下,設(shè)計限流系統(tǒng)的幾個關(guān)鍵步驟。收集需求
一開始,不要著急去選擇算法和設(shè)計方案,而是先把需求梳理清楚,比如產(chǎn)品有哪些場景會用到限流?系統(tǒng)上都需要考慮哪些關(guān)鍵點?目前公司是否已經(jīng)有現(xiàn)成的方案?這些都是決定了我們后面決策的一些重要因素。選擇算法
根據(jù)業(yè)務(wù)場景來選擇合適的算法,這里你可以重點參考算法的對比表格。設(shè)計方案
在方案設(shè)計的時候,根據(jù)收集到的需求來選擇一個合適的技術(shù)架構(gòu)。如果公司內(nèi)部已經(jīng)有現(xiàn)成的限流系統(tǒng),我們也可以去考慮一下是不是可以避免重復(fù)造輪子。最后要額外強調(diào)的是,限流是保護服務(wù)的一個兜底手段,所以要重點考慮限流系統(tǒng)本身的穩(wěn)定性機制(容災(zāi)、降級、監(jiān)控等)。
本文章轉(zhuǎn)載微信公眾號@InfoQ



鍵.png)



