
如何快速實現REST API集成以優化業務流程
從文檔處理角度來看,實現流程如下:
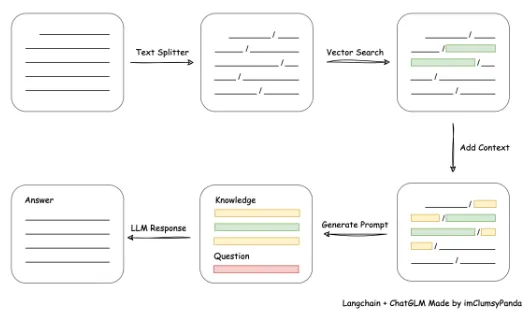
本項目未涉及微調、訓練過程,但可利用微調或訓練對本項目效果進行優化。核心部分代碼為:
執行初始化
init_cfg(LLM_MODEL, EMBEDDING_MODEL, LLM_HISTORY_LEN)
# 使用 ChatGLM 的 readme 進行測試
vector_store = init_knowledge_vector_store("/home/mw/project/test_chatglm_readme.md")中vector_store的初始化可以傳遞 txt、docx、md 格式文件,或者包含md文件的目錄。更多知識庫加載方式可以參考langchain文檔,通過修改 init_knowledge_vector_store 方法進行兼容。
官方注:ModelWhale GPU機型需要從云廠商拉取算力資源,耗時5~10min,且會預扣半小時資源價格的鯨幣。如果資源未啟動成功,預扣費用會在關閉編程頁面后五分鐘內退回,無需緊張,如遇問題歡迎提報工單,客服會及時處理。
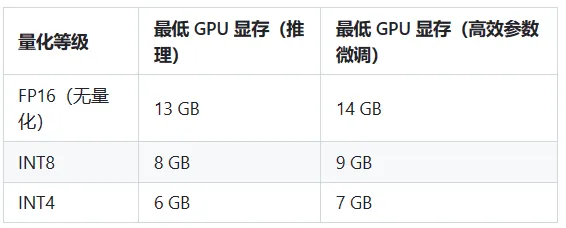
注:如未將模型下載至本地,請執行前檢查$HOME/.cache/huggingface/文件夾剩余空間,模型文件下載至本地需要15GB存儲空間。?
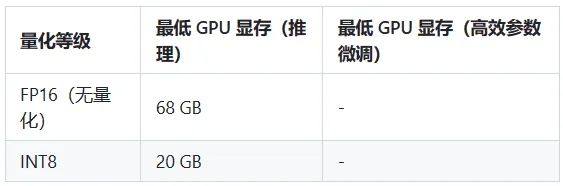
注:如未將模型下載至本地,請執行前檢查$HOME/.cache/huggingface/文件夾剩余空間,模型文件下載至本地需要70GB存儲空間
為了能讓容器使用主機GPU資源,需要在主機上安裝?NVIDIA Container Toolkit。具體安裝步驟如下:
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit-base
sudo systemctl daemon-reload
sudo systemctl restart docker安裝完成后,可以使用以下命令編譯鏡像和啟動容器:
docker build -f Dockerfile-cuda -t chatglm-cuda:latest .
docker run --gpus all -d --name chatglm -p 7860:7860 chatglm-cuda:latest
#若要使用離線模型,請配置好模型路徑,然后此repo掛載到Container
docker run --gpus all -d --name chatglm -p 7860:7860 -v ~/github/langchain-ChatGLM:/chatGLM chatglm-cuda:latest軟件需求
本項目已在 Python 3.8.1 – 3.10,CUDA 11.7 環境下完成測試。已在 Windows、ARM 架構的 macOS、Linux 系統中完成測試。
vue前端需要node18環境
從本地加載模型
請參考 THUDM/ChatGLM-6B#從本地加載模型
環境檢查
# 首先,確信你的機器安裝了 Python 3.8 及以上版本
$ python --version
Python 3.8.13
# 如果低于這個版本,可使用conda安裝環境
$ conda create -p /your_path/env_name python=3.8
# 激活環境
$ source activate /your_path/env_name
$ pip3 install --upgrade pip
# 關閉環境
$ source deactivate /your_path/env_name
# 刪除環境
$ conda env remove -p /your_path/env_name項目依賴
# 拉取倉庫
$ git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
# 進入目錄
$ cd langchain-ChatGLM
# 項目中 pdf 加載由先前的 detectron2 替換為使用 paddleocr,如果之前有安裝過 detectron2 需要先完成卸載避免引發 tools 沖突
$ pip uninstall detectron2
# 檢查paddleocr依賴,linux環境下paddleocr依賴libX11,libXext
$ yum install libX11
$ yum install libXext
# 安裝依賴
$ pip install -r requirements.txt
# 驗證paddleocr是否成功,首次運行會下載約18M模型到~/.paddleocr
$ python loader/image_loader.py在開始執行 Web UI 或命令行交互前,請先檢查?configs/model_config.py?中的各項模型參數設計是否符合需求。
如需通過 fastchat 以 api 形式調用 llm,請參考?fastchat 調用實現
注:鑒于環境部署過程中可能遇到問題,建議首先測試命令行腳本。建議命令行腳本測試可正常運行后再運行 Web UI。
執行?cli_demo.py?腳本體驗命令行交互:
$ python cli_demo.py或執行?webui.py?腳本體驗?Web 交互
$ python webui.py或執行?api.py?利用 fastapi 部署 API
$ python api.py或成功部署 API 后,執行以下腳本體驗基于 VUE 的前端頁面
$ cd views
$ pnpm i
$ npm run devVUE 前端界面如下圖所示:
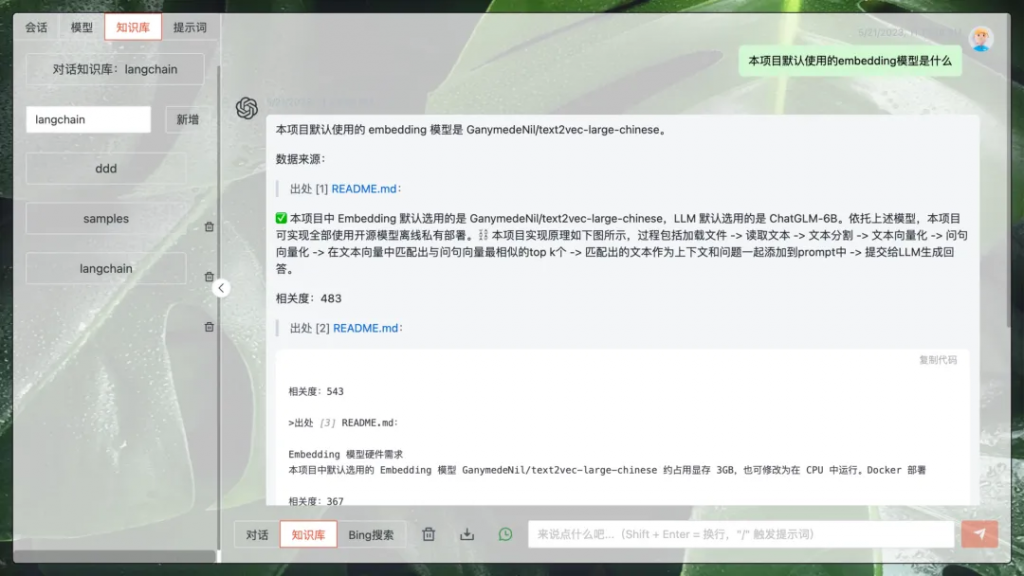
知識問答界面
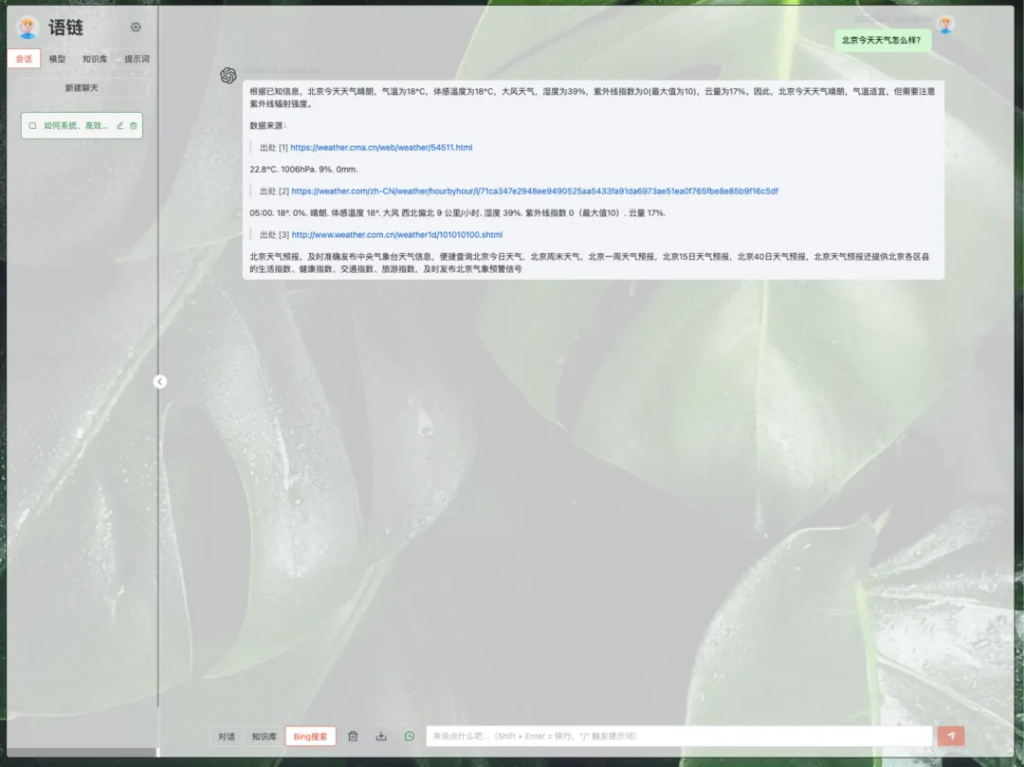
bing搜索界面
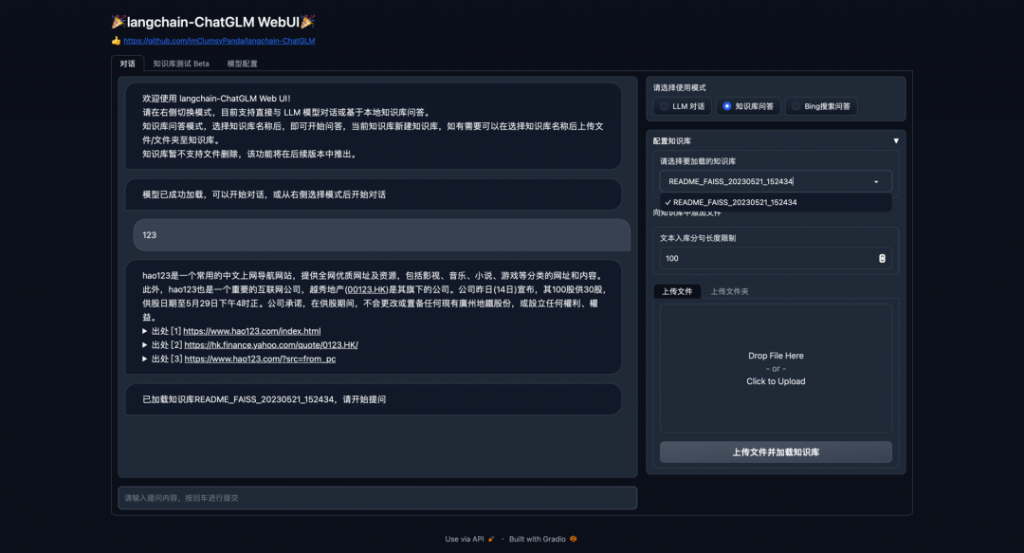
WebUI 界面如下圖所示:
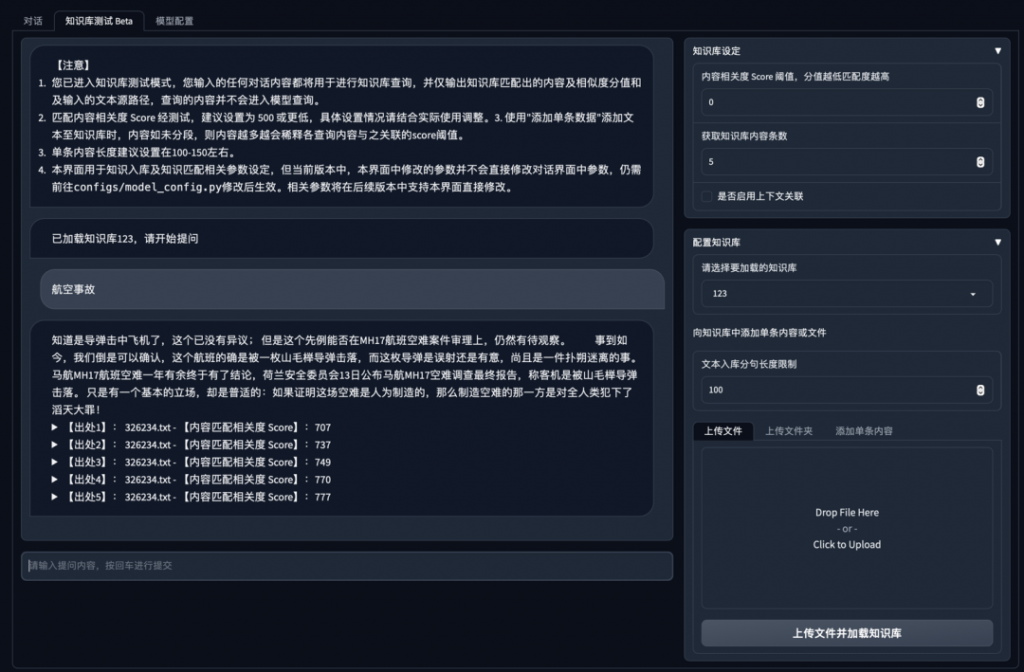
知識庫測試Beta?Tab界面
模型配置Tab界面
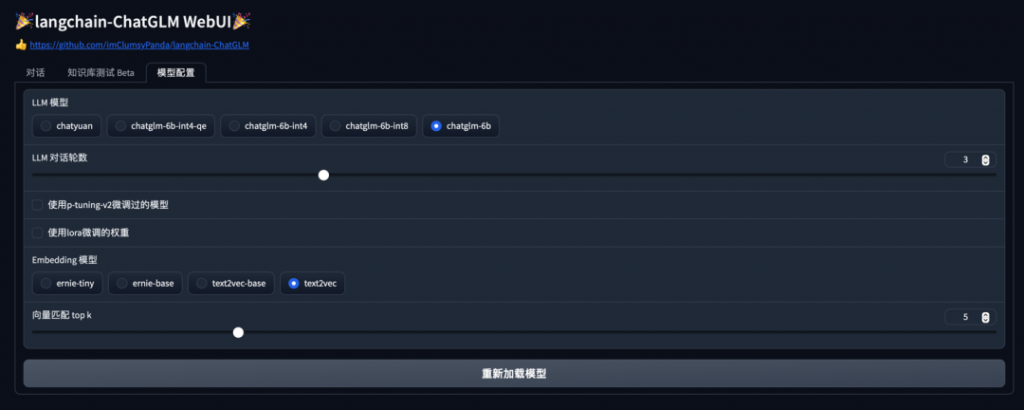
Web UI 可以實現如下功能:
本文章轉載微信公眾號@計算機視覺研究院







