
如何用AI進行情感分析
Multi-Agent Orchestrator針對每個用戶請求遵循一個特定流程:
1. 請求發(fā)起:用戶向編排器發(fā)送請求。
2. 分類:分類器使用大型語言模型(LLM)分析用戶的請求、代理描述以及當前用戶ID和會話ID下所有代理的對話歷史。這種全面的視角使分類器能夠理解所有代理之間正在進行的對話和上下文。
分類器確定以下情況中最合適的代理:
3. 代理選擇:分類器返回所選代理的名稱。
4. 請求路由:用戶的輸入被發(fā)送到所選代理。
5. 代理處理:所選代理處理請求。它會自動檢索當前用戶ID和會話ID下的自己的對話歷史。這確保了每個代理在無法訪問其他代理對話的情況下保持自己的上下文。
6. 響應生成:代理生成響應,該響應可能會以標準響應模式發(fā)送,也可能會通過流式傳輸發(fā)送,具體取決于代理的能力和初始化設置。
7. 對話存儲:編排器自動處理將用戶的輸入和代理的響應保存到特定用戶ID和會話ID的存儲中。這一步驟對于保持上下文和啟用連貫的多輪對話至關重要。關于存儲的關鍵點:
8. 響應傳遞:編排器將代理的響應傳遞回用戶。
此流程確保每個請求都由最合適的代理處理,同時在整個對話過程中保持上下文。分類器具有所有代理對話的全局視圖,而單個代理只能訪問自己的對話歷史。這種架構允許進行智能路由和上下文感知響應,同時保持代理功能之間的分離。
編排器對對話保存和檢索的自動處理,以及靈活的存儲選項,為管理多代理場景中的對話上下文提供了一個強大且可定制的系統(tǒng)。自定義或替換分類器和代理的能力為根據特定需求定制系統(tǒng)提供了進一步的靈活性。
Multi-Agent Orchestrator框架使您能夠利用多個代理來處理各種任務。
在框架上下文中,代理可以是以下任一項(或一項或多項的組合):
這種靈活的架構允許您根據應用程序的需求融入盡可能多的代理,并以最適合您需求的方式將它們組合在一起。
每個代理都需要一個名稱和描述(以及您使用的代理類型特有的其他屬性)。
代理描述在編排過程中起著至關重要的作用。
它應該詳細且全面,因為編排器依賴于此描述,以及當前用戶輸入和所有代理的對話歷史,來確定每個請求的最合適路由。
雖然框架的靈活性是一個優(yōu)勢,但重要的是要注意代理之間可能存在的潛在重疊,這可能會導致路由錯誤。為了幫助您分析和防止此類重疊,我們建議您深入閱讀我們的代理重疊分析部分。
多代理編排器(Multi-Agent Orchestrator)框架的關鍵優(yōu)勢之一在于其代理的標準實現(xiàn)。這種標準化為不同環(huán)境帶來了顯著的靈活性和一致性。無論您是與不同的云服務提供商合作,使用各種大型語言模型(LLM),還是混合使用基于云和本地的解決方案,代理都提供了一個統(tǒng)一的接口來執(zhí)行任務。
這意味著您可以無縫地在例如Amazon Lex Bot Agent和Amazon Bedrock Agent之間切換,或使用工具進行過渡,也可以從云托管的大型語言模型切換到本地運行的大型語言模型,同時保持相同的代碼結構。
此外,如果您的應用程序需要按順序或并行地使用Bedrock LLM Agent和/或Amazon Lex Bot Agent的不同模型,您也可以輕松實現(xiàn),因為代碼實現(xiàn)已經就緒。這種標準化方法意味著您無需為每個模型編寫新代碼;相反,您可以直接使用現(xiàn)有的代理。
為了利用這種靈活性,您只需安裝框架并導入所需的代理。然后,無論底層技術如何,您都可以直接使用processRequest方法調用它們。這種標準化不僅簡化了開發(fā)和維護工作,還促進了在不同平臺和技術之間輕松進行實驗和優(yōu)化,而無需進行大量的代碼重構。
這種標準化使您能夠在保持核心應用程序代碼完整性的同時,嘗試各種代理類型和配置。
編排器由以下主要組件構成:
編排器的每個組件都可以使用自定義實現(xiàn)進行自定義或更換,從而提供了無與倫比的靈活性,并使該框架能夠適應各種場景和特定要求。
快速入門
為了幫助您快速啟動多代理編排器(Multi-Agent Orchestrator)框架,我們將引導您逐步完成設置和運行您的第一個多代理對話的全過程。
??在繼續(xù)之前,請確保您的開發(fā)環(huán)境中已安裝Node.js和npm(用于TypeScript)或Python(用于Python)。
1.創(chuàng)建一個新項目:

2.使用您的AWS賬戶進行身份驗證
本快速入門將展示如何使用Amazon Bedrock進行分類和代理響應。
要按照以下步驟使用您的AWS賬戶進行身份驗證:
a. 如果您尚未安裝AWS CLI,請從AWS CLI官方頁面下載并安裝。
b. 使用您的憑證配置AWS CLI。有關如何設置AWS CLI的詳細指南,請參閱AWS CLI配置快速入門指南。
c. 配置完AWS CLI后,通過運行以下命令驗證您的身份驗證:
終端窗口

如果成功,此命令將返回您的AWS賬戶ID、用戶ID和ARN。
默認情況下,該框架配置如下:
分類器:
使用帶有anthropic.claude-3-5-sonnet-20240620-v1:0的Bedrock Classifier實現(xiàn)
代理:使用帶有anthropic.claude-3-haiku-20240307-v1:0的Bedrock LLM Agent
重要提示
這些只是默認設置,您可以根據需求或偏好輕松更改。
您具有以下靈活性:
請確保您已通過AWS控制臺請求了您打算使用的模型的訪問權限。
要自定義模型選擇:
1.在您的項目中安裝多代理編排器框架:

2.為您的快速啟動代碼創(chuàng)建一個新文件:
創(chuàng)建一個名為quickstart.py的文件。
3.創(chuàng)建編排器:

4.添加代理:

5.發(fā)送查詢:

現(xiàn)在,讓我們運行快速啟動腳本:

編排器
Multi-Agent Orchestrator是框架的核心組件,負責管理代理、路由請求和處理對話。本頁提供了如何初始化Orchestrator的概述,并詳細列出了所有可用的配置選項。
要創(chuàng)建一個新的Orchestrator實例,您可以使用MultiAgentOrchestrator類:

options參數(shù)是可選的,允許您自定義Orchestrator行為的各個方面。
Orchestrator在初始化時接受一個OrchestratorConfig對象。所有選項都是可選的,如果未指定,將使用默認值。以下是可用選項的完整列表:
storage:指定聊天歷史的存儲機制。默認值為InMemoryChatStorage。config:一個OrchestratorConfig實例,包含各種配置標志和值。logger:自定義日志記錄器實例。如果未提供,將使用默認日志記錄器。classifier:自定義分類器實例。如果未提供,將使用BedrockClassifier。default_agent:當分類器無法確定最合適的代理時使用的默認代理。以下示例展示了如何使用所有可用選項初始化Orchestrator:

請記住,所有這些選項都是可選的。如果不指定某個選項,Orchestrator將使用其默認值。
默認配置定義如下:
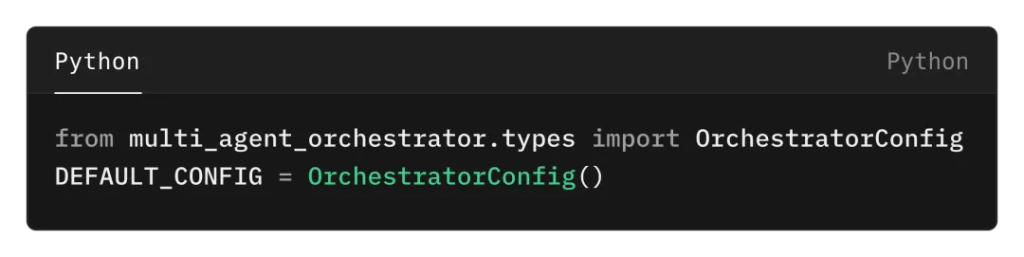
在兩種實現(xiàn)中,DEFAULT_CONFIG都是具有默認值的OrchestratorConfig實例。
MultiAgentOrchestrator?提供了多個關鍵功能來管理代理、處理請求以及配置協(xié)調器。以下是每個功能的詳細介紹,解釋了其作用以及您可能會使用它的原因:

讓我們分解每個功能:
1. addAgent (TypeScript) / add_agent (Python)
2. getDefaultAgent
3. setDefaultAgent
4. setClassifier
5. getAllAgents
6. routeRequest
這些功能在配置和操作 Multi-Agent Orchestrator 中發(fā)揮著至關重要的作用。通過有效地使用它們,您可以創(chuàng)建一個靈活且強大的系統(tǒng),能夠跨多個域處理廣泛的用戶請求。
這些功能允許您配置協(xié)調器、管理代理以及處理用戶請求。
功能示例
以下是如何使用每個功能的實際示例:

當用戶向多代理協(xié)調器發(fā)送請求時,系統(tǒng)會嘗試對意圖進行分類并選擇一個合適的代理來處理該請求。然而,也存在未選擇任何特定代理的情況。
未選擇代理時
如果分類器無法確定哪個代理應該處理請求,可能會導致沒有代理被選中。在這種情況下,協(xié)調器的行為取決于USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED配置選項:
默認代理
默認代理是一個配置為通用型的BedrockLLMAgent,能夠處理廣泛的主題。它在以下情況下使用:
您可以使用set_default_agent方法自定義默認代理或完全替換它:

自定義NO_SELECTED_AGENT_MESSAGE
您可以通過在協(xié)調器配置中設置NO_SELECTED_AGENT_MESSAGE來自定義在未選擇代理時返回的消息(且USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED為False):

最佳實踐
1. 默認代理的使用:當您希望確保所有用戶查詢都能收到回復(即使不是來自專業(yè)代理)時,請使用默認代理。
2. 提示澄清:當您希望鼓勵用戶提供更具體或清晰的請求時,將USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED設置為False并自定義NO_SELECTED_AGENT_MESSAGE。
3. 平衡具體性和覆蓋范圍:仔細考慮您的用例。使用默認代理可以提供更廣泛的覆蓋范圍,但可能會犧牲具體性。提示澄清可能會導致更準確的代理選擇,但需要額外的用戶交互。
4. 監(jiān)控和迭代:定期審查未選擇代理的情況。這有助于您識別代理覆蓋范圍的空白或改進分類過程。
通過了解和自定義這些行為,您可以調整您的多代理協(xié)調器,以為您的特定用例提供最佳的用戶體驗。
存儲選項允許您指定自定義存儲機制。默認情況下,它使用內存存儲(InMemoryChatStorage),但您可以實現(xiàn)自己的存儲解決方案或使用內置選項,如DynamoDB存儲。有關更多信息,請參閱“存儲”部分。
日志記錄器選項允許您提供一個自定義日志記錄器。如果未指定,將使用默認日志記錄器。要了解如何實現(xiàn)自定義日志記錄器,請查閱“日志記錄”部分。
分類器選項允許您使用自定義分類器進行意圖分類。如果未提供,將默認使用BedrockClassifier。有關實現(xiàn)自定義分類器的詳細信息,請參閱“自定義分類器”文檔。
通過自定義這些選項,您可以調整Orchestrator的行為,以滿足您的特定用例和需求。
分類器
分類器是多代理協(xié)調器(Multi-Agent Orchestrator)的關鍵組件,負責分析用戶輸入并識別最合適的代理。協(xié)調器支持多種分類器實現(xiàn),其中Bedrock分類器和Anthropic分類器是主要選項。
無論使用哪種分類器,一般流程都保持不變:
1. 協(xié)調器收集用戶輸入。
2. 分類器執(zhí)行輸入分析,考慮以下因素:
3.確定最合適的代理。
默認情況下,如果沒有選擇代理,協(xié)調器可以配置為:
可以使用協(xié)調器中的USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED和NO_SELECTED_AGENT_MESSAGE 配置選項來自定義此行為。
有關這些選項和其他協(xié)調器配置的詳細說明,請參閱協(xié)調器概述頁面。
分類器的決策過程對于有效地將用戶查詢路由到最合適的代理至關重要,從而確保無縫且高效的多代理交互體驗。
當您通過初始化MultiAgentOrchestrator創(chuàng)建一個新的協(xié)調器時,將初始化默認的Bedrock分類器。

要使用Anthropic分類器,可以將其作為選項傳遞:

這樣,您就可以根據您的需求選擇合適的分類器來初始化協(xié)調器了。
您可以通過擴展抽象Classifier類來提供自己的自定義分類器實現(xiàn)。有關如何執(zhí)行此操作的詳細信息,請參閱“自定義分類器”部分。
您可以直接使用classify方法來測試任何分類器:

這允許您:
在決定使用不同的分類器時,請考慮:
1. API訪問權限:您可以訪問和偏好的服務。
2. 模型性能:使用您的特定用例測試分類器,以確定哪個更適合您的需求。
3.成本:比較您預期使用的定價結構。
通過徹底測試和調試您選擇的分類器,您可以確保在多代理協(xié)調器中進行準確的意圖分類和高效的查詢路由。
帶上下文管理
測試帶有完整對話歷史記錄處理的分類器:

此方法:
不帶上下文
測試沒有對話歷史的原始分類:

最適合:
智能體
在多智能體編排器(Multi-Agent Orchestrator)中,智能體(Agent)是一個基本構建模塊,旨在處理用戶請求并生成響應。智能體抽象類(Agent Abstract Class)是所有具體智能體實現(xiàn)的基礎,提供了通用的結構和接口。
智能體選擇過程
多智能體編排器使用一個分類器(Classifier),通常是一個大語言模型(LLM),來為每個用戶請求選擇最合適的智能體。
這一過程的核心是智能體描述。這些描述至關重要,應盡可能詳細和全面。一個精心設計的智能體描述應:
這些描述越詳細和精確,分類器就能越準確地將請求路由到正確的智能體。這在具有多個專用智能體的復雜系統(tǒng)中尤為重要。
有關智能體選擇過程的更詳細說明,請參閱我們文檔中的“工作原理”部分。
為了優(yōu)化智能體選擇:
通過優(yōu)先考慮詳細的智能體描述并微調選擇過程,您可以顯著提高多智能體編排器實現(xiàn)的效率和準確性。
智能體類(Agent class)是一個抽象基類,定義了系統(tǒng)中所有智能體必須具備的基本屬性和方法。它設計靈活,允許從簡單的API調用者到復雜的基于LLM的對話智能體等多種實現(xiàn)。
關鍵屬性
process_request任何智能體的核心功能都封裝在process_request方法中。該方法必須由所有具體智能體類實現(xiàn):

該方法返回單個響應的ConversationMessage或流式響應的AsyncIterable。
示例用法:

智能體選項
在創(chuàng)建新智能體時,您可以使用AgentOptions類指定各種選項:

直接使用智能體
當您有單一智能體用例時,可以繞過編排器直接調用智能體。這種方法利用了多智能體編排器框架的強大功能,同時專注于單一智能體場景:

這種方法適用于不需要編排但希望利用多智能體編排器框架強大功能的單一智能體場景。
這些選項允許您自定義智能體行為的各個方面及其配置。
對話存儲
多智能體編排系統(tǒng)(Multi-Agent Orchestrator System)提供了靈活的存儲選項,用于維護對話歷史記錄。這使得系統(tǒng)能夠在多次交互中保留上下文,并使智能體能夠提供更加連貫且與上下文相關的響應。
1.內存存儲(In-Memory Storage):
2.DynamoDB存儲:
3.SQL存儲:
4.自定義存儲解決方案:
選擇合適的存儲選項
通過利用這些存儲選項,您可以確保多智能體編排系統(tǒng)在各種用例和部署場景中保持必要的上下文,從而實現(xiàn)連貫且有效的對話。
檢索器(Retriever)是一種組件或機制,用于從大規(guī)模數(shù)據集或數(shù)據庫中提取與查詢相關的信息。這一過程對于提升大語言模型(LLMs)的性能和準確性至關重要,尤其是在需要訪問和利用外部知識源的任務中。
1.提升上下文與相關性:
檢索器能夠為大語言模型提供相關的上下文或信息,這些信息可能未包含在其訓練數(shù)據中,或者過于具體而無法僅從模型的內部知識生成。
2.記憶增強:
檢索器充當大語言模型的擴展記憶,使其能夠訪問最新信息或特定主題的詳細數(shù)據,從而提高生成響應的相關性和準確性。
3.提高效率:
檢索器允許模型按需提取必要的信息,而不是在龐大且不斷增長的數(shù)據集上進行訓練,從而使系統(tǒng)更加高效。
通過檢索器的使用,大語言模型能夠更智能地
整合外部知識,生成更準確、更符合上下文的響應,同時優(yōu)化資源利用。
本文章轉載微信公眾號@Paper易論







