
使用這些基本 REST API 最佳實踐構建出色的 API
向量定義:向量是一組有序的數字(標量),用于在多維空間中表示數據點或特征。這些數字構成了一個列表或數組,其中每個元素對應于一個特定的維度。
向量正逐步嶄露頭角,有望成為AI時代的數據交換標準,類似于互聯網時代廣泛使用的JSON(JavaScript Object Notation)。
向量是Encoder-Decoder的橋梁:將現實問題轉化為數學問題,通過求解數學問題來得到現實世界的解決方案。

Encoder (編碼器):“將現實問題轉化為數學問題”

Decoder (解碼器):“求解數學問題,并轉化為現實世界的解決方案”

向量轉換過程:非結構化數據轉換成向量的過程稱為 Embedding(嵌入)。通過深度學習的訓練,可以將真實世界數字化后的離散特征提取出來,投影到數學空間上,成為一個數學意義上的向量,同時很神奇的保留著通過向量之間的距離表示語義相似度的能力。

Embedding 的過程:
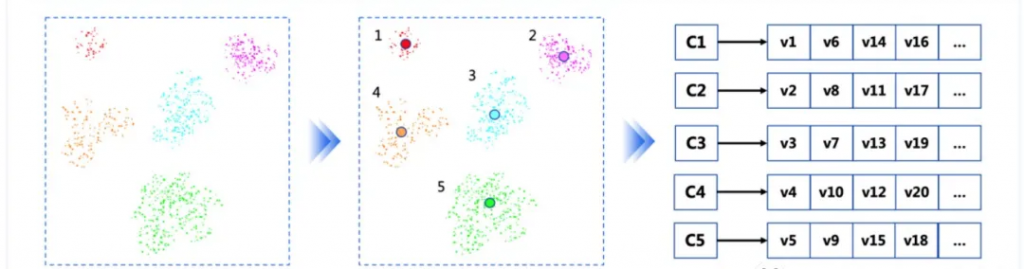
向量檢索:向量相關的工程技術里最核心的當然是向量檢索算法,即如何在海量向量里找到跟目標向量最相似的 K 個,又叫 topK。

向量數據庫:一個典型的基于向量數據庫的應用框圖可以表示如下:

基于向量數據庫的應用框圖
步驟一:生成向量嵌入
步驟二:存儲與索引
步驟三:查詢與相似性匹配
提示詞工程:大模型應用離不開提示詞工程。提示詞工程怎么做呢?主要就是為大模型整理一個資料庫,然后在訪問流程上,先從海量資料庫里找到最匹配的內容,拼接提示詞來增強回答,本質上就是一個搜索引擎。

LangChain+ Embedding+ 向量數據庫構建提示詞工程是指結合LangChain+(一個假設的或特定的NLP框架/工具)的文本處理能力和Embedding技術(將文本或其他數據轉換為向量的方法),以及向量數據庫的高效存儲和檢索能力,來構建和優化基于提示詞的AI系統。構建此類工程時可能涉及的關鍵步驟和組件如下:
文章轉自微信公眾號@架構師帶你玩轉AI