
墨西哥支付方式:是什么?
Source: SemiAnalysis Estimates
雖然 OpenAI 的計(jì)算資源更多,但他們主要把這些資源用來開發(fā) GPT-4 Turbo 和 GPT-4o 這種規(guī)模更小、過度訓(xùn)練且推理成本更低的模型,并且 OpenAI 也承認(rèn)前不久才開始訓(xùn)練下一代能力更強(qiáng)的模型。AI Timeline 的下一個(gè)里程碑將是訓(xùn)練出數(shù)萬億參數(shù)的多模態(tài) Transformer,讓模型具備處理大量視頻、圖像、音頻和文本數(shù)據(jù)的能力。目前還沒有人能完成這項(xiàng)任務(wù),但各大公司正在積極擴(kuò)張。OpenAI/Microsoft、xAI 和 Meta 等大型 Al Labs 正在展開 10 萬 GPU 集群建設(shè)的爭奪賽,這些單個(gè)訓(xùn)練集群僅服務(wù)器資本支出就超過 40 億美元,還受限于數(shù)據(jù)中心容量和電力供應(yīng)能力。一個(gè) 10 萬 GPU 的集群需要超過 150MW 的數(shù)據(jù)中心容量,一年的消耗就是 1.59TWh(15.9 億度電),約等于 15 萬個(gè)家庭一年的用電量。按$0.078/Kwh 的單價(jià)來計(jì)算,一個(gè) 10 萬卡集群每年光在電力這一項(xiàng)上的支出就高達(dá) 1.239 億美元。?

Source: SemiAnalysis, US EIA
以下數(shù)據(jù)可以更直觀地展示一個(gè) 10 萬 GPU 集群的算力:
??OpenAI 訓(xùn)練 GPT-4 時(shí)用了大概 2 萬張 A100,BF16 浮點(diǎn)運(yùn)算量大概是?2.5×102??FLOP(2150 萬 ExaFLOP),訓(xùn)練時(shí)間是 90-100 天,峰值吞吐量只有 6.28 BF16 ExaFLOP/秒。
? 一個(gè) 10 萬 H100 集群的峰值吞吐量會(huì)達(dá)到 198 FP8 ExaFLOP/秒 或 99 FP16 ExaFLOP/秒,從峰值理論上來說,這個(gè)數(shù)值是 2 萬張 A100 GPU 集群訓(xùn)練時(shí)最大 FLOPS 的 31.5 倍。
*?拾象注:Exa 表示 101??,所以 1 ExaFLOP = 101??FLOPs

Source: Nvidia, SemiAnalysis
AI labs 用 H100 訓(xùn)練萬億參數(shù)的模型時(shí),能夠?qū)崿F(xiàn)高達(dá) 35%的 FP8 MFU 和 40%的 FP16 MFU。MFU(Model Full Utilization,模型浮點(diǎn)運(yùn)算利用率)是在考慮到成本和各種限制因素后,衡量峰值潛力 FLOPS 的有效吞吐量和利用率的標(biāo)準(zhǔn),這些因素包括功率限制、通信不穩(wěn)定、數(shù)據(jù)丟失后重新計(jì)算、拖慢進(jìn)度的任務(wù)和低效核心程序等等。一個(gè) 10 萬張 H100 的集群用 FP8 做 GPT-4 的訓(xùn)練,只需要四天。如果一個(gè) 10 萬 H100 集群持續(xù)運(yùn)行 100 天,可以實(shí)現(xiàn)大概 6×102?(6 億 ExaFLOP)的有效 FP8 模型 FLOP。但如果硬件可靠性較差,就會(huì)顯著降低 MFU。
為了支持服務(wù)器、存儲(chǔ)設(shè)備、網(wǎng)絡(luò)設(shè)備這些核心 IT 設(shè)備,一個(gè) 10 萬 H100 集群所需的功耗大約是 150MW(兆瓦)。雖然單個(gè) GPU 的功率只有 700W,但每個(gè) H100 服務(wù)器內(nèi)還有 CPU、NIC(網(wǎng)絡(luò)接口卡)、PSU(電源供應(yīng)單元)等等部件,所以每個(gè) GPU 還要額外消耗大概 575W。除了 H100,集群內(nèi)還需要一系列存儲(chǔ)服務(wù)器、網(wǎng)絡(luò)交換機(jī)、CPU 節(jié)點(diǎn)、光模塊等等,這些設(shè)備會(huì)額外再占用大概 10% 的 IT 功耗。作為對(duì)比,美國最大的國家實(shí)驗(yàn)室超級(jí)計(jì)算機(jī) El Capitan 只需要 30MW 的關(guān)鍵 IT 電力,大概只有一個(gè) 10 萬 H100 集群功耗的 1/5。

超級(jí)計(jì)算機(jī) El Capitan,
部署在美國勞倫斯利弗莫爾國家實(shí)驗(yàn)室(LLNL)
電力方面一個(gè)很大的問題是,至今還沒有任何單個(gè)數(shù)據(jù)中心大樓能夠承載 150MW 的電力需求,所以 10 萬 GPU 集群一般都是一個(gè)園區(qū),而不是單一建筑。由于沒有合適的設(shè)施,xAI 甚至要把田納西州 Memphis 的一家廢棄舊工廠改造成數(shù)據(jù)中心來解決電力供應(yīng)問題。


xAI 在田納西州 Memphis 建設(shè)中的數(shù)據(jù)中心,
世界上最大的超級(jí)計(jì)算機(jī)園區(qū)
Source: xAI
因?yàn)檎麄€(gè)園區(qū)內(nèi)的服務(wù)器需要通過光纖收發(fā)器來聯(lián)網(wǎng),而傳輸?shù)木嚯x越長,光纖收發(fā)器成本就越高,成本就會(huì)在無形中增加:
? “多模”SR(短距離)和 AOC(有源光纜)光模塊傳輸距離約為 50 米;
? “單模”DR 和 FR 收發(fā)器傳輸信號(hào)距離在 500 米 – 2000 米 之間,可靠性較高,但成本可能是“多模”SR(短距離)和 AOC(有源光纜)光模塊的 2.5 倍;
??園區(qū)級(jí)別的 800G 相干光收發(fā)器的傳輸距離超過 2000 米,但價(jià)格也是普通光模塊的 10 倍以上,一般在 $1800。

多模光纖(Multimode Fiber)和單模光纖(Single Mode Fiber)在結(jié)構(gòu)和光信號(hào)傳播方式上的區(qū)別
小型的 H100 集群通常會(huì)用平面或者近平面這樣交換層數(shù)比較少的網(wǎng)絡(luò)設(shè)計(jì),只需要通過一兩層交換機(jī),用多模收發(fā)器(multi-mode transceiver)把所有 GPU 以 400G 的速率進(jìn)行互聯(lián)。但是大型 GPU 集群必須增加更多的交換機(jī),光纖成本會(huì)非常高,網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)會(huì)因?yàn)楣?yīng)商技術(shù)、workload 以及 capex 有很大不同。
我們可以把每個(gè)數(shù)據(jù)中心大樓都看作一個(gè)計(jì)算島(compute island),島內(nèi)會(huì)包含一個(gè)或多個(gè)計(jì)算艙(computer pod);不同計(jì)算島之間用遠(yuǎn)距離光收發(fā)器來實(shí)現(xiàn)互連,計(jì)算艙之間則通過廉價(jià)的銅纜或多模光模塊來連接。下圖中有 4 個(gè)計(jì)算島,這些島內(nèi)部有高帶寬連接,但島間的帶寬比較低。在一個(gè)數(shù)據(jù)中心內(nèi)提供 155MW 的電力是非常困難的,但 Microsoft、Meta、Google、Amazon、ByteDance、xAI、Oracle 等等超過 15 家大廠都在擴(kuò)建數(shù)據(jù)中心,這些中心未來很可能有足夠的空間容納 AI 服務(wù)器和網(wǎng)絡(luò)設(shè)備。

Source: SemiAnalysis
不同的客戶會(huì)基于各種原因選擇不同的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu),包括數(shù)據(jù)傳輸 infra、成本、可維護(hù)性、電力、電流以及任務(wù)量等等。有些客戶選擇了 Broadcom Tomahawk 5,有些客戶仍然堅(jiān)持用 InfiniBand,還有一些選擇了 NVIDIA 的 Spectrum-X,下文中我們會(huì)深入分析他們做出這種選擇的原因。
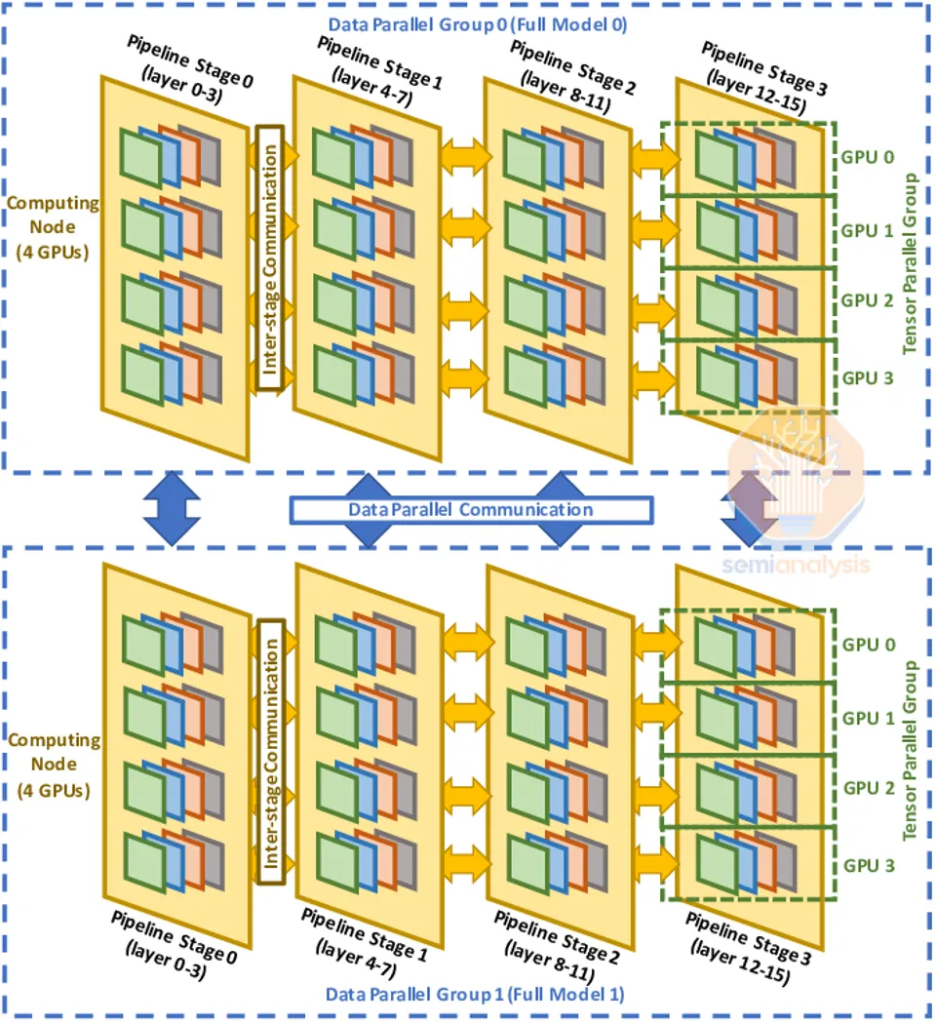
在深入探討網(wǎng)絡(luò)設(shè)計(jì)、拓?fù)浣Y(jié)構(gòu)、可靠性問題以及檢查點(diǎn)(checkpointing)的策略之前,我們先簡要回顧一下萬億參數(shù)訓(xùn)練中使用的三種并行方式:數(shù)據(jù)并行(Data Parallelism)、張量并行(Tensor Parallelism)和流水線并行(Pipeline Parallelism)。
數(shù)據(jù)并行是最簡單的并行形式,其中每個(gè) GPU 都有模型權(quán)重的完整副本,并接收數(shù)據(jù)的不同子集。這種類型的并行通信需求最低,因?yàn)橹恍枰?GPU 間傳遞梯度數(shù)據(jù)。但數(shù)據(jù)并行需要每個(gè) GPU 都有足夠的內(nèi)存來存儲(chǔ)整個(gè)模型的權(quán)重、激活值、優(yōu)化器狀態(tài)(optimizerstate)。對(duì)于像 GPT-4 這樣的 1.8 萬億參數(shù)模型,僅僅是模型權(quán)重和優(yōu)化器狀態(tài)在訓(xùn)練時(shí)就需要高達(dá) 10.8TB 的內(nèi)存。

Source: ColossalAI
為了克服這些內(nèi)存限制,可以使用張量并行技術(shù)。在張量并行中,每一層的工作和模型權(quán)重分布在多個(gè) GPU 上,一般會(huì)覆蓋全部隱藏層。中間的工作會(huì)通過在自注意力機(jī)制(self-attention)、前饋網(wǎng)絡(luò)(feed forward network)和層歸一化(layer normalizations)等計(jì)算中多次跨設(shè)備的歸約(all-reduction)來交換,這就需要高帶寬和非常低的延遲。在張量并行的模式下,所有參與的 GPU 都會(huì)協(xié)同工作,共同構(gòu)成一個(gè)大型 GPU。這種方式可以將整個(gè)計(jì)算任務(wù)分解為多個(gè)部分(即張量并行等級(jí)),從而減少每個(gè) GPU 需要處理的數(shù)據(jù)量和消耗的內(nèi)存。例如,現(xiàn)在通常在 NVLink 上使用 8 個(gè)張量并行等級(jí),相當(dāng)于每個(gè) GPU 使用的內(nèi)存減少到原來的 1/8。

Source: Accelerating Pytorch Training
單個(gè) GPU 內(nèi)存有限的問題還可以用流水線并行解決。在流水線并行中,每個(gè) GPU 只負(fù)責(zé)模型前向計(jì)算的一環(huán),并僅計(jì)算這一環(huán)中的層,然后再把中間結(jié)果傳遞給下一個(gè) GPU。因?yàn)榱魉€并行等級(jí)的數(shù)量減少了,所需的內(nèi)存量也減少了。流水線并行對(duì)通信量有較大的需求,但相比張量并行還是要小。

Source: Colossal AI
為了最大化 MFU,公司通常會(huì)結(jié)合以上三種并行形式,形成 3D 并行,分布大概是:
? H100 服務(wù)器內(nèi)的多個(gè) GPU 間用張量并行;
? 島內(nèi)的節(jié)點(diǎn)間用流水線并行;
??島間用數(shù)據(jù)并行,因?yàn)閿?shù)據(jù)并行通信量最低,并且島間的網(wǎng)絡(luò)連接比較慢。
Source: Optimus-CC
全存儲(chǔ)數(shù)據(jù)并行(FSDP,F(xiàn)ully Sharded Data Parallel)技術(shù)通常會(huì)在小規(guī)模 GPU 集群上用來處理非常大型的模型,但在實(shí)際應(yīng)用中卻很少 work,本身也存在不兼容的問題。
AI 算力集群的網(wǎng)絡(luò)設(shè)計(jì)需要考慮數(shù)據(jù)并行的方案。如果每個(gè) GPU 都用 Fat-Tree 拓?fù)浣Y(jié)構(gòu),并以最大帶寬來連接,成本會(huì)非常高,因?yàn)橹虚g涉及到 4 層交換,每增加一層網(wǎng)絡(luò),所需的光器件成本也會(huì)大幅上升。因此,沒有人會(huì)為大型 GPU 集群部署完整的 Fat-Tree 架構(gòu)。相反,他們會(huì)創(chuàng)建有完整 Fat-Tree 架構(gòu)的計(jì)算島,并在這些島間用較低帶寬互聯(lián)。實(shí)現(xiàn)這一點(diǎn)有很多方法,但大多數(shù)公司會(huì)對(duì)網(wǎng)絡(luò)頂層進(jìn)行帶寬的過度訂閱(oversubscribe),即在網(wǎng)絡(luò)的頂層,分配給島嶼之間連接的帶寬會(huì)超過實(shí)際可用的帶寬。

Fat Tree(k=4)架構(gòu)示意
下圖是 Meta 上一代的 GPU 集群架構(gòu),最多可以達(dá)到 3.2 萬卡。總共有 8 個(gè)計(jì)算島,島間有全速的 Fat-Tree 帶寬,然后在頂層有另一層交換,收斂比(即 over subscription,過度訂閱比率)為 7:1,也就是說島間的網(wǎng)絡(luò)連接速度比島內(nèi)的網(wǎng)絡(luò)連接慢 7 倍。但在實(shí)際操作中這種降速對(duì)性能影響并不大,因?yàn)橥ǔ2皇撬械姆?wù)器都會(huì)用最大帶寬來通信,可以在保證局部高性能的同時(shí),降低整體網(wǎng)絡(luò)架構(gòu)的復(fù)雜性和成本。

Source: Meta
GPU 部署有多種網(wǎng)絡(luò):前端網(wǎng)絡(luò)、后端網(wǎng)絡(luò)和擴(kuò)展網(wǎng)絡(luò)(NVLink)。某些情況可能會(huì)在每個(gè)網(wǎng)絡(luò)上用到不同的并行方案,NVLink 網(wǎng)絡(luò)的速度可能是唯一能夠滿足張量并行需求的網(wǎng)絡(luò)。后端網(wǎng)絡(luò)通常可以輕松處理大多數(shù)其他類型的并行,但如果存在過度訂閱的情況,通常只能用于數(shù)據(jù)并行。還有些人甚至沒有在頂層帶寬過度訂閱的集群架構(gòu),他們反而是把流量從后端網(wǎng)絡(luò)轉(zhuǎn)移到前端網(wǎng)絡(luò),來避免帶寬的瓶頸。
一家大型科技公司在多個(gè) InfiniBand 計(jì)算島之間用了前端以太網(wǎng)進(jìn)行模型訓(xùn)練,這是因?yàn)榍岸司W(wǎng)絡(luò)的成本要低得多,還可以利用園區(qū)內(nèi)現(xiàn)有的網(wǎng)絡(luò)在大樓和區(qū)域路由間通信。

Source: SemiAnalysis
不過由于采用了MoE等稀疏技術(shù),模型大小增長得更快,前端網(wǎng)絡(luò)需要處理的通信量也在增加,前端網(wǎng)絡(luò)的帶寬最終可能跟后端網(wǎng)絡(luò)的帶寬差不了多少,所以必須仔細(xì)權(quán)衡優(yōu)化,否則最終可能兩種方案的網(wǎng)絡(luò)成本趨同。
Google 的做法是專門設(shè)計(jì)了一種叫做 ICI(Inter Chiplet Interconnect)的前端網(wǎng)絡(luò)架構(gòu),用來支持大規(guī)模 TPU Pod 訓(xùn)練。這種架構(gòu)最多只能支持 8960 個(gè)芯片,并且在 64 個(gè) TPU 水冷機(jī)架之間要用昂貴的 800G 光器件和光路交換機(jī)連接。因?yàn)檫@種在擴(kuò)展規(guī)模上的局限性,Google 必須通過增強(qiáng) TPU 的前端網(wǎng)絡(luò)來彌補(bǔ),讓它的表現(xiàn)比大多數(shù) GPU 前端網(wǎng)絡(luò)都更強(qiáng)大。

Source: Google at MLSys24
如果要用前端網(wǎng)絡(luò)來進(jìn)行分布式訓(xùn)練,那就必須在不同的島間進(jìn)行全局 all-reduce,具體操作包括:
1. 本地 reduce-scatter:首先,每個(gè)艙或島內(nèi)部用 InfiniBand 或 ICI 網(wǎng)絡(luò)進(jìn)行規(guī)約-分散(reduce-scatter),這樣每個(gè) GPU/TPU 都會(huì)擁有梯度的一部分總和。
2. 跨艙 all-reduce:用前端以太網(wǎng)在不同艙之間傳輸和匯總數(shù)據(jù)。
3. 艙級(jí) all-gather:在每個(gè)艙內(nèi)部再次收集和整合數(shù)據(jù),確保每個(gè)節(jié)點(diǎn)都獲得完整的數(shù)據(jù)。
前端網(wǎng)絡(luò)還要負(fù)責(zé)加載數(shù)據(jù)。隨著多模態(tài)圖像和視頻訓(xùn)練數(shù)據(jù)的增加,前端網(wǎng)絡(luò)需求未來也會(huì)有指數(shù)級(jí)增長。在這種情況下,加載大型視頻文件和執(zhí)行 all-reduce 操作會(huì)爭奪前端網(wǎng)絡(luò)帶寬,因此必須在二者間做合理分配。如果存儲(chǔ)網(wǎng)絡(luò)流量不規(guī)則,還會(huì)增加滯后問題,導(dǎo)致整個(gè) all-reduce 操作變慢,沒辦法做可預(yù)測(cè)的建模。
另一種替代方案是用 4 個(gè)層級(jí)的 InfiniBand 網(wǎng)絡(luò),收斂比是 7:1,這類網(wǎng)絡(luò)有 4 個(gè)艙,每個(gè)艙內(nèi)有 24576 個(gè) H100,采用 3 層級(jí)的非阻塞網(wǎng)絡(luò)系統(tǒng)。相比前端網(wǎng)絡(luò),InfiniBand 網(wǎng)絡(luò)更容易擴(kuò)展帶寬,靈活性會(huì)更高,只需在 A 大樓和 B 大樓的交換機(jī)之間增加更多的光纖收發(fā)器即可,這比給集群中每個(gè)機(jī)箱的前端網(wǎng)絡(luò)做 NIC 升級(jí)(例如從 100G 升級(jí)到 200G 等)要容易得多。

Source: SemiAnalysis
這種網(wǎng)絡(luò)相對(duì)來說也更加穩(wěn)定,因?yàn)榍岸司W(wǎng)絡(luò)可以專門負(fù)責(zé)加載數(shù)據(jù)和檢查點(diǎn),后端網(wǎng)絡(luò)則可以專注 GPU 到 GPU 的通信,這樣也更好解決落后節(jié)點(diǎn)問題。但它最大的缺點(diǎn)就是需要各種額外的交換機(jī)和光模塊,所以價(jià)格極貴。
有些集群為了讓網(wǎng)絡(luò)更好維護(hù)和管理,同時(shí)盡量用小于 3 米的銅纜和小于 50 米的多模光纖來增加穩(wěn)定性,會(huì)選擇放棄 NVIDIA 推薦的 Rail Optimized 設(shè)計(jì),采用機(jī)柜中部(Middle of Rack)設(shè)計(jì)。

Source: Huawei
根據(jù)交換機(jī)在數(shù)據(jù)中心機(jī)房機(jī)柜上的部署位置,一般分為機(jī)柜頂部(Top of Rack), 機(jī)柜中部(Middle of Rack)或機(jī)柜底部(Bottom of Rack)。其中的機(jī)柜中部(Middle of Rack)是指在數(shù)據(jù)中心內(nèi)將設(shè)備安裝在服務(wù)器機(jī)柜的中間位置。這種安裝方式可以優(yōu)化空氣流通和散熱效率,平衡機(jī)柜重量,方便維護(hù),并改善電纜管理,經(jīng)常用在關(guān)鍵設(shè)備的安裝,比如交換機(jī)、路由器和存儲(chǔ)設(shè)備,來提高數(shù)據(jù)中心的整體效率和可靠性。

Source: Nvidia
Rail Optimized 技術(shù)可以讓每個(gè) H100 連接到 8 個(gè)不同的 leaf switch,而不是全部連接到同一個(gè)機(jī)架中部的交換機(jī),這樣每個(gè) GPU 只需要通過 1 個(gè)交換機(jī)跳轉(zhuǎn)就能和更遠(yuǎn)距離的 GPU 通信。All-to-All 集體通信在 MoE 模型里用得非常頻繁,交換機(jī)的跳數(shù)少了,通信路徑的長度更短,就能更好提高現(xiàn)實(shí)世界中 All-to-All 集體通信的性能。

Source: Crusoe
Rail Optimized 的缺點(diǎn)在于必須連接到不同的 Leaf Switch,這些交換機(jī)的距離不一,每次連接都要跨越不同的距離,所以必須用更貴的光纖來連接。但在 Middle of Rack 的情況下,交換機(jī)可以放在同一個(gè)機(jī)柜里,可以用更短距離的連接方式,比如直連電纜(DAC)和有源電纜(AEC),這些電纜一般都更便宜。另外交換機(jī)與 Spine Switch 之間的距離超過 50 米時(shí),就必須用單模光纖收發(fā)器,因?yàn)樗苤С指h(yuǎn)的距離。
如果使用了 Rail Optimized 之外的設(shè)計(jì),就可以用廉價(jià)的 DAC 替換 98304 個(gè)光纖收發(fā)器,來連接 GPU 和 Leaf Switch,也就是說整個(gè)網(wǎng)絡(luò)中會(huì)有 25-33% 的連接是銅纜,這樣可以顯著降低成本。如下面的機(jī)柜圖所示,在 Rail Optimized 中,Leaf Switch 會(huì)在機(jī)柜的中間位置,這樣每個(gè) GPU 都可以用 DAC 銅纜直接連接到 Leaf Switch。

Non-rail optimized middle of rack
Source: SemiAnalysis
相比光纖來說,DAC 銅纜散熱更好,省電又便宜,可靠性也更高,所以出現(xiàn)網(wǎng)絡(luò)連接中斷(flapping)和故障的幾率就更低,而這些都是光纖高速互連運(yùn)行中的大問題。比如說 Quantum-2 IB 脊交換機(jī)如果用 DAC 銅纜的話功耗是 747W,但用多模光纖收發(fā)器時(shí)功耗會(huì)飆到 1500W。
Rail optimized end of row
Source: SemiAnalysis
另外,對(duì)于數(shù)據(jù)中心的技術(shù)人員來說,Rail Optimized 設(shè)計(jì)的初始布線會(huì)非常耗時(shí),因?yàn)槊總€(gè)鏈路兩端的距離有 50 米,而且還不在同一個(gè)機(jī)架上。相比之下,Middle of Rack 的 Leaf Switch 與所有 GPU 都在同一個(gè)機(jī)架上,甚至還可以在集成工廠環(huán)境中測(cè)試計(jì)算節(jié)點(diǎn)到 Leaf Switch 的鏈路,方便更好地提前發(fā)現(xiàn)和解決問題,減少現(xiàn)場部署時(shí)的風(fēng)險(xiǎn)。

Rail-Optimzed Network 的 End of Row 水冷散熱
Source: SemiAnalysis
目前模型訓(xùn)練都需要多個(gè)計(jì)算單元同時(shí)工作,系統(tǒng)中的任何一個(gè)故障都可能影響整體訓(xùn)練過程,因此可靠性成為了大型集群最重要的運(yùn)維關(guān)注點(diǎn)之一。最常見的可靠性問題包括 GPU HBM ECC Error、GPU 驅(qū)動(dòng)程序卡住、光收發(fā)器故障、NIC 過熱,以及節(jié)點(diǎn)不斷報(bào)錯(cuò)和故障等等。
數(shù)據(jù)中心為了保持訓(xùn)練的連續(xù)性,盡量減少故障恢復(fù)的平均時(shí)間,必須在現(xiàn)場保留熱備節(jié)點(diǎn)(hot spare nodes)和冷備用組件(cold spare components)。當(dāng)發(fā)生故障時(shí),不能馬上就停止整個(gè)訓(xùn)練,而是要趕緊換上激活好的備用節(jié)點(diǎn)繼續(xù)訓(xùn)練。
一般來說重啟能解決大部分故障,但并不能解決全部問題。實(shí)操來說,技術(shù)人員經(jīng)常要親自去檢查和更換設(shè)備,如果比較幸運(yùn)的話,可能幾個(gè)小時(shí)能修復(fù)好,但很多情況下需要好幾天才能讓節(jié)點(diǎn)重新運(yùn)行。雖然從理論上講這些損壞的節(jié)點(diǎn)有可用的 FLOPS 能力,但實(shí)際上這些節(jié)點(diǎn)和備用的熱節(jié)點(diǎn)并沒有參與到模型訓(xùn)練中,也沒有為模型訓(xùn)練作出貢獻(xiàn)。
在訓(xùn)練過程中,模型需要頻繁地將模型的 checkpoint 保存到 CPU 內(nèi)存或 NAND SSD 中,避免發(fā)生 HBM ECC 等等錯(cuò)誤。一旦出現(xiàn)了報(bào)錯(cuò),就必須從較慢的存儲(chǔ)層重新加載模型權(quán)重和優(yōu)化器,然后再重啟訓(xùn)練。這個(gè)過程可以用到像 Oobleck 這樣的容錯(cuò)訓(xùn)練技術(shù),提供由用戶級(jí)別應(yīng)用程序驅(qū)動(dòng)的方法來應(yīng)對(duì) GPU 和網(wǎng)絡(luò)故障。
但是頻繁保存 checkpoint 和使用容錯(cuò)訓(xùn)練技術(shù)會(huì)影響系統(tǒng)的整體 MFU,因?yàn)檫^程中整個(gè)集群要不斷地暫停,不斷把當(dāng)前權(quán)重保存到持久內(nèi)存或 CPU 內(nèi)存中。一般來說每 100 次迭代只保存一次檢查點(diǎn),也就是說在發(fā)生故障時(shí)最多可能丟失 99 步的有效工作。在一個(gè) 10 萬集群中,如果每次迭代需要 2 秒鐘,那么在第 99 次迭代發(fā)生故障時(shí),就會(huì)損失多達(dá) 229 個(gè) GPU 天的工作量(一個(gè) GPU 天代表一個(gè) GPU 運(yùn)行 24 小時(shí))。
另一種故障恢復(fù)方法是讓備用節(jié)點(diǎn)通過后端網(wǎng)絡(luò)只用 RDMA(遠(yuǎn)程直接內(nèi)存訪問)從其他 GPU 復(fù)制權(quán)重,也是大多數(shù)大型 AI Labs 在用的故障修復(fù)方法。后端 GPU 網(wǎng)絡(luò)大概是 400Gbps,每個(gè) GPU 有 80GB 的 HBM 內(nèi)存,復(fù)制權(quán)重大約需要 1.6 秒。用這種方法的話,最多只會(huì)丟失 1 步操作(因?yàn)闀?huì)有更多的 GPU HBM 保存有最新的權(quán)重副本),所以最后只會(huì)丟失相當(dāng)于 2.3 個(gè) GPU 天的計(jì)算量,另外還要再加上從其他 GPU 的 HBM 內(nèi)存 RDMA 復(fù)制權(quán)重所需的 1.85 個(gè) GPU 天。
checkpoint 重啟本身可以說是又慢又麻煩,十分低效,但許多小型公司仍然在堅(jiān)持用它來處理所有故障,主要是因?yàn)樗僮髌饋砀唵巍H绻侵苯舆M(jìn)行內(nèi)存重建而不是 checkpoint 重啟,可以給整體集群運(yùn)行的 MFU 提高好幾個(gè)百分點(diǎn)。

Source: Meta
各種報(bào)錯(cuò)中有一個(gè)最常見的問題是InfiniBand/RoCE 鏈路故障。雖然每個(gè) NIC 到 Leaf Switch 鏈路的平均故障間隔時(shí)間是 5 年,但因?yàn)楣饽K數(shù)量非常多,對(duì)于一個(gè)全新的、正常工作的集群來說,第一次作業(yè)失敗僅僅在 26.28 分鐘內(nèi)就會(huì)發(fā)生。如果不通過內(nèi)存重構(gòu)進(jìn)行故障恢復(fù),那么在一個(gè) 10 萬 GPU 的集群中,因?yàn)楣馄骷收希貑⒁ǖ臅r(shí)間甚至可能會(huì)超過訓(xùn)練模型的時(shí)間。

Source: SemiAnalysis
目前每個(gè) GPU 都會(huì)通過 PCIe 交換機(jī)直接連到一個(gè) ConnectX-7 NIC,這種設(shè)計(jì)沒有備用路徑,在網(wǎng)絡(luò)架構(gòu)層面完全沒有容錯(cuò)能力,所以必須在訓(xùn)練代碼中添加處理故障的邏輯,這就直接增加了整個(gè)代碼庫的復(fù)雜程度。現(xiàn)在對(duì)于 NVIDIA 和 AMD GPU 的網(wǎng)絡(luò)結(jié)構(gòu)來說,這是一個(gè)關(guān)鍵問題,因?yàn)檫@種設(shè)計(jì)對(duì)單點(diǎn)故障非常敏感,即便是只有一個(gè) NIC 失敗,連接到它的卡也沒有其他路徑和其他 GPU 通信。現(xiàn)在 LLM 基本在節(jié)點(diǎn)內(nèi)都用的是張量并行,需要所有節(jié)點(diǎn)之間能夠高效通信,所以即使一個(gè)網(wǎng)卡、一個(gè)收發(fā)器或一個(gè) GPU 失敗,整個(gè)服務(wù)器都會(huì)被當(dāng)作是宕機(jī)不可用。
各大 Lab 都在努力讓網(wǎng)絡(luò)能夠重新配置,讓節(jié)點(diǎn)不那么脆弱。解決這個(gè)問題是非常必要的,因?yàn)橹灰粋€(gè) GPU 故障或一根光纖故障,整個(gè) GB200 NVL72 就會(huì)癱瘓。而一個(gè) GB200 NVL72 有 72 個(gè) GPU,價(jià)值數(shù)百萬美元。如果這樣的系統(tǒng)癱瘓,影響和損失要比一個(gè)幾十萬美元的 8 GPU 服務(wù)器宕掉嚴(yán)重得多。
NVIDIA 已經(jīng)意識(shí)到這個(gè)問題的嚴(yán)重性,并且增加了一個(gè)專門的引擎用于 RAS(reliability, availability and serviceability)的維護(hù)。RAS 通過分析卡的數(shù)據(jù),例如溫度、恢復(fù)的 ECC 重試次數(shù)、時(shí)鐘速度、電壓,可以預(yù)測(cè)芯片可能出現(xiàn)的故障,并且提醒數(shù)據(jù)中心的技術(shù)人員,這樣就可以人為地主動(dòng)維護(hù)。舉例來說,技術(shù)人員可以提前調(diào)整風(fēng)扇速度配置文件,加快風(fēng)扇轉(zhuǎn)速,增強(qiáng)散熱效果;或者在計(jì)劃的維護(hù)時(shí)間段內(nèi),暫時(shí)下線服務(wù)器,進(jìn)行更詳細(xì)的物理檢查和維護(hù)工作。此外,在開始訓(xùn)練作業(yè)之前,每個(gè)芯片的 RAS 引擎都會(huì)執(zhí)行全面的自檢,比如運(yùn)行已知結(jié)果的矩陣乘法,檢測(cè)靜默數(shù)據(jù)損壞(SDC)等等。
Microsoft/OpenAI 等為了優(yōu)化成本進(jìn)行了另一種嘗試:在每個(gè)服務(wù)器都用 Cedar Fever-7 網(wǎng)絡(luò)模塊,而不是 8 個(gè) PCIe 外形的 ConnectX-7 網(wǎng)絡(luò)卡。Cedar Fever 模塊的主要優(yōu)點(diǎn)是只需要 4 個(gè) OSFP 插槽,而不是 8 個(gè),這種配置允許在計(jì)算節(jié)點(diǎn)端用雙端口 2x400G 收發(fā)器,而不只是在交換機(jī)端使用,因此可以把連接到 Leaf Switch 的光模塊數(shù)量從每個(gè) H100 節(jié)點(diǎn)的 8 個(gè)減少到 4 個(gè)。連接 GPU 到 Leaf Switch 的總計(jì)算節(jié)點(diǎn)端光模塊數(shù)量也從 98304 減少到 49152。

Source: Nvidia
因?yàn)?GPU 到 Leaf Switch 的鏈路數(shù)量減少了一半,我們可以更好地預(yù)測(cè)首次故障的時(shí)間。根據(jù)估算,每個(gè)雙端口 2x400G 鏈路的平均故障間隔時(shí)間是 4 年(單端口 400G 鏈路是 5 年),這樣一來,首次出故障的估算時(shí)間會(huì)延后到 42.05 分鐘,比沒有使用 Cedar-7 模塊時(shí)的 26.28 分鐘要好得多。

Source: ServeTheHome
Spectrum-X NVIDIA
現(xiàn)在市場上有一個(gè) 10 萬 H100 集群在建中,預(yù)計(jì)年底前會(huì)投入運(yùn)營,這個(gè)集群使用的就是 NVIDIA Spectrum-X 以太網(wǎng)。
Spectrum-X 在大型網(wǎng)絡(luò)中相比 InfiniBand 有很多優(yōu)勢(shì),除了性能和可靠性更好外,成本也更低。Spectrum-X 以太網(wǎng)的 SN5600 交換機(jī)有 128 個(gè) 400G 端口,而 InfiniBand NDR Quantum-2 交換機(jī)只有 64 個(gè) 400G 端口,還有博通的 Tomahawk 5 交換機(jī) ASIC 也支持 128 個(gè) 400G 端口,所以這一代 InfiniBand 的劣勢(shì)非常明顯。
一個(gè)完全互聯(lián)的 10 萬節(jié)點(diǎn)集群可以設(shè)計(jì)為 3 層架構(gòu),如果用 4 層架構(gòu),那么所需的收發(fā)器數(shù)量會(huì)是原來的 1.33 倍。由于 Quantum-2 交換機(jī)的端口容量較低,在 10 萬 H100 集群中,完全互聯(lián)的 GPU 最多只能有 65536 個(gè)。但是下一代 InfiniBand 交換機(jī) Quantum-X800 會(huì)通過 144 個(gè) 800G 端口來解決這個(gè)問題。從數(shù)字“144”可以看出,這是為 NVL72 和 NVL36 系統(tǒng)設(shè)計(jì)的,在 B200 或 B100 集群中應(yīng)該應(yīng)用不會(huì)很多。雖然 Spectrum-X 不需要 4 層結(jié)構(gòu)可以節(jié)省一些成本,但缺點(diǎn)是仍然需要從 Nvidia LinkX 產(chǎn)品線買高價(jià)光模塊,因?yàn)槠渌饽K可能不兼容,或者得不到 Nvidia 的驗(yàn)證。
Spectrum-X 相對(duì)于其他供應(yīng)商的主要優(yōu)勢(shì)在于,用 Spectrum-X 可以得到 NVIDIA 自家通信庫(如 NCCL)的一級(jí)支持,并且 Jensen 會(huì)把 Spectrum-X 的用戶放到新產(chǎn)品線的首批客戶隊(duì)列里。但如果使用博通的 Tomahawk 5 芯片,要想實(shí)現(xiàn)最大吞吐量,就需要大量的內(nèi)部工程努力來優(yōu)化網(wǎng)絡(luò)與 NCCL 的配合。

Source: SemiAnalysis
以太網(wǎng)相比 InfiniBand 的缺點(diǎn)是不支持 SHARP 網(wǎng)絡(luò)內(nèi)歸約,而網(wǎng)絡(luò)內(nèi)歸約可以通過在網(wǎng)絡(luò)交換機(jī)上進(jìn)行求和操作,減少每個(gè) GPU 需要發(fā)送和處理的數(shù)據(jù)量,從而理論上把網(wǎng)絡(luò)帶寬提高 2 倍。

Source: Nvidia
此外,在第一代 400G Spectrum-X 中,NVIDIA 用了 Bluefield-3 來代替 ConnectX-7 作為臨時(shí)的方案,這也是 Spectrum 的一個(gè)劣勢(shì)。不過我們預(yù)計(jì)在未來的幾代產(chǎn)品中, ConnectX-8 能和 800G Spectrum-X 完美配合。對(duì)于超大規(guī)模的數(shù)據(jù)中心來說,Bluefield-3 比 ConnectX-7 卡要貴 300 美元 ASP 左右,而且還要多耗費(fèi) 50W 的電力,導(dǎo)致每個(gè)節(jié)點(diǎn)都需要額外的 400W 電力,這會(huì)降低整個(gè)訓(xùn)練服務(wù)器的“每皮焦耳智能(intelligence per picojoule)”。在相同網(wǎng)絡(luò)架構(gòu)的前提下,用 Spectrum X 的設(shè)備相比 Broadcom Tomahawk 5 需要額外的 5MW 電力來支持 10 萬 GPU 的部署。
為了避免支付 NVIDIA 產(chǎn)品的高額費(fèi)用,很多公司會(huì)選擇使用基于 Broadcom Tomahawk 5 的交換機(jī)。每個(gè)基于 Tomahawk 5 的交換機(jī)都有和 Spectrum-X SN5600 交換機(jī)相同的 128 個(gè) 400G 端口,并且如果公司有優(yōu)秀的網(wǎng)絡(luò)工程師,是能夠?qū)崿F(xiàn)類似性能的。而且需要用到的光收發(fā)器和銅纜都是通用的,可以從任何地方的任何一家供應(yīng)商買到,混合搭配使用。
大多數(shù)客戶會(huì)直接和 ODM 合作,比如和 Celestica 合作使用基于 Broadcom 的交換機(jī) ASIC,或者與 Innolight 和 Eoptolink 合作進(jìn)行光模塊的生產(chǎn)。計(jì)算下來交換機(jī)和通用光模塊的成本,Tomahawk 5 與 Nvidia InfiniBand 相比要便宜得多,與 Nvidia Spectrum-X 相比也同樣更有價(jià)格優(yōu)勢(shì)。
使用 Tomahawk 5 交換機(jī)的一個(gè)缺點(diǎn)是,需要有足夠的工程能力來修補(bǔ)和優(yōu)化 NCCL 通信集合。NCCL 通信集合在初始狀態(tài)下僅針對(duì) NVIDIA 的 Spectrum-X 和 InfiniBand 進(jìn)行了優(yōu)化,也只對(duì)他們開箱即用。
好在如果建一個(gè) 10 萬卡集群的預(yù)算有 40 億美元,那是有足夠的工程能力來修補(bǔ) NCCL 和編寫優(yōu)化程序的。當(dāng)然,軟件開發(fā)仍然是件很困難的事,NVIDIA 始終保持著技術(shù)領(lǐng)先,但總體上來說,每個(gè)超大規(guī)模企業(yè)都會(huì)進(jìn)行這些優(yōu)化,并最終從 InfiniBand 轉(zhuǎn)向其他方案。

Source: SemiAnalysis
每個(gè) 10 萬 H100 集群的總投資(capex)大概是 40 億美元,根據(jù)所選擇的網(wǎng)絡(luò)類型有所不同,SemiAnalysis 提供的 4 種方案包括:
1. 4 層 InfiniBand 網(wǎng)絡(luò):包括 32768 個(gè) GPU 島,Rail Optimized 設(shè)計(jì),收斂比 7:1
2. 3 層 Spectrum-X 網(wǎng)絡(luò):包括 32768 個(gè) GPU 島,Rail Optimized 設(shè)計(jì),收斂比 7:1
3. 3 層 InfiniBand 網(wǎng)絡(luò):包括 24576 個(gè) GPU 島,Non-Rail Optimized 設(shè)計(jì),用前端網(wǎng)絡(luò)做島間連接
4.?3 層 Broadcom Tomahawk 5 以太網(wǎng)網(wǎng)絡(luò):包括 32768 個(gè) GPU 島,Rail Optimized 設(shè)計(jì),收斂比為 7:1

Source: SemiAnalysis
從上圖可以看出:
? 4 層 InfiniBand 網(wǎng)絡(luò)比其他方案要貴 1.3-1.6 倍,因此未來不會(huì)有公司繼續(xù)用大型 InfiniBand 網(wǎng)絡(luò)。
? 3 層 InfiniBand 網(wǎng)絡(luò)可行,但嚴(yán)重降低了并行方案的靈活性。
? Spectrum X 可以提供更大的島,并增加島間互聯(lián)的帶寬,成本也和其他方案差不多,但致命缺點(diǎn)是需要更多電力。
基于 Broadcom Tomahawk 5 的 32k-GPU 集群,再加上頂層 7:1 的收斂比,是目前公認(rèn)最具成本效益的方案,也是很多公司采用的網(wǎng)絡(luò)設(shè)計(jì)方案,它提供了最高的性能與 TCO(Total Cost of Ownership,總擁有成本)比,避免支付給 NVIDIA 高額費(fèi)用。Broadcom Tomahawk 5 的解決方案已經(jīng)被包括 Meta 在內(nèi)的多家公司采用,并且推出的時(shí)間比 NVIDIA 的 Spectrum-X 更早。
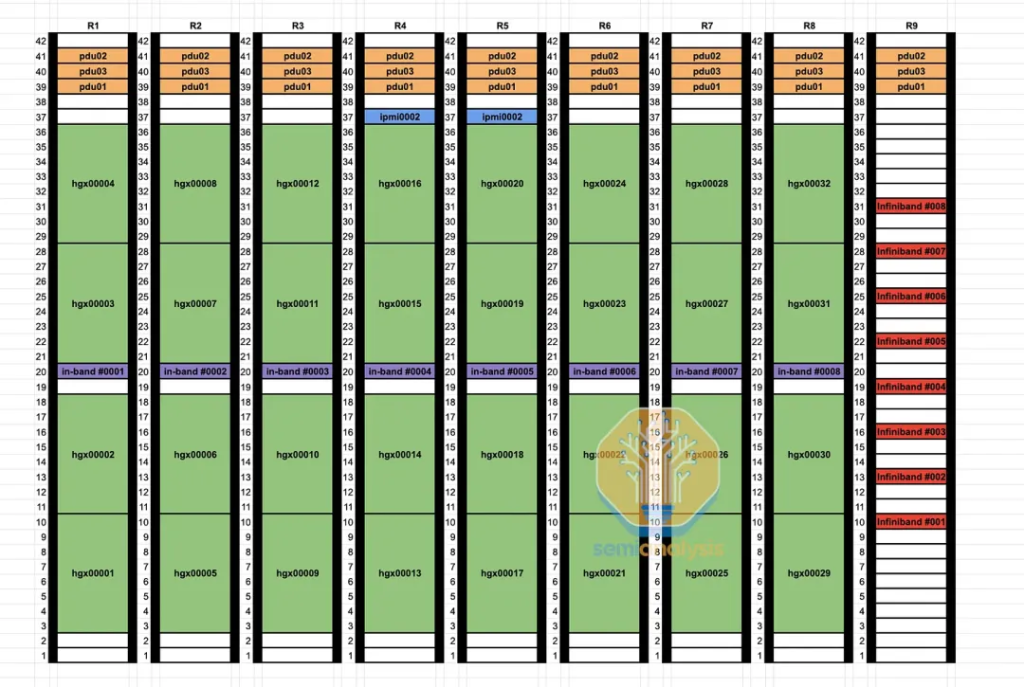
在整個(gè)數(shù)據(jù)中心的設(shè)計(jì)中,優(yōu)化機(jī)架布局也是很重要的,要盡可能高效地使用銅纜和多模光纖。下圖是采用 Rail Optimized 設(shè)計(jì)的 Spectrum-X / Tomahawk 5 32k 集群平面圖。從圖中可以看到,為了優(yōu)化光纖使用,有些行的 Leaf Switch 并沒有放在同一行,這種設(shè)計(jì)主要為了能優(yōu)化使用 50 米多模光纖。如果將多模光模塊放置在行的末端,中間的 Spine Switch 就會(huì)超出 50 米的有效距離,導(dǎo)致無法連接。

使用 Rail Optimized 的
Spectrum-X / Tomahawk 5 32k 集群平面圖
Source: SemiAnalysis

Source: SemiAnalysis
注:在這個(gè) 10 萬節(jié)點(diǎn)集群在建的 4 棟大樓中,
有 3 棟已建成
在這個(gè) Microsoft 的開發(fā)集群中,每個(gè)機(jī)架支持高達(dá) 40kW 的功率密度,每個(gè)機(jī)架內(nèi)容納 4 個(gè) H100 節(jié)點(diǎn)。這個(gè) infra 的布線設(shè)置非常獨(dú)特,銅纜(特別是每行末端的粗黑纜)用于機(jī)架內(nèi)交換機(jī)之間的連接。相比之下,從 H100 到 Leaf Switch 的連接則是使用多模 AOC 光纖,可以通過藍(lán)色纜線識(shí)別。

Source: Microsoft
總的來說,NVIDIA 還是 10 萬 H100 集群的最大贏家,因?yàn)榱飨?NVIDIA 的收入構(gòu)成了整個(gè) BOM 的大頭。未來預(yù)計(jì) Broadcom 將在幾乎所有超大規(guī)模計(jì)算集群中占據(jù)主導(dǎo)地位,networking 收入將持續(xù)增長。NVIDIA 也將繼續(xù)保持增長勢(shì)頭,因?yàn)楹芏嘈屡d云服務(wù)廠商、國家和企業(yè)都將選擇 NVIDIA 的參考設(shè)計(jì)。
文章轉(zhuǎn)自微信公眾號(hào)@海外獨(dú)角獸
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)






