
鴻蒙應用實踐:利用扣子API開發起床文案生成器
“百度智能云千帆大模型”是百度智能云平臺上提供的一個大模型服務體系,它集成了多種先進的預訓練語言模型和AI技術,旨在為企業和個人開發者提供強大的人工智能解決方案。這些模型包括但不限于基于Llama2架構的中文增強版本、ERNIE系列的旗艦級模型以及其他由百度自研或基于開源框架優化的高性能模型。千帆平臺上的大模型不僅支持中英雙語,覆蓋廣泛的應用場景如對話問答、創作生成、代碼生成等,而且部分模型針對特定需求進行了優化,如壓縮加速、指令微調等,以適應不同資源條件下的部署和使用需求。用戶可以通過千帆大模型平臺進行模型的選擇、訓練調優及部署調用,以實現對復雜任務的支持和高效處理。
API是一個軟件解決方案,作為中介,使兩個應用程序能夠相互交互。以下一些特征讓API變得更加有用和有價值:
1.模型相關
對話Chat:支持創建chat,用于發起一次對話。
續寫Completions:支持創建completion,用于發起一次續寫請求,不支持多輪會話等。
自定義模型:平臺支持HuggingFace Transformer架構的自定義大模型導入,將自定義模型發布為服務,并支持通過相關API調用該服務。
圖像Images:提供圖像相關API能力。
Token計算,根據輸入計算token數。
2.模型服務:提供創建服務、獲取服務詳情等API能力。
3.模型管理:提供獲取模型、模型版本詳情,獲取用戶/預置模型及將訓練任務發布為模型等API能力。
4.模型調優:提供創建訓練任務、任務運行、停止任務運行及獲取任務運行詳情等API能力。
5.數據管理:提供創建數據集等數據集管理、導入導出數據集任務、數據清洗任務管理等API能力。
6.Prompt工程:提供模板管理、Prompt優化任務、評估等API能力。
7.插件應用:提供知識庫、智慧圖問、天氣等API能力。
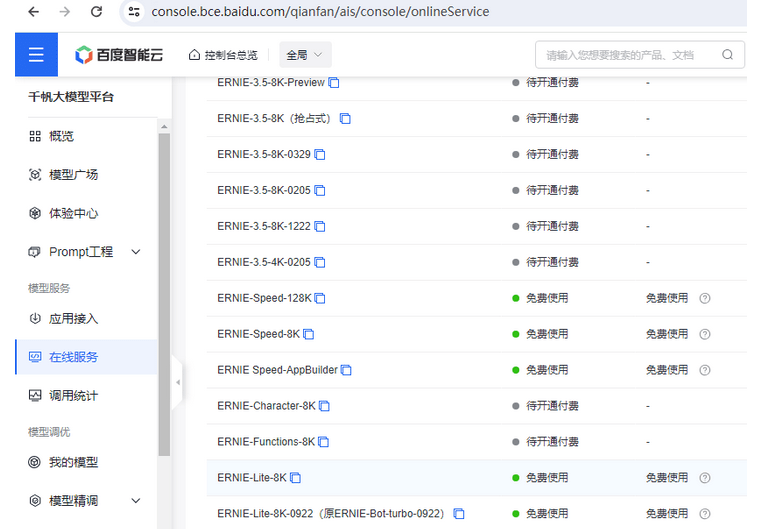
進入百度智能云 千帆大模型平臺。
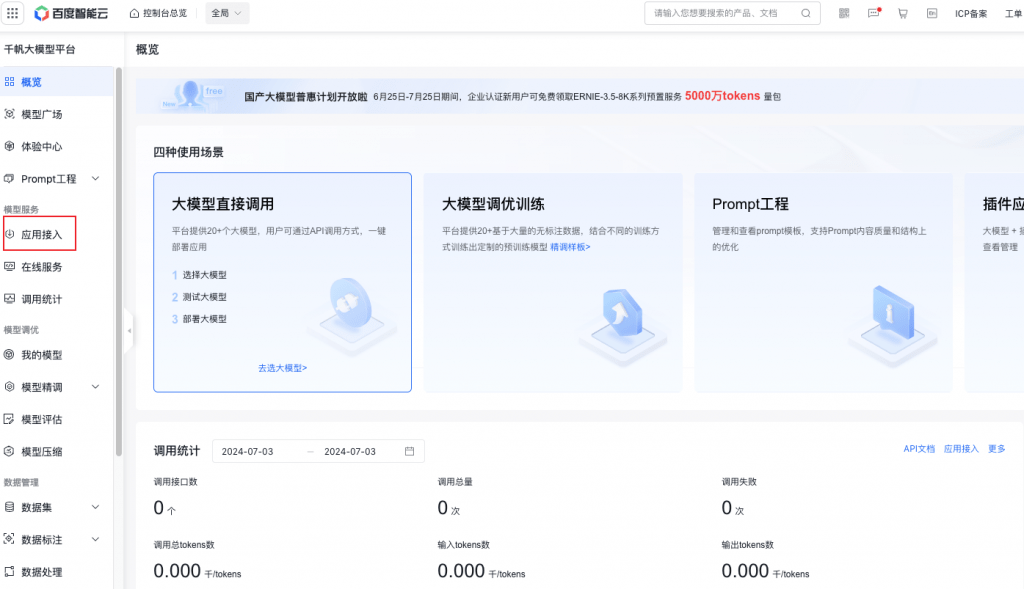
點擊應用接入,進入應用列表
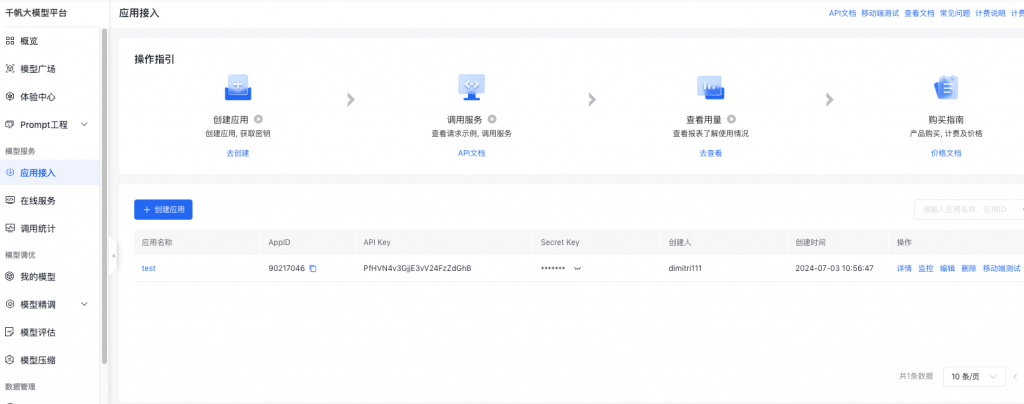
點擊創建應用
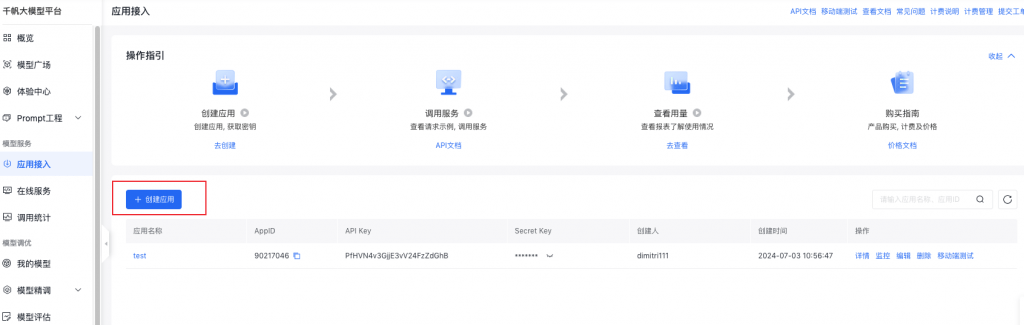
先記錄下這個秘鑰后面調用需要用到

接口文檔 地址:<https://cloud.baidu.com/doc/WENXINWORKSHOP/s/klqx7b1xf>
請求地址: https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie_speed
請求方式: POST
根據不同鑒權方式,查看對應 Header 參數。
| 名稱 | 類型 | 必填 | 描述 |
| Content-Type | string | 是 | 固定值 application/json |
| 名稱 | 類型 | 必填 | 描述 |
| Content-Type | string | 是 | 固定值 application/json |
| x-bce-date | string | 否 | 當前時間,遵循 ISO8601 規范,格式如 2016-04-06T08:23:49Z |
| Authorization | string | 是 | 用于驗證請求合法性的認證信息。更多內容請參考簡介 – 相關參考Reference | 百度智能云文檔,簽名工具可參考IAM簽名工具 |
只有訪問憑證 access\_token 鑒權方式,需使用 Query 參數。
| 名稱 | 類型 | 必填 | 描述 |
| access_token | string | 是 | 通過 API Key 和 Secret Key 獲取的 access_token,參考 獲取access_token – 千帆大模型平臺 | 百度智能云文檔 |
| 名稱 | 類型 | 必填 | 描述 |
| messages | List(message) | 是 | 聊天上下文信息。 • messages 成員不能為空,1 個成員表示單輪對話,多個成員表示多輪對話 • 最后一個 message 為當前請求的信息,前面的 message 為歷史對話信息 • 必須為奇數個成員,成員中 message 的 role 必須依次為 user、assistant • message 中的 content 總長度和 system 字段總內容不能超過 24000 個字符,且不能超過 6144 tokens |
| stream | bool | 否 | 是否以流式接口的形式返回數據,默認 false |
| temperature | float | 否 | 較高的數值會使輸出更加隨機,而較低的數值會使其更加集中和確定。默認 0.95,范圍 (0, 1.0],不能為 0 |
| top_p | float | 否 | 影響輸出文本的多樣性,取值越大,生成文本的多樣性越強。默認 0.7,取值范圍 [0, 1.0] |
| penalty_score | float | 否 | 通過對已生成的 token 增加懲罰,減少重復生成的現象。值越大表示懲罰越大。默認 1.0,取值范圍:[1.0, 2.0] |
| system | string | 否 | 模型人設,主要用于人設設定。長度限制:message 中的 content 總長度和 system 字段總內容不能超過 24000 個字符,且不能超過 6144 tokens |
| stop | List(string) | 否 | 生成停止標識,當模型生成結果以 stop 中某個元素結尾時,停止文本生成。每個元素長度不超過 20 字符,最多 4 個元素 |
| max_output_tokens | int | 否 | 指定模型最大輸出 token 數。如果設置此參數,范圍 [2, 2048]。如果不設置此參數,最大輸出 token 數為 1024 |
| frequency_penalty | float | 否 | 正值根據迄今為止文本中的現有頻率對新 token 進行懲罰,從而降低模型逐字重復同一行的可能性;默認 0.1,取值范圍 [-2.0, 2.0] |
| presence_penalty | float | 否 | 正值根據 token 記目前是否出現在文本中來對其進行懲罰,從而增加模型談論新主題的可能性;默認 0.0,取值范圍 [-2.0, 2.0] |
| user_id | string | 否 | 表示最終用戶的唯一標識符 |
message 說明
| 名稱 | 類型 | 描述 |
| role | string | 當前支持以下:• user: 表示用戶• assistant: 表示對話助手 |
| content | string | 對話內容,不能為空 |
部分參數如下。
| 名稱 | 描述 |
| X-Ratelimit-Limit-Requests | 一分鐘內允許的最大請求次數 |
| X-Ratelimit-Limit-Tokens | 一分鐘內允許的最大 tokens 消耗,包含輸入 tokens 和輸出 tokens |
| X-Ratelimit-Remaining-Requests | 達到 RPM 速率限制前,剩余可發送的請求數配額,如果配額用完,將會在 0-60s 后刷新 |
| X-Ratelimit-Remaining-Tokens | 達到 TPM 速率限制前,剩余可消耗的 tokens 數配額,如果配額用完,將會在 0-60s 后刷新 |
| 名稱 | 類型 | 描述 |
| id | string | 本輪對話的 id |
| object | string | 回包類型• chat.completion:多輪對話返回 |
| created | int | 時間戳 |
| sentence_id | int | 表示當前子句的序號。只有在流式接口模式下會返回該字段 |
| is_end | bool | 表示當前子句是否是最后一句。只有在流式接口模式下會返回該字段 |
| is_truncated | bool | 當前生成的結果是否被截斷 |
| result | string | 對話返回結果 |
| need_clear_history | bool | 表示用戶輸入是否存在安全風險,是否關閉當前會話,清理歷史會話信息。• true:是,表示用戶輸入存在安全風險,建議關閉當前會話,清理歷史會話信息。• false:否,表示用戶輸入無安全風險 |
| ban_round | int | 當 need_clear_history 為 true 時,此字段會告知第幾輪對話有敏感信息,如果是當前問題,ban_round=-1 |
| usage | usage | token 統計信息 |
usage 說明
| 名稱 | 類型 | 描述 |
| prompt_tokens | int | 問題 tokens 數 |
| completion_tokens | int | 回答 tokens 數 |
| total_tokens | int | tokens 總數 |
注意 :同步模式和流式模式,響應參數返回不同,詳細內容參考示例描述。
代碼如下:
1 import requests
2 import json
3 import datetime
4
5 class QIANFAN:
6
7 _api_url = "https://aip.baidubce.com"
8
9 def __init__(self, api_key, secret_key):
10 self.API_KEY = api_key
11 self.SECRET_KEY = secret_key
12
13 url = self._api_url + "/oauth/2.0/token"
14 params = {"grant_type": "client_credentials", "client_id": self.API_KEY, "client_secret": self.SECRET_KEY}
15 result = self.http_request_v2(url, method="POST", params=params)
16 if 'access_token' in result:
17 self.access_token = result["access_token"]
18 else:
19 print(result)
20 exit()
21
22
23 def chat(self, model="ernie-lite-8k", message=None, **kwargs):
24 url = f"{self._api_url}/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/{model}?access_token={self.access_token}"
25
26 payload = json.dumps({
27 "messages": [{"role": "user", "content": message}],
28 "temperature": 0.95,
29 "penalty_score": 1
30 })
31
32 for key, value in kwargs.items():
33 payload[key] = value
34
35 print(payload)
36 response = self.http_request_v2(url, method="POST", params=payload)
37 return response
38
39 # 生成headers頭
40 def headers(self, params=None):
41 headers = {}
42 headers['Content-Type'] = 'application/json'
43 return headers
44
45 def http_request_v2(self, url, method="GET", headers={}, params=None):
46 headers['User-Agent'] = 'Mozilla/5.0 \(Windows NT 6.1; WOW64\) AppleWebKit/537.36 \(KHTML, like Gecko\) Chrome/39.0.2171.71 Safari/537.36'
47 if method == "GET":
48 response = requests.get(url)
49 elif method == "POST":
50 # data = bytes(json.dumps(params), 'utf-8')
51 response = requests.post(url, data= params)
52 elif method == "DELETE":
53 response = requests.delete(url, data= data)
54
55 result = response.json()
56 return result調用方法如下:
示例
API_KEY = "PfHVN4v3GjjE3vV24FzZdGhB"
SECRET_KEY = "***chat_client = QIANFAN(API_KEY, SECRET_KEY)
print(vars(chat_client))
result = chat_client.chat(model='ernie_speed', message="1加1為什么等于2?")
print(result["result"])
以上就是使用Python語言調用千帆大模型的全部過程和代碼示例。







