
Python + BaiduTransAPI :快速檢索千篇英文文獻(附源碼)
從說明里面能到到,它主要是服務于Online以及Enterprise,其實就是server、portal那一套。空口說無憑證,我們直接從接口文檔里面看功能。
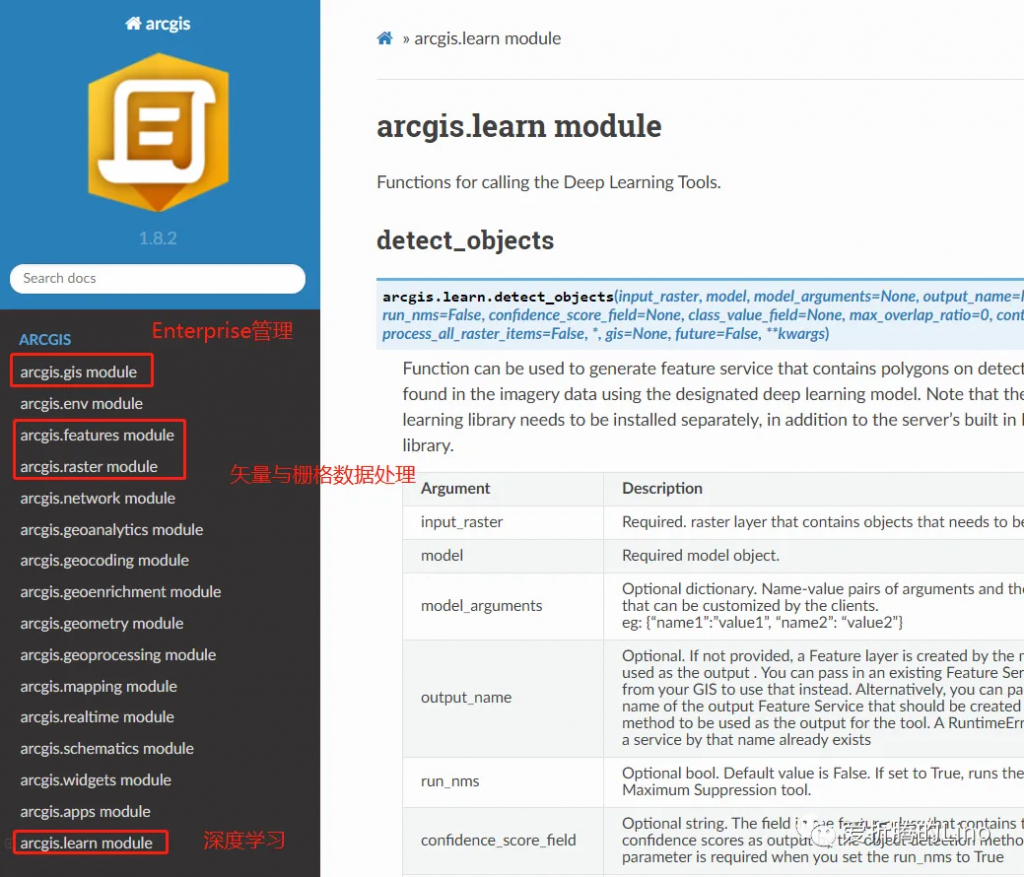
上圖中跟我們有關的是arcgis.learn(深度學習)模塊,其余的部分在本文中不會提到。如果想學習的話,可以參考官網的教程以及示例筆記本(notebook),里面很詳細的。
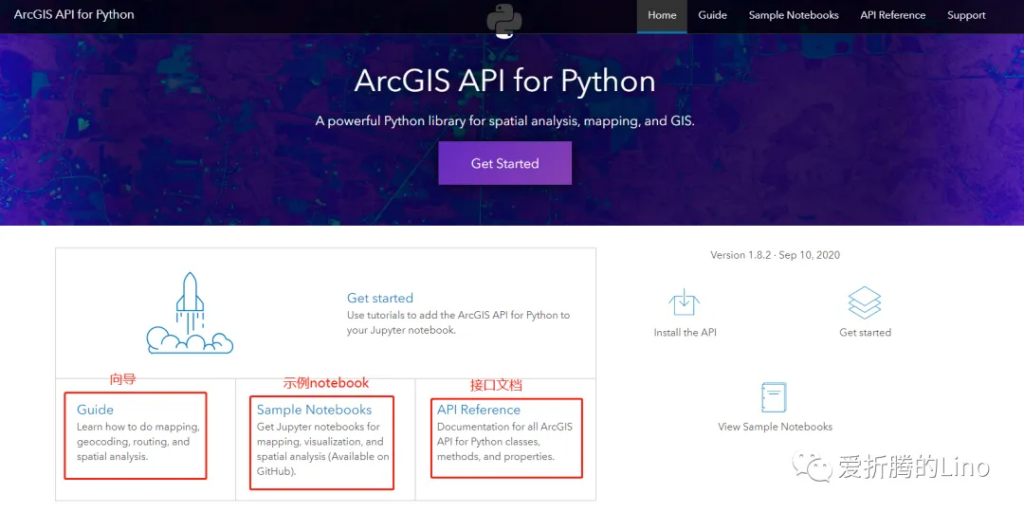
其中最重要的是需要看Sample Notebooks,里面講的很全很詳細(墻裂推薦)。這個部分,可以根據自己需求選擇性的去看某一部分。
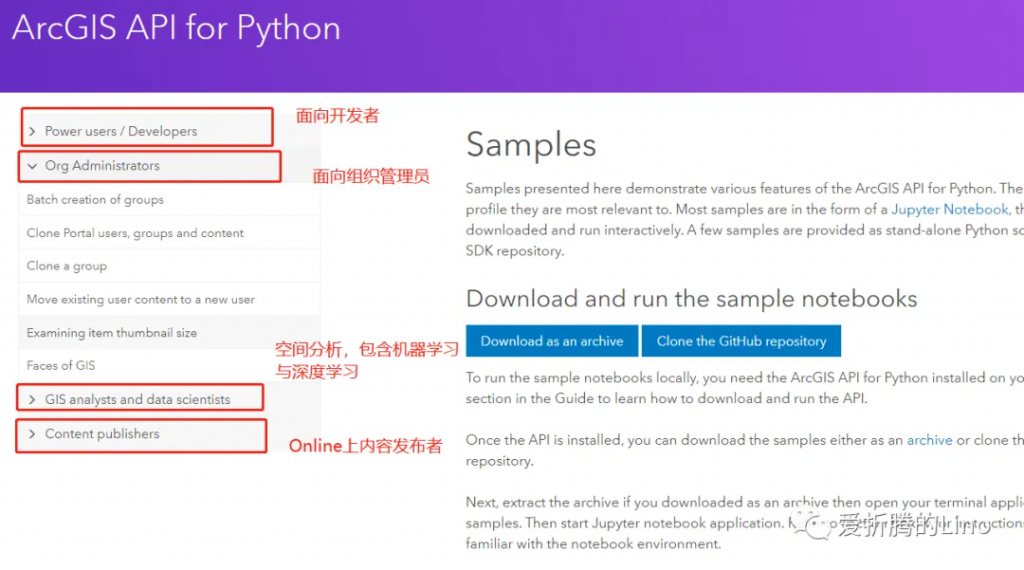
那咱們主要是深度學習,就看上圖中的第三部分就好了(友情提示,第三部分很多示例筆記本)。隨便點一個深度學習相關的,比如說之前公眾號中寫過的《利用深度學習檢測路面損壞情況》:
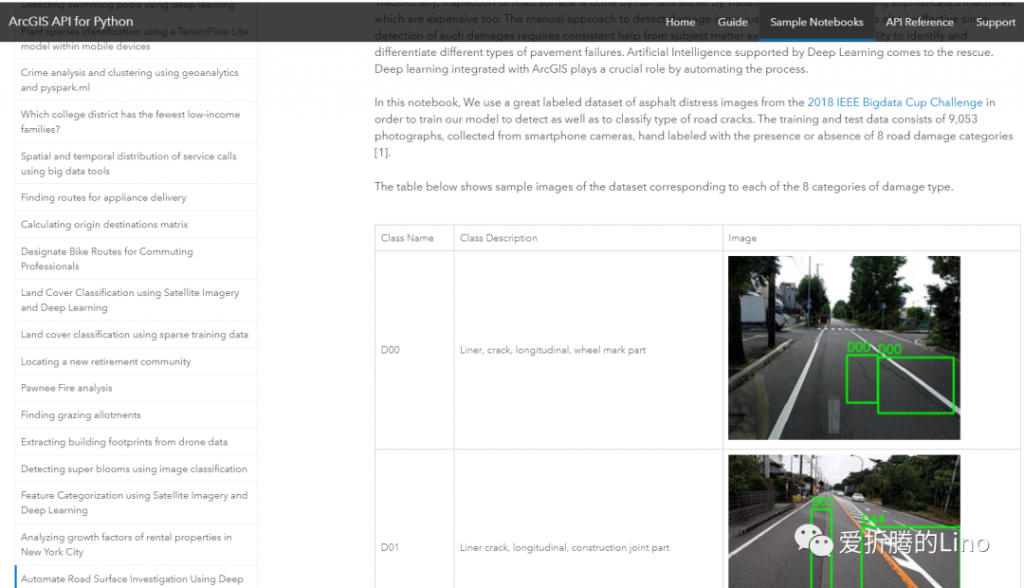
還有很多機器學習相關、空間分析相關的,大家可以自己深入看一下,但是要深入看的的話需要Python基礎以及ArcGIS相關基礎。
在深度學習工作流中,老三步:樣本制作?->?模型訓練?->?推理。其中使用ArcGIS API for Python的是模型訓練環節,其實推理階段倒不是不能使用API去做,只是你需要一個Image Server,當然如果有多個的話,還是很推薦你使用集群去做推理的。
讓我們來看一下arcgis.learn模塊的東西:
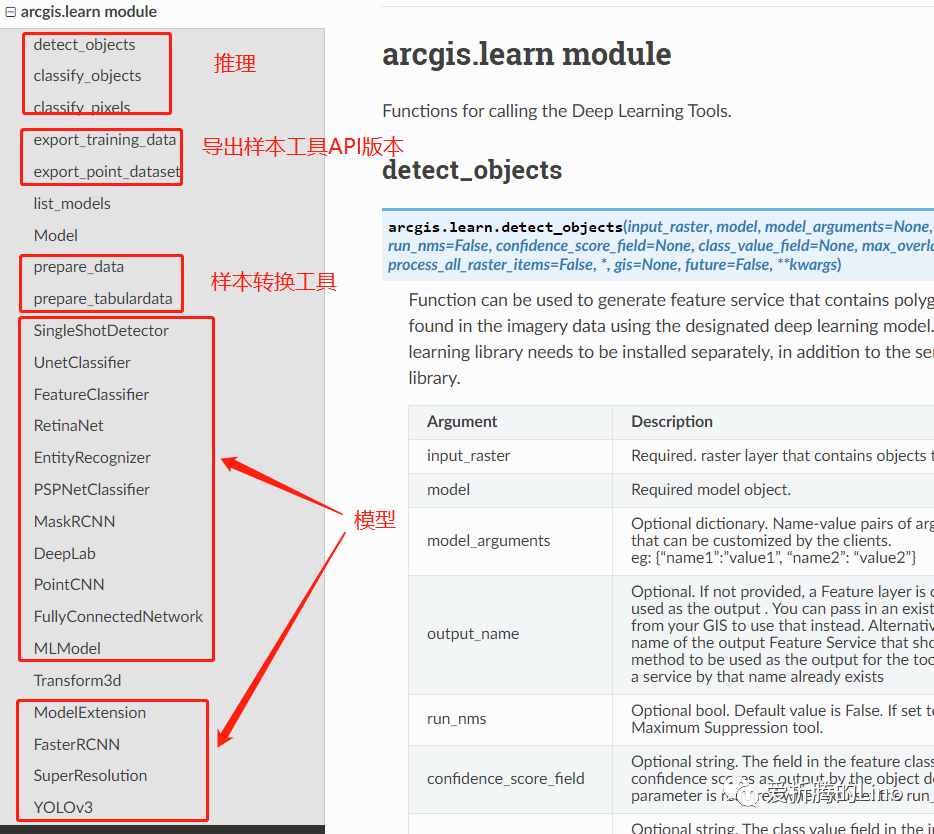
可能會有人問,樣本轉換工具是干啥的?如果你之前沒有接觸過編程,(敲黑板)那得特意留意一下我下面講的內容:
首先,我們使用ArcGIS Pro導出樣本之后,是這個樣子的:
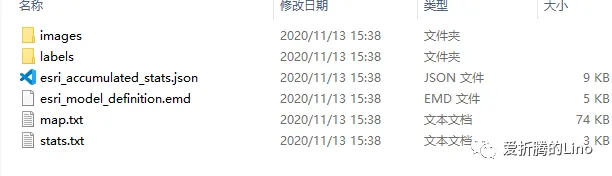
然后,這個文件夾里面存儲著很多圖片,是沒辦法直接使用的,因為他們是存儲在計算機磁盤空間中的。因此,要使用這些圖片、標簽等等,就需要做轉化,將樣本文件從磁盤空間中加載到計算機內存中。這個時候就需要用到樣本轉換工具,在Pro中工具(下圖中的訓練深度學習模型工具)內部其實也封裝了這個過程。
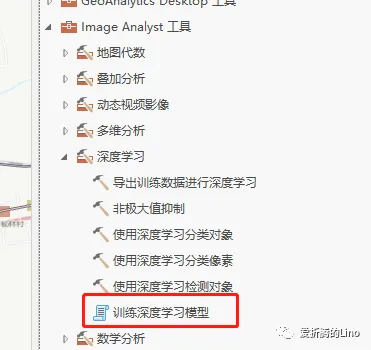
通過使用API會讓你看到更多工具內部看不到的過程,可能第一次會有所疑惑,用多了就懂了。
關于模型那塊是干嘛的就不用我說啦吧,但是其實你發現,ArcGIS API for Python的模型比ArcGIS?Pro中的要多很多。所以強烈推薦你們使用API做訓練,因為有更多模型,而且不管是ArcGIS Pro訓練深度學習模型工具中有沒有的模型,都可以使用Pro去做推理。唯一一個需要注意的是API與Pro的版本對應關系,所以建議你們使用最新版本Pro。
另外,API是完全開源的,有興趣的話可以去github上查看更多源碼。
好了,看完上面之后下面可以愉快的coding了。真的很簡單,你們信我。而且簡單的同時你可以訓練出世界頂級模型(這句話可不是我說的,是fastai作者說的)。因為arcgis.learn模塊內部其實封裝的是fastai框架,這個框架的作者在kaggle上很出名的,感興趣的可以查一下。
不說那么多其他的,那就,來吧,展示:
首先打開notebook,沒有用過的可以參考我之前的文章:《為什么選擇在Jupyter Notebook中編寫代碼》,然后導包:
from arcgis.learn import prepare_data,UnetClassifier其中prepare_data是樣本轉換工具,UnetClassifer是模型,在本場景中使用的是像素分類,小麥提取。你可以按照自己需求去導入模型,代碼上差異并不是很大。
另外不同場景的模型在之前的文章中有總結過:《ArcGIS API for Python:深度學習模塊概覽》,不熟悉的可以點擊查看。
然后使用prepare_data將樣本加載到內存中:
# path是樣本文件夾路徑
path = r'E:\deeplearning\data\dongxiaomai\xiaomai_samplearea_tra30'
data = prepare_data(path,batch_size=16,val_split_pct=0.2)
data
prepare_data方法有幾個參數需要注意一下:
path:樣本文件夾,必填。
chip_size:樣本切片大小。
val_split_pct:驗證集劃分比重。
bach_size:批大小。
除了一個path是必填的之外,其余的都可以根據實際情況選填。除了上面幾個參數之外,接口文檔中還有更詳細的說明: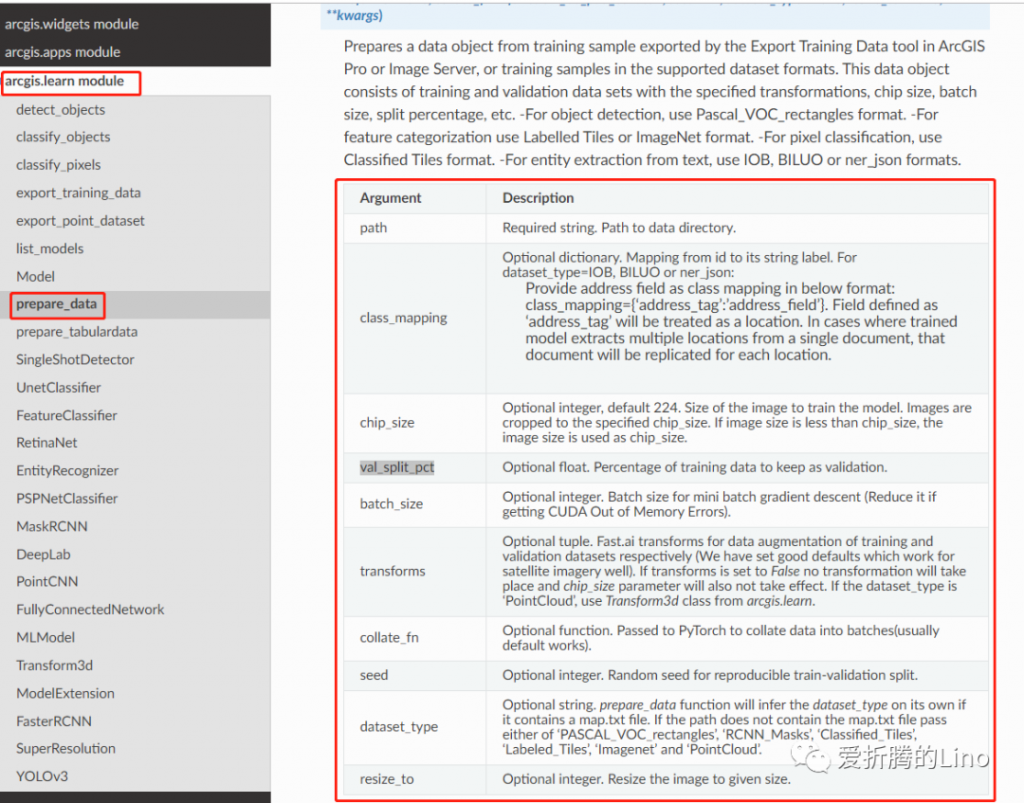
一定要學會從接口文檔中查看參數信息
在加載完數據值后,還可以查看一下我們的樣本數據大概都是啥樣的:
data.show_batch()上圖中紅色半透明部分是我標注的樣本,在data.show_batch方法里,會將樣本疊在原始影像上,從而很方便的查看一個batch中的數據是啥樣的。你可以多運行幾次這行代碼看看。
數據加載完成后,便可以實例化我們的模型:
model = UnetClassifier(data)這一步就很簡單了,直接模型括號里面填上上一部中加載的樣本對象。然后使用model.lr_find()函數查找學習率:
lr = model.lr_find()
lr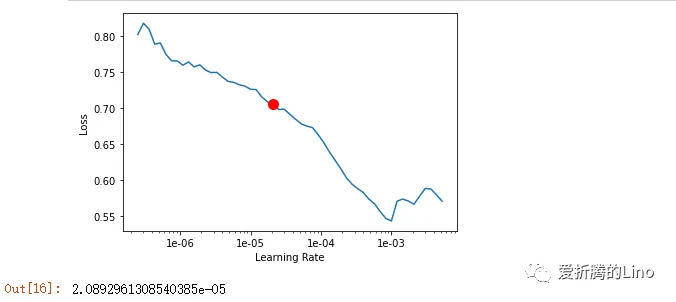
這一步是固定寫法,就是查找最合適的學習率。學習率查找完成后,便可以訓練模型了:
model.fit(200,lr)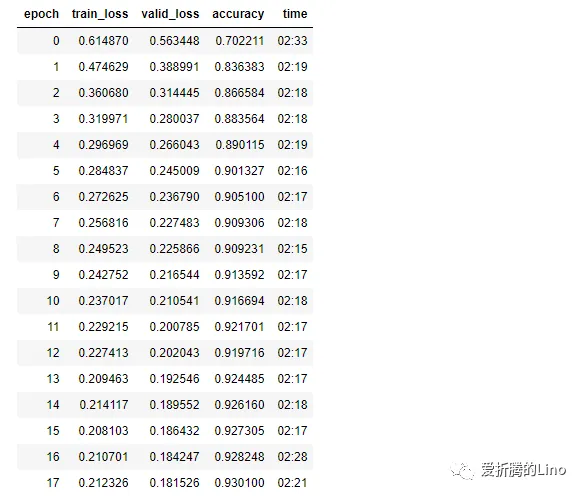
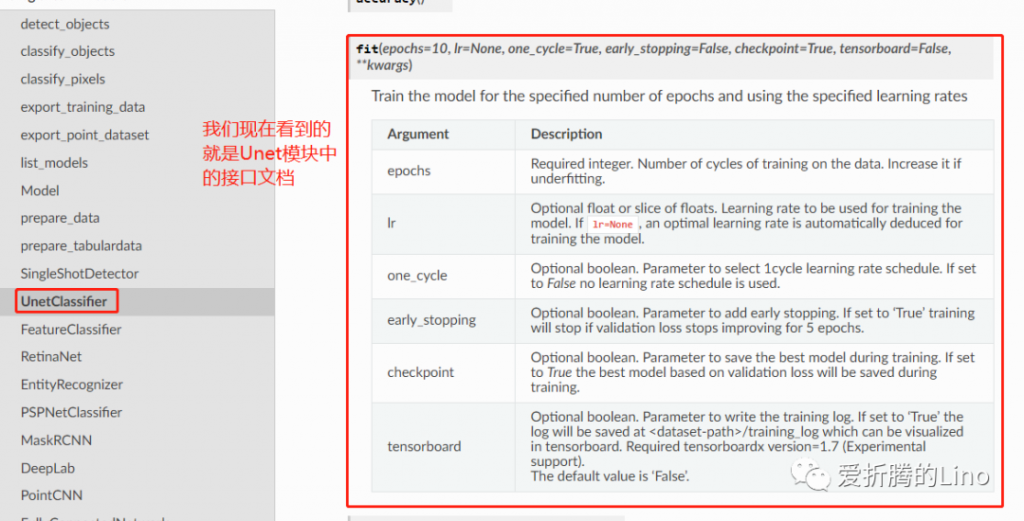
訓練模型中有幾個參數注意一下:
在接口文檔中,此部分要找到對應的模型下面,查接口參數:
訓練完成之后,可以查看一下損失曲線:
model.plot_losses()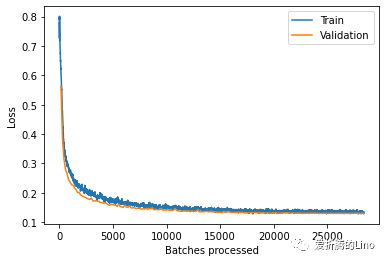
固定寫法,不需要改動。
還可以使用model.show_results方法查看當前模型在驗證集上的表現情況:
model.show_results()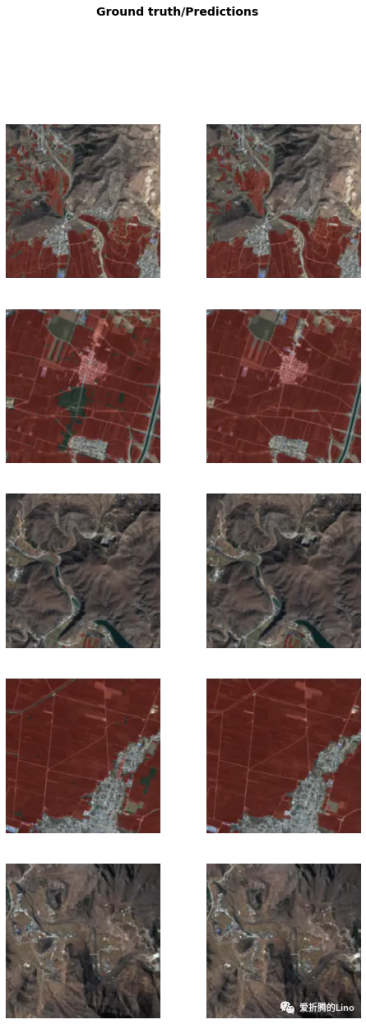
左邊為真實標簽,右邊為當前模型推理所得。這種方法可以很直觀的看到模型的表現如何。另外除了此種方法之外,還有其他精度指標可查看:
model.mIOU()
因為是圖像分割,所以比較在意mIOU,其他的模型視情況選擇精度指標查看。接口文檔中都可以查到,比如說本文中用到的mIOU指標,在接口文檔中查看:
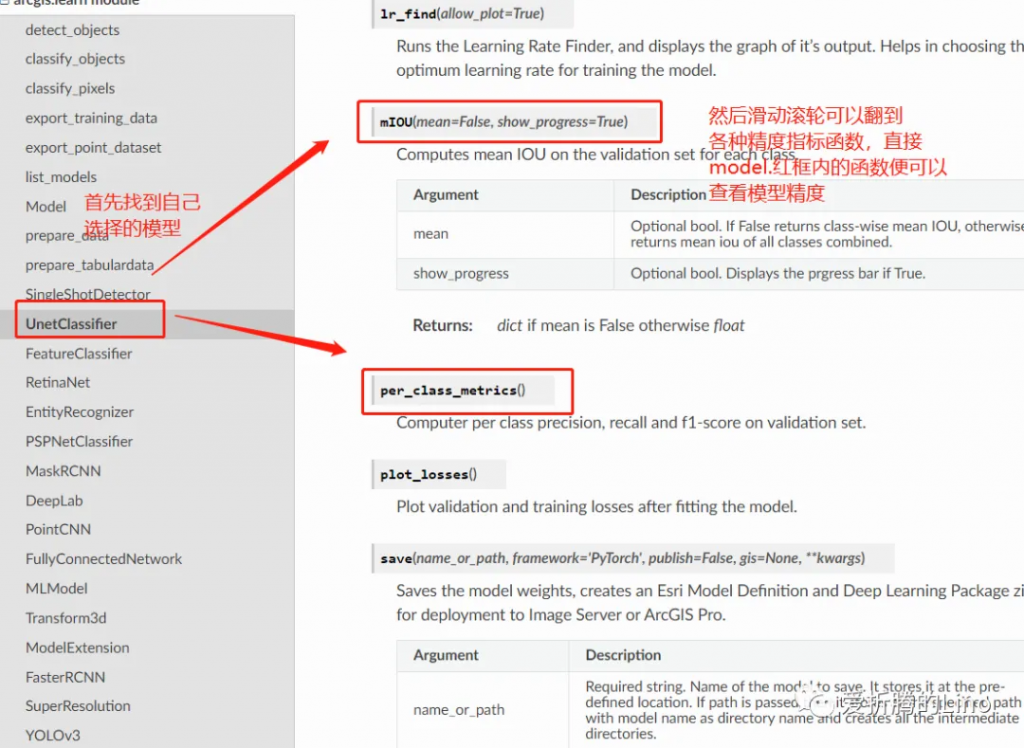
如果說,你對模型滿意的話,便可以使用model.save方法保存模型了:
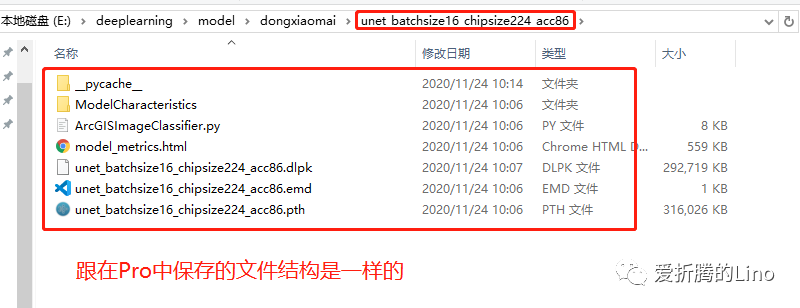
model.save(r'E:\deeplearning\model\dongxiaomai\unet_batchsize16_chipsize224_acc86')固定寫法,替換掉文件夾路徑即可。到文件夾中查看如下:
然后便可以使用ArcGIS Pro進行推理了。推理階段在此處就不講了。
肯定有人看完上面,覺得還不是很清晰,不會咋辦。那你來打我,其實改動的地方很少的,我們來看一下去掉每一行運行結果后的完整代碼:
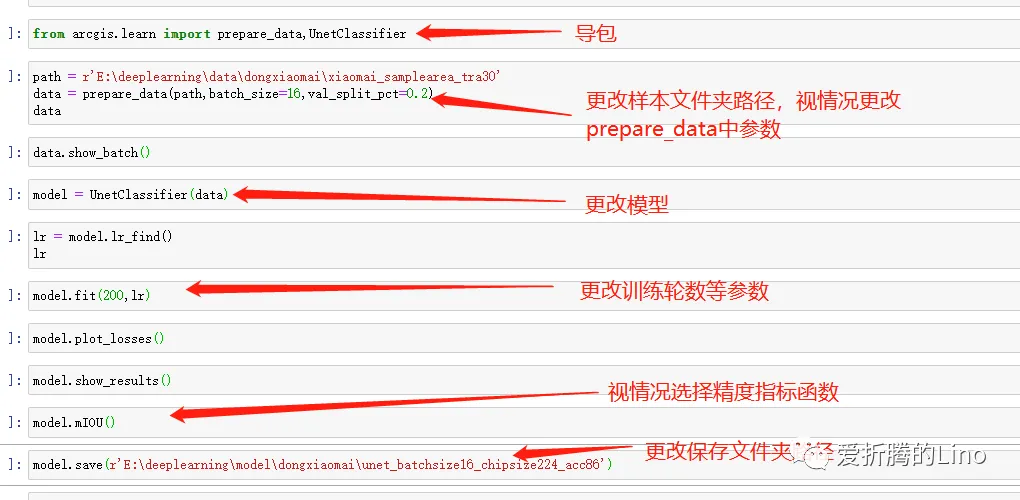
其中小部分都是固定寫法,大部分都是固定格式,小部分需要根據模型不同更改寫法。
這么短幾行代碼,你去寫一個月,還不會,那你來打我。會不會python影響的已經不大了,折騰吧。不得不吹一下,把深度學習封裝成如此簡潔易用,確實很厲害。
文章轉自微信公眾號@數讀城事
Python + BaiduTransAPI :快速檢索千篇英文文獻(附源碼)

掌握ChatGPT API集成的方便指南
node.js + express + docker + mysql + jwt 實現用戶管理restful api
nodejs + mongodb 編寫 restful 風格博客 api
表格插件wpDataTables-將 WordPress 表與 Google Sheets API 連接
手把手教你用Python和Flask創建REST API
使用 Django 和 Django REST 框架構建 RESTful API:實現 CRUD 操作
ASP.NET Web API快速入門介紹

2024年在線市場平臺的11大最佳支付解決方案