LlamaIndex,也被稱為GPT Index,是一個(gè)為大語(yǔ)言模型(LLM)設(shè)計(jì)的數(shù)據(jù)框架,于2023年1月29日正式發(fā)布。LlamaIndex的出現(xiàn)為L(zhǎng)LM應(yīng)用程序提供了一個(gè)強(qiáng)大的平臺(tái),通過(guò)連接到不同的數(shù)據(jù)源,幫助用戶攝取、構(gòu)建和訪問(wèn)私有或特定領(lǐng)域的數(shù)據(jù)。LlamaIndex在Python和Typescript中均可使用,為用戶提供了一種自然語(yǔ)言與數(shù)據(jù)交互的方式。雖然LLM已經(jīng)在大量公開(kāi)數(shù)據(jù)上進(jìn)行了預(yù)訓(xùn)練,但LlamaIndex通過(guò)將用戶的私有數(shù)據(jù)與現(xiàn)有的LLM相結(jié)合,實(shí)現(xiàn)了數(shù)據(jù)的增強(qiáng)處理和索引管理。
LlamaIndex有什么幫助?
LlamaIndex為用戶提供了多個(gè)關(guān)鍵工具:
- 數(shù)據(jù)連接器:幫助用戶從API、PDF、SQL等不同源和格式中攝取數(shù)據(jù)。
- 數(shù)據(jù)索引:將數(shù)據(jù)結(jié)構(gòu)化為中間表示形式,便于LLM的高效使用。
- 引擎:提供自然語(yǔ)言訪問(wèn)接口,包括查詢引擎用于知識(shí)檢索,聊天引擎用于與數(shù)據(jù)對(duì)話。
- 數(shù)據(jù)代理:通過(guò)工具和API增強(qiáng)LLM的功能,充當(dāng)知識(shí)工作者。
- 應(yīng)用程序集成:與LangChain、Flask、Docker、ChatGPT等生態(tài)系統(tǒng)無(wú)縫連接。
通過(guò)這些工具,LlamaIndex不僅簡(jiǎn)化了數(shù)據(jù)處理流程,還提升了LLM的適用性和效率。
核心原理
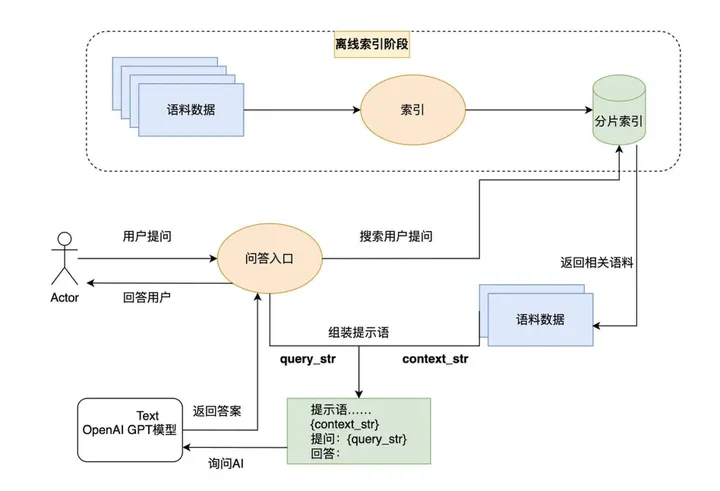
LlamaIndex的核心在于通過(guò)索引和搜索的方式實(shí)現(xiàn)數(shù)據(jù)的高效查詢和處理。首先,它為外部數(shù)據(jù)庫(kù)建立索引,然后在用戶提問(wèn)時(shí)從這些數(shù)據(jù)庫(kù)中搜索相關(guān)信息,最后利用AI的語(yǔ)義理解能力生成答案。在索引和搜索階段,可以使用OpenAI的嵌入接口,也可以選擇其他大語(yǔ)言模型的嵌入方法。LlamaIndex的獨(dú)特之處在于,它不僅限于文本索引,還支持將圖片轉(zhuǎn)換為文本進(jìn)行索引,實(shí)現(xiàn)多模態(tài)功能。
LlamaIndex的安裝
安裝
安裝LlamaIndex非常簡(jiǎn)單,只需使用Pip命令即可完成安裝:
pip install llama-index
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple llama-index
pip install -i https://mirrors.aliyun.com/pypi/simple llama-index llama-index-core
pip install -i https://mirrors.aliyun.com/pypi/simple -qU llama-index llama-index-core
這些命令可以幫助用戶在不同的Python環(huán)境下快速安裝LlamaIndex及其核心組件。
使用方法
在Python中使用LlamaIndex有兩種主要方式:
- 入門版:安裝llama-index包,包含核心功能和部分集成。
- 定制版:安裝llama-index-core包,并根據(jù)需要添加特定的LlamaIndex集成包。
LlamaIndex提供了豐富的集成選項(xiàng),用戶可以根據(jù)應(yīng)用需求選擇合適的插件和集成包。
使用 OpenAI 構(gòu)建一個(gè)簡(jiǎn)單的向量存儲(chǔ)索引
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()
index = VectorStoreIndex.from_documents(documents)
上述代碼展示了如何使用OpenAI的API密鑰構(gòu)建一個(gè)簡(jiǎn)單的向量存儲(chǔ)索引,便于后續(xù)的數(shù)據(jù)查詢和處理。
使用非 OpenAI 的 LLM 構(gòu)建索引
import os
os.environ["REPLICATE_API_TOKEN"] = "YOUR_REPLICATE_API_TOKEN"
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.replicate import Replicate
from transformers import AutoTokenizer
llama2_7b_chat = "meta/llama-2-7b-chat:8e6975e5ed6174911a6ff3d60540dfd4844201974602551e10e9e87ab143d81e"
Settings.llm = Replicate(
model=llama2_7b_chat,
temperature=0.01,
additional_kwargs={"top_p": 1, "max_new_tokens": 300},
)
Settings.tokenizer = AutoTokenizer.from_pretrained(
"NousResearch/Llama-2-7b-chat-hf"
)
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
documents = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()
index = VectorStoreIndex.from_documents(
documents,
)
query_engine = index.as_query_engine()
query_engine.query("YOUR_QUESTION")
index.storage_context.persist()
以上代碼演示了如何使用托管在Replicate上的Llama 2構(gòu)建索引。
LlamaIndex的案例應(yīng)用
基礎(chǔ)用法
5行代碼來(lái)高效地查詢指定文件內(nèi)你所需的內(nèi)容
-
第一步,下載數(shù)據(jù):從指定網(wǎng)址下載Paul Graham的文本,并將其保存到數(shù)據(jù)文件夾中。
-
第二步,設(shè)置您的OpenAI API密鑰:將API密鑰設(shè)置為環(huán)境變量,以便代碼訪問(wèn)。
-
第三步,加載數(shù)據(jù)并構(gòu)建索引:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
- 第四步,查詢您的數(shù)據(jù):創(chuàng)建一個(gè)查詢引擎并詢問(wèn)問(wèn)題。
query_engine = index.as_query_engine()
response = query_engine.query("作者在成長(zhǎng)過(guò)程中做了什么?")
print(response)
- 第五步,使用日志查看查詢和事件:通過(guò)添加日志代碼,可以跟蹤查詢過(guò)程。
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
- 第六步,存儲(chǔ)您的索引:將索引持久化到磁盤(pán)以避免重復(fù)計(jì)算。
index.storage_context.persist()
進(jìn)階用法
使用LlamaIndex構(gòu)建和查詢本地文檔索引
LlamaIndex不僅適用于簡(jiǎn)單的查詢,還支持復(fù)雜的本地索引構(gòu)建和查詢,通過(guò)與ChatGPT接口結(jié)合,用戶可以設(shè)計(jì)出功能強(qiáng)大的RAG系統(tǒng),實(shí)現(xiàn)對(duì)本地文檔的高效索引和查詢。
FAQ
-
問(wèn):LlamaIndex是什么?
- 答:LlamaIndex是一個(gè)為大語(yǔ)言模型(LLM)設(shè)計(jì)的數(shù)據(jù)框架,用于攝取、構(gòu)建和訪問(wèn)私有或特定領(lǐng)域的數(shù)據(jù)。
-
問(wèn):如何安裝LlamaIndex?
- 答:可以通過(guò)Pip命令進(jìn)行安裝,例如
pip install llama-index。
-
問(wèn):LlamaIndex的核心功能是什么?
- 答:LlamaIndex提供數(shù)據(jù)連接器、數(shù)據(jù)索引、自然語(yǔ)言查詢接口以及與生態(tài)系統(tǒng)的集成功能。
-
問(wèn):LlamaIndex支持哪些編程語(yǔ)言?
- 答:LlamaIndex支持Python和Typescript。
-
問(wèn):LlamaIndex與OpenAI接口如何結(jié)合使用?
- 答:通過(guò)提供OpenAI API密鑰,LlamaIndex可以構(gòu)建基于OpenAI的向量存儲(chǔ)索引,實(shí)現(xiàn)高效的數(shù)據(jù)查詢。
熱門推薦
一個(gè)賬號(hào)試用1000+ API
助力AI無(wú)縫鏈接物理世界 · 無(wú)需多次注冊(cè)
3000+提示詞助力AI大模型
和專業(yè)工程師共享工作效率翻倍的秘密
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
久久亚洲影视婷婷|
欧美色国产精品|
美日韩一级片在线观看|
欧美视频中文一区二区三区在线观看|
国产精品系列在线|
av电影天堂一区二区在线|
中文一区二区完整视频在线观看|
蜜臀久久99精品久久久久宅男
|
欧美色精品在线视频|
亚洲国产精品久久久久秋霞影院|
91福利国产成人精品照片|
亚洲一区二区在线免费观看视频|
欧美日韩欧美一区二区|
麻豆精品久久久|
久久精品一区蜜桃臀影院|
成人在线综合网|
亚洲v日本v欧美v久久精品|
日韩色在线观看|
成人美女在线观看|
日韩中文字幕亚洲一区二区va在线
|
一区二区在线观看视频|
欧美影院午夜播放|
国产一区视频网站|
亚洲最新视频在线播放|
久久这里只有精品首页|
91原创在线视频|
麻豆91免费看|
亚洲视频一区在线观看|
日韩情涩欧美日韩视频|
色婷婷狠狠综合|
国产福利一区二区三区|
免费一级欧美片在线观看|
亚洲欧美综合网|
久久综合国产精品|
日韩一区二区三|
欧美色老头old∨ideo|
成人精品高清在线|
国产在线精品一区二区不卡了|
亚洲最新在线观看|
亚洲人成伊人成综合网小说|
久久婷婷国产综合国色天香|
在线播放视频一区|
欧美日韩极品在线观看一区|
99re这里只有精品视频首页|
国产999精品久久|
国产精品影音先锋|
国产原创一区二区三区|
久久99久久99精品免视看婷婷
|
日本一区二区电影|
欧美精品一区二区三区蜜桃|
日韩精品最新网址|
日韩欧美一区二区三区在线|
欧美日韩国产色站一区二区三区|
在线观看www91|
欧美午夜精品久久久久久孕妇|
av综合在线播放|
91视频在线观看|
欧洲精品一区二区三区在线观看|
91蝌蚪国产九色|
欧美性极品少妇|
欧美福利电影网|
精品国产1区二区|
国产日韩欧美制服另类|
久久久久久久免费视频了|
欧美国产综合色视频|
《视频一区视频二区|
亚洲制服丝袜av|
美女www一区二区|
国产福利视频一区二区三区|
成人精品免费看|
欧美亚洲丝袜传媒另类|
日韩欧美一区二区在线视频|
国产日韩欧美电影|
亚洲一区二区五区|
久久成人18免费观看|
国产成人综合网|
欧美性色黄大片手机版|
欧美成人午夜电影|
亚洲天天做日日做天天谢日日欢|
亚洲超碰精品一区二区|
国产精品一二三|
69久久99精品久久久久婷婷
|
91美女视频网站|
91麻豆精品国产91久久久|
国产午夜一区二区三区|
亚洲一区欧美一区|
成人丝袜高跟foot|
日韩精品专区在线影院重磅|
樱花影视一区二区|
成人美女视频在线观看18|
制服丝袜中文字幕一区|
亚洲品质自拍视频|
国产98色在线|日韩|
日韩美女在线视频|
日韩成人一区二区三区在线观看|
99国产精品久久久|
国产精品久久久久aaaa|
丁香啪啪综合成人亚洲小说|
日韩精品一区二区三区中文精品|
亚洲综合小说图片|
av在线不卡免费看|
欧美国产亚洲另类动漫|
国产精一品亚洲二区在线视频|
69堂成人精品免费视频|
一区二区视频免费在线观看|
波多野结衣亚洲|
日韩一区欧美小说|
91视频在线观看免费|
国产精品久久久久久户外露出
|
国产成人精品亚洲777人妖|
久久这里只精品最新地址|
精品一二线国产|
欧美精品一区二区三区一线天视频
|
欧美午夜精品久久久久久超碰|
亚洲精品免费电影|
欧美日韩中文字幕一区二区|
亚洲国产精品一区二区尤物区|
在线一区二区三区四区五区
|
56国语精品自产拍在线观看|
日韩av在线播放中文字幕|
欧美日本一道本在线视频|
日本va欧美va瓶|
久久久久99精品一区|
成人伦理片在线|
一区二区三区波多野结衣在线观看|
日本久久一区二区三区|
亚洲免费三区一区二区|
欧美老年两性高潮|
狠狠色狠狠色综合|
中文天堂在线一区|
欧美特级限制片免费在线观看|
免播放器亚洲一区|
国产精品女同一区二区三区|
色网站国产精品|
久久超碰97中文字幕|
国产精品欧美一区二区三区|
欧美色图第一页|
国产精品羞羞答答xxdd|
一级精品视频在线观看宜春院|
日韩一区二区免费视频|
99久久免费国产|
激情成人综合网|
亚洲成人av在线电影|
日韩你懂的在线播放|
99视频在线观看一区三区|
日本少妇一区二区|
㊣最新国产の精品bt伙计久久|
3atv在线一区二区三区|
91丝袜美腿高跟国产极品老师|
美女脱光内衣内裤视频久久网站
|
久久综合狠狠综合久久综合88|
色综合久久综合|
国产成人在线看|
久久66热偷产精品|
五月激情六月综合|
亚洲视频一区二区在线|
久久久久久久久99精品|
日韩欧美在线不卡|
88在线观看91蜜桃国自产|
色哦色哦哦色天天综合|
voyeur盗摄精品|
国内偷窥港台综合视频在线播放|
日韩电影在线免费看|
视频一区二区中文字幕|
亚洲国产一区在线观看|
亚洲天堂久久久久久久|
亚洲国产精品激情在线观看|
久久精品视频网|
亚洲精品一区二区三区影院|
精品免费一区二区三区|
日韩欧美久久久|
精品国产百合女同互慰|
精品国产污污免费网站入口|
精品日韩一区二区三区免费视频|
91麻豆精品国产无毒不卡在线观看|
欧美日产在线观看|
欧美一区二区三区免费在线看
|
欧美精品一二三|
日韩亚洲欧美一区二区三区|
日韩一区二区三|
久久亚洲二区三区|
国产精品三级在线观看|
亚洲另类在线制服丝袜|
综合久久综合久久|
亚洲小少妇裸体bbw|
丝袜亚洲另类丝袜在线|
精品在线观看视频|
粗大黑人巨茎大战欧美成人|
97久久精品人人澡人人爽|
91久久香蕉国产日韩欧美9色|
91精品福利视频|
日韩美女在线视频|
亚洲视频在线一区二区|
亚洲成人免费观看|
国产一区在线不卡|
一本久道中文字幕精品亚洲嫩|
欧美日韩一区视频|
国产三级精品视频|
亚洲一区在线观看网站|
国产一区二区不卡在线|