
LLM的預訓練任務有哪些
BERT,全稱為Bidirectional Encoder Representations from Transformers,是由Google開發的一種預訓練語言模型。作為自然語言處理(NLP)領域的革命性框架,BERT刷新了多個任務的記錄,為NLP研究和應用帶來了巨大的影響。盡管BERT在算法上并非完全創新,但它將前人的優點集于一身,通過適當的改進,形成了如今無與倫比的強大能力。
BERT的設計核心在于其雙向編碼能力,這種能力使模型能夠從兩個方向理解上下文,從而在處理多義詞、語境理解等方面表現出色。其預訓練過程涉及大規模無監督數據集,如Wikipedia和書籍語料庫,這種預訓練使得BERT在各種下游任務中能夠快速適應和微調。
預訓練思想的集成:BERT借鑒了計算機視覺領域的預訓練思想,在語言模型中首次引入雙向編碼。
雙向編碼的實現:BERT采用了完形填空任務的思想,即Masked Language Model(MLM),結合了Word2Vec的CBOW思想,由此增強了模型對上下文的理解能力。
特征提取的變革:不同于傳統的RNN模型,BERT使用Transformer作為特征提取器,充分發揮了注意力機制的作用。
模型結構的優化:在CBOW思想之上增加了語言掩碼模型(MLM),并通過減少訓練和推理階段的不匹配,避免過擬合。
句子間語義關系的捕捉:BERT通過下句預測(Next Sentence Prediction,NSP)來學習句子間的語義聯系,這也是BERT的重要創新之一。

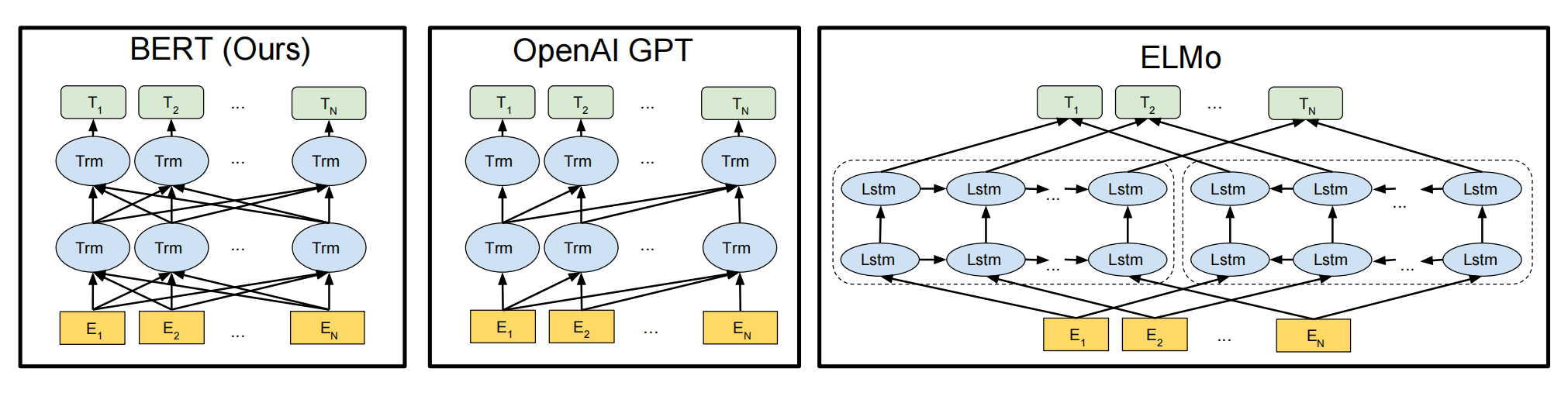
在語言模型領域,BERT與ELMo和GPT有顯著的區別和優勢。ELMo采用自左向右和自右向左的雙向LSTM網絡進行編碼,雖然實現了雙向編碼,但本質上仍是兩個單向編碼的結合。GPT則使用Transformer Decoder進行單向編碼,適用于生成任務。
BERT的優勢主要體現在以下方面:
雙向編碼:BERT通過Transformer Encoder實現了真正的雙向編碼,增強了語義理解能力。
廣泛的適用性:BERT作為預訓練模型,泛化能力強,不需要大量語料訓練即可應用于特定場景。
簡單的端到端模型:無需調整網絡結構,只需在最后添加適用于不同任務的輸出層。
快速并行和性能提升:基于Transformer的架構,BERT可以快速并行處理,同時提高模型的準確率。
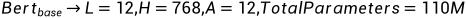
BERT有兩種主要版本:BERT Base和BERT Large。BERT Base由12層Transformer組成,擁有12個注意力頭和1.1億個參數。BERT Large則擁有24層Transformer、16個注意力頭和3.4億個參數。盡管參數量巨大,但BERT可以通過并行計算和深度學習技術有效處理。
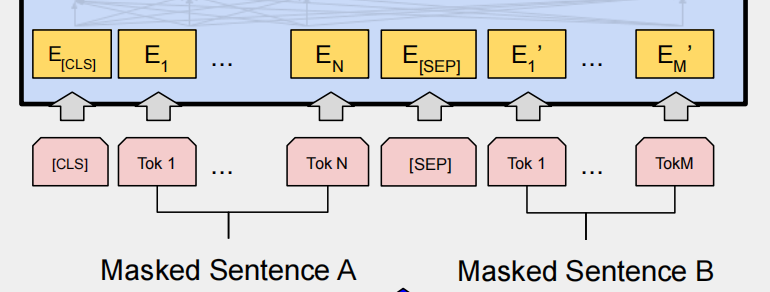
BERT的輸入是每個token的表征,使用WordPiece算法構建的詞典。輸入序列的開頭插入特定的分類token [CLS],用于聚集序列信息,句子間用[SEP]分隔。每個token的表征由token、segment和position三個embeddings相加組成。
Token Embeddings:每個詞轉換為固定維度向量,BERT中為768維。
Segment Embeddings:區分token所屬的句子。
Position Embeddings:編碼序列順序信息,幫助BERT理解語序。
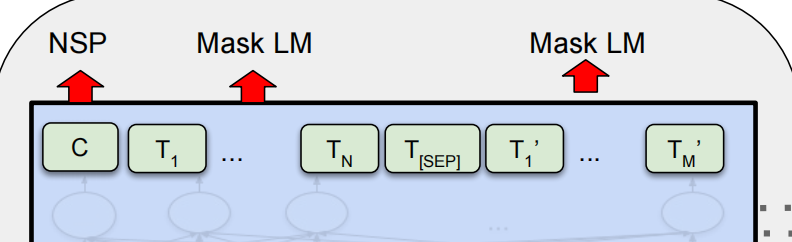
BERT的輸出是句子中每個token的768維向量,首位置的[CLS]用于句子級任務,其它token用于token級任務。通過這種設計,BERT能夠適應不同的下游任務。
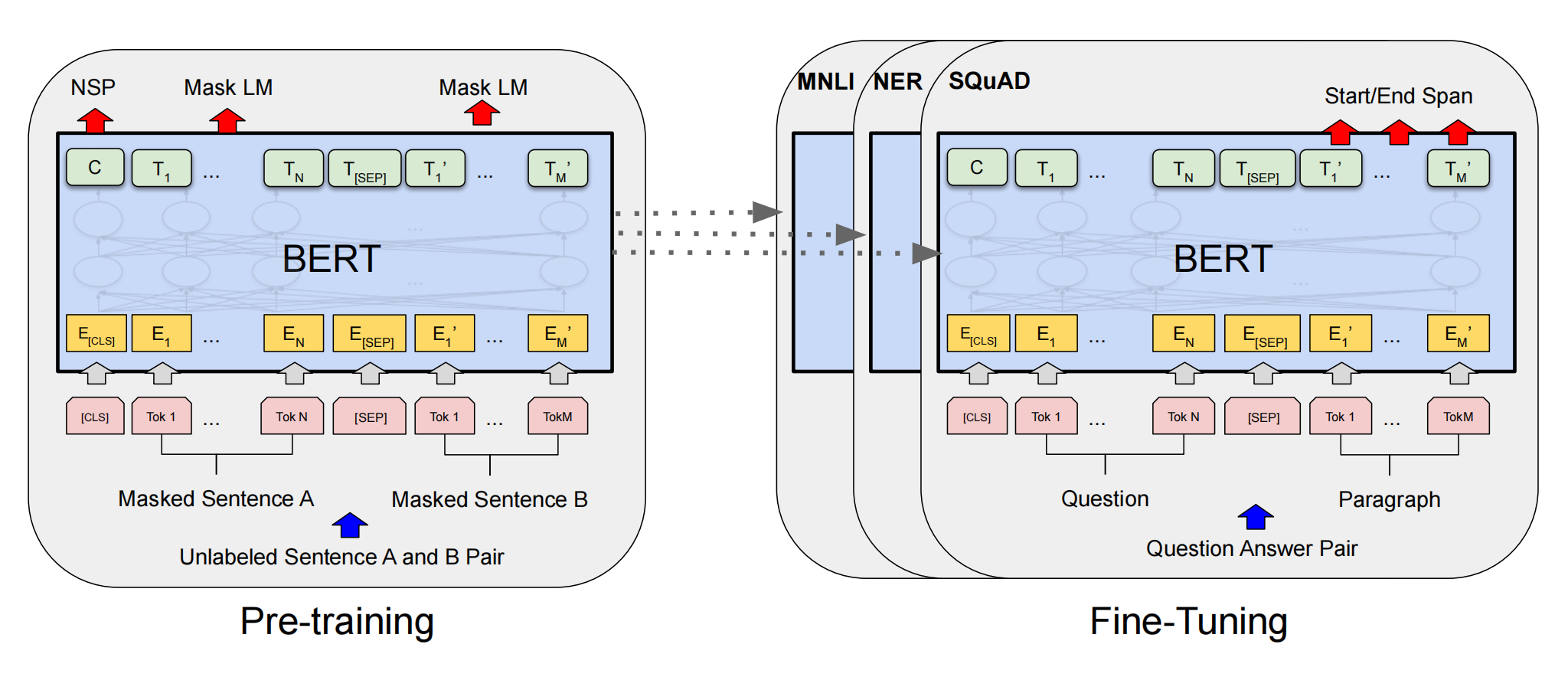
BERT的預訓練包含兩個任務:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。
MLM通過隨機掩蓋句子中15%的詞,訓練模型根據上下文預測被掩蓋的詞。這一過程提升了模型對上下文的理解。
NSP用于訓練模型理解句子間關系,50%的樣本中句子B緊接句子A,另50%為隨機句子。這一任務增強了模型的句子級別理解能力。
BERT的出現標志著NLP領域的一次重大跨越,不僅提升了模型的性能,還為后續研究提供了新的思路和方向。







