
使用 Flask App Builder 進行 API 查詢的完整指南
預訓練任務主要分為三大類:掩碼語言模型、自編碼模型,因果語言模型、自回歸模型,和序列到序列模型、前綴語言模型。
掩碼語言模型是一種自編碼模型,其主要任務是將輸入文本中的一些token替換為特殊的[MASK]字符,并預測這些被替換的字符。模型只計算掩碼部分的loss,其余部分不計算loss。這種模型有助于模型理解上下文,從而提高對未見過詞匯的預測能力。
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForMaskedLM.from_pretrained('bert-base-uncased')
input_text = "Hello, my name is [MASK]"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
outputs = model(input_ids)
因果語言模型,也稱為自回歸模型,接收完整的序列輸入,并基于上文的token預測當前的token。在這種模型中,輸入序列的結束位置通常有一個特殊token,稱為eos_token。這種模型的代表是GPT系列模型。
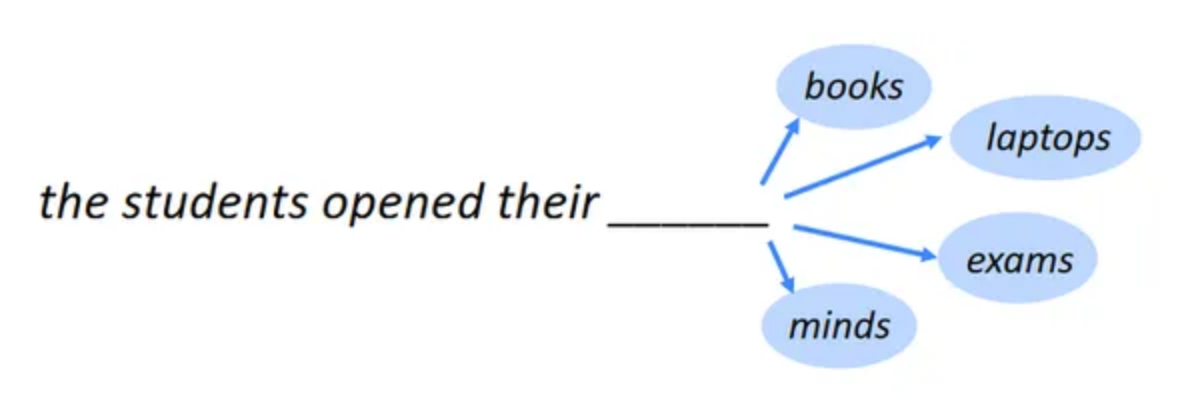
序列到序列模型,又稱為前綴語言模型,采用編碼器解碼器的方式實現。任務較為多樣化,通常用于文本摘要和機器翻譯。這種模型的核心是通過解碼器對輸入進行轉換,并計算解碼器部分的loss。
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('t5-small')
model = T5ForConditionalGeneration.from_pretrained('t5-small')
input_text = "translate English to French: How are you?"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
outputs = model.generate(input_ids)
在實際應用中,預訓練模型的實現需要進行數據集的準備、模型的加載以及訓練參數的設置。以下是一個掩碼語言模型的完整代碼示例。
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForMaskedLM, Trainer, TrainingArguments
dataset = load_dataset('wikitext', 'wikitext-2-raw-v1', split='train')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForMaskedLM.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my name is [MASK]", return_tensors='pt')
outputs = model(**inputs)
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=1,
per_device_train_batch_size=16,
save_steps=10,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
)
trainer.train()預訓練模型需要大量的數據來進行訓練。數據集的規模和質量直接影響模型的效果。在選擇數據集時,需要考慮數據的多樣性和覆蓋面。此外,數據的清洗和預處理也是非常重要的步驟,以確保數據的質量。
預訓練模型的訓練通常需要大量的計算資源,尤其是在大規模數據集上訓練時。模型的參數量和計算復雜度也對資源的需求產生影響。因此,選擇合適的硬件設備和優化計算資源的使用是非常關鍵的。
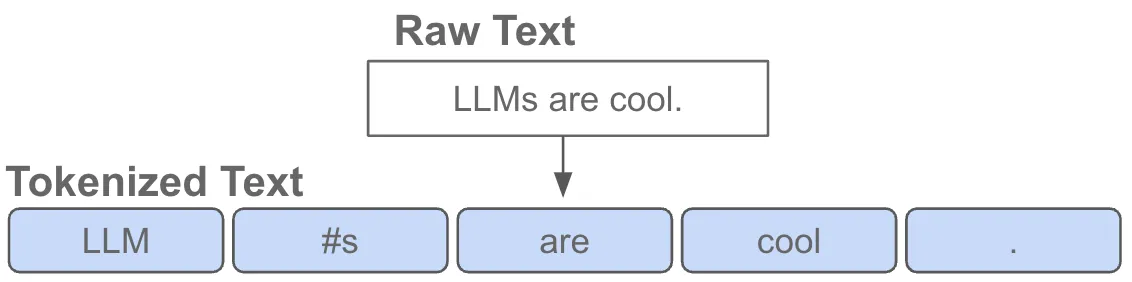
預訓練模型的優化和調參是提高模型性能的關鍵環節。常見的優化策略包括學習率的調整、梯度剪裁、正則化等。此外,模型的參數初始化和訓練策略也需要根據具體任務進行調整。
在文本分類任務中,預訓練模型可以通過微調來適應特定的分類任務。常見的文本分類任務包括情感分析、主題分類、垃圾郵件檢測等。通過微調,預訓練模型能夠更準確地捕捉文本的特征,從而提高分類的準確性。
命名實體識別是自然語言處理中一項重要的任務,旨在識別文本中的實體,如人名、地名、組織名等。預訓練模型可以通過微調來提高實體識別的準確性和召回率。
在文本生成任務中,如對話系統、故事生成等,預訓練模型通過自回歸的方式生成連貫的文本。模型通過學習大量的文本數據,能夠生成自然流暢的文本內容。
預訓練模型在自然語言處理領域的應用廣泛且效果顯著。通過不同類型的預訓練任務,模型能夠捕捉文本的深層次特征,并在多種任務中表現出色。然而,預訓練模型的訓練需要大量的數據和計算資源,因此在實際應用中需要根據具體情況進行權衡和選擇。未來,隨著技術的進步和資源的優化,預訓練模型有望在更多領域取得突破。
問:預訓練模型的優點是什么?
問:預訓練模型的缺點有哪些?
問:如何選擇合適的預訓練模型?
問:預訓練模型如何進行微調?
問:預訓練模型在實際應用中有哪些挑戰?







