
大模型RAG技術:從入門到實踐
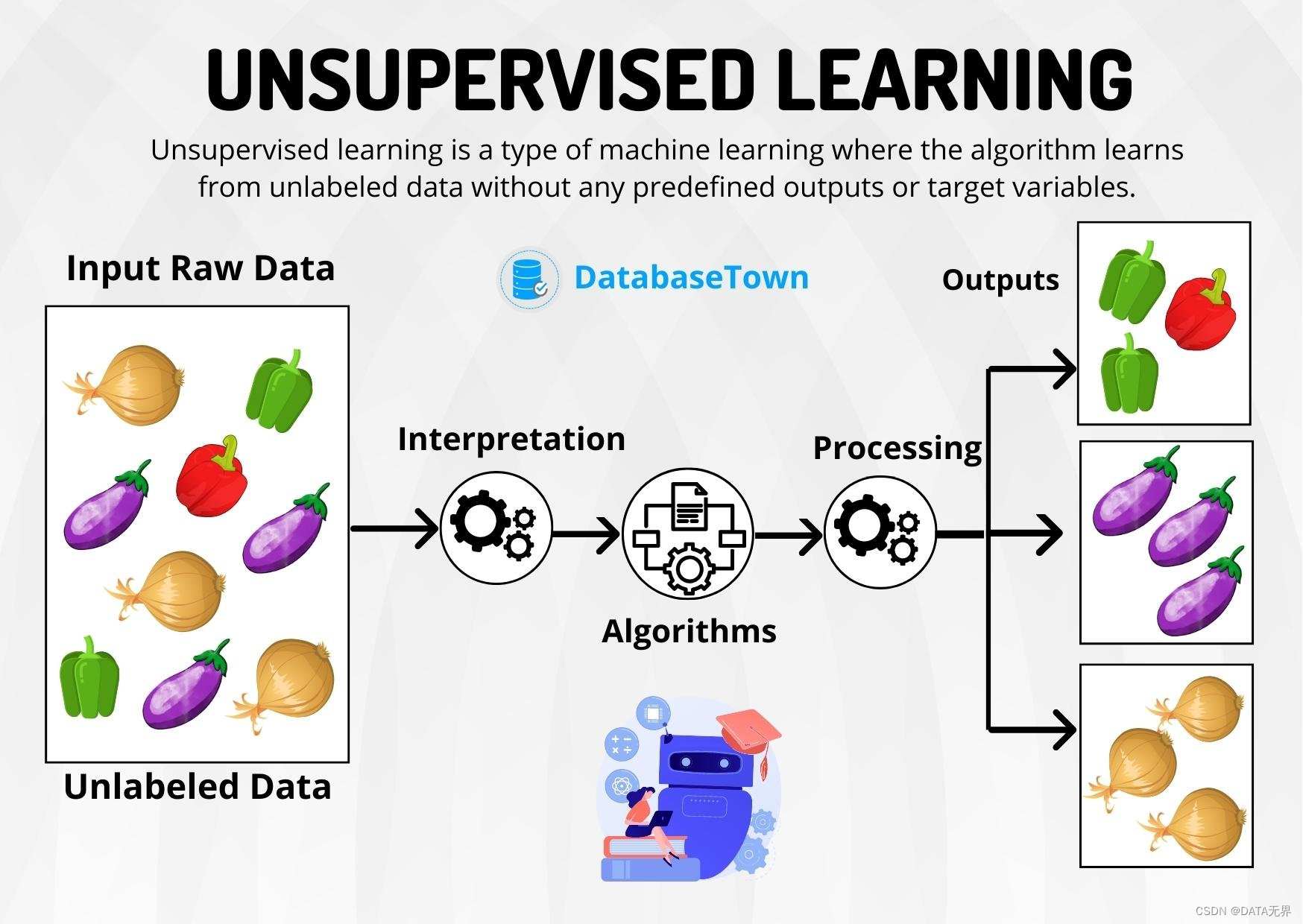
無監督學習的主要任務包括聚類、降維和密度估計。通過分析數據的統計特征,無監督學習可以自主發現隱藏的模式和結構,不依賴于人工標注的目標值。這種“自主學習”的范式使得無監督學習在許多應用場景中具有獨特的優勢。
無監督學習的核心在于通過數據的統計特征、相似度等進行分析和挖掘,然后利用密度估計、聚類和降維等技術來捕獲和發現數據隱藏的內在結構和模式。
密度估計是無監督學習中的一個基本問題,旨在估計樣本數據的概率密度函數,以刻畫數據的整體分布特征。常用的方法有核密度估計、高斯混合模型等。掌握了數據分布后,就能發現異常數據點,檢測新觀測值等。
聚類是將數據集中的樣本劃分為若干個類別的過程,使同一類別內的樣本相似度較高,不同類別之間的樣本相似度較低。常見的聚類算法包括K均值聚類、層次聚類、DBSCAN等。聚類分析有助于發現數據的內在組織結構。
降維技術通過數學上的投影等方式將高維數據映射到一個低維空間,保留數據的原始結構和特征關系,簡化后續處理。主成分分析(PCA)、t-SNE等是常用的無監督降維方法。

K-Means是最常用和最簡單的聚類算法之一。它是一種基于中心點的聚類方法,將樣本分配給最近的K個中心點所對應的簇。K-Means算法的核心步驟包括初始化中心點、分配樣本到最近的中心點所在的簇、更新中心點位置,以最小化簇內樣本間的平方和。
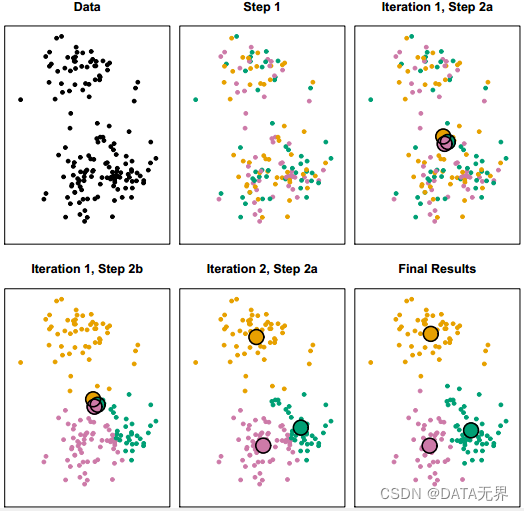
層次聚類通過逐步合并或分裂簇來構建層次化的聚類樹狀結構。主要分為凝聚層次聚類和分裂層次聚類。此算法的優勢在于不需要預先指定聚類數目,適用于小型數據集的聚類任務。
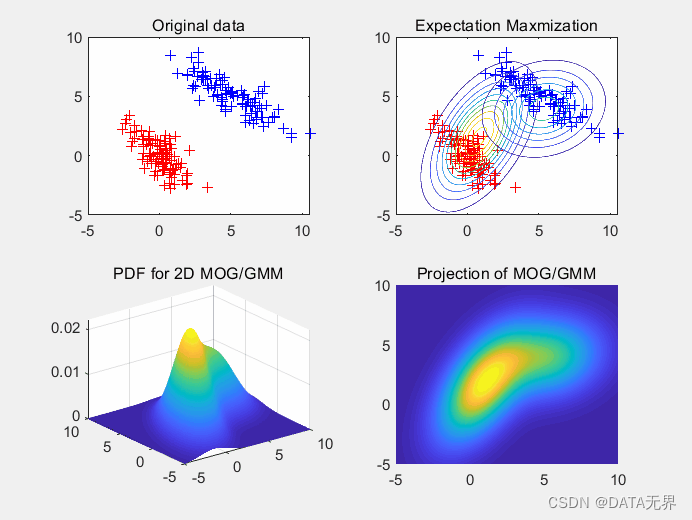
GMM假設數據服從由多個高斯分布混合而成的概率分布模型。通過期望最大化(EM)算法估計每個高斯分布的參數,廣泛應用于聚類、密度估計等任務。
下面通過一個基于Python的K-Means聚類算法實例,更直觀地理解無監督學習。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=500, centers=4, n_features=2, random_state=0)
kmeans = KMeans(n_clusters=4, random_state=0)
kmeans.fit(X)
labels = kmeans.predict(X)
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1], marker='x', c='red', s=100)
plt.title('K-Means Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()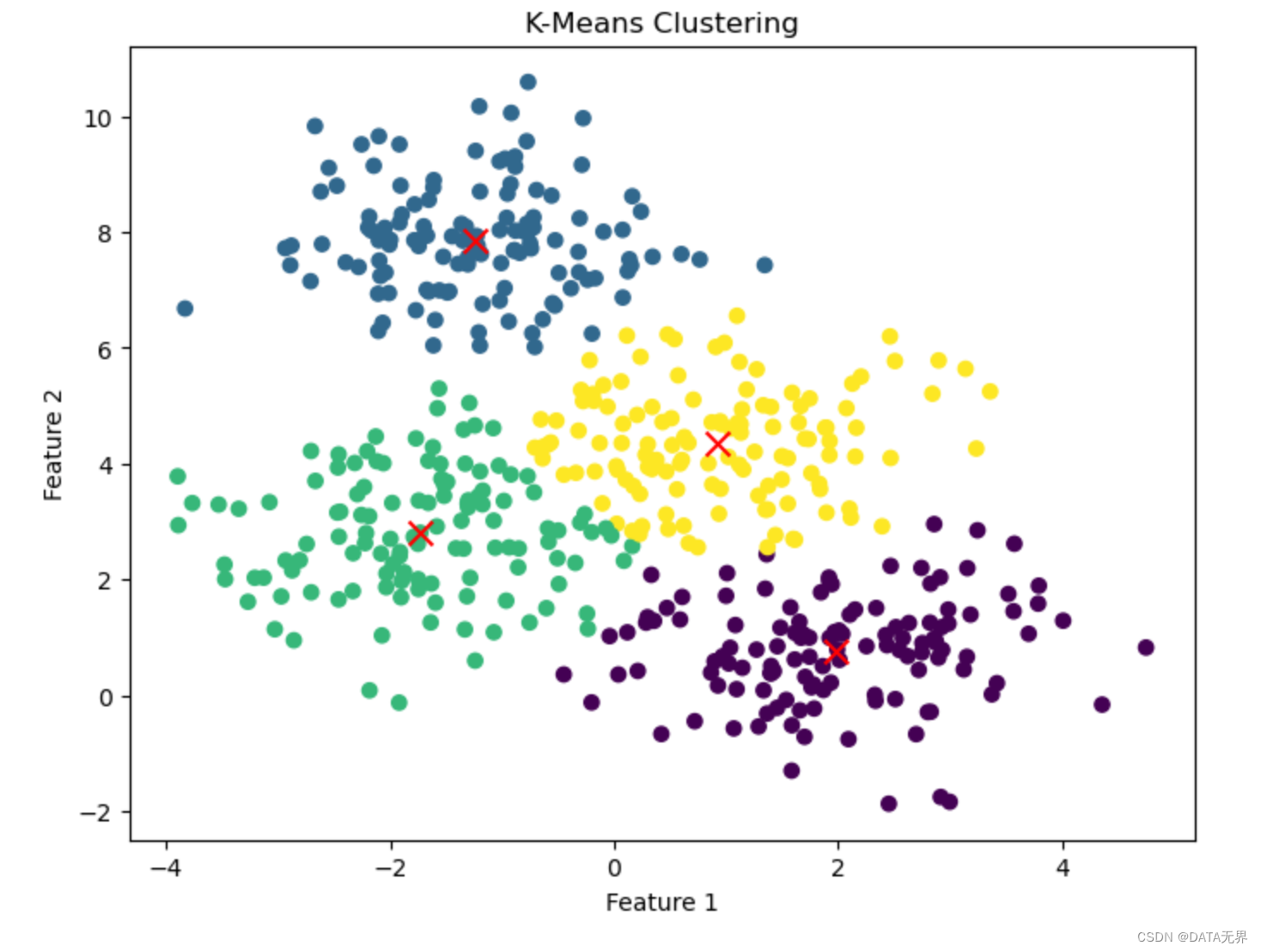
我們使用SciPy庫中的層次聚類模塊,實現一個基于Ward’s最小方差準則的聚類算法。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.cluster import AgglomerativeClustering
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
iris = load_iris()
X = iris.data
clustering = AgglomerativeClustering(n_clusters=3, linkage='ward')
clustering.fit(X)
labels = clustering.labels_
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
for label in set(labels):
data = X[labels == label]
ax.scatter(data[:, 0], data[:, 1], data[:, 2], label=f'Cluster {label+1}')
ax.legend()
ax.set_xlabel('Sepal Length')
ax.set_ylabel('Sepal Width')
ax.set_zlabel('Petal Length')
ax.set_title('Hierarchical Clustering on Iris Dataset')
ax.view_init(30, 30)
plt.show()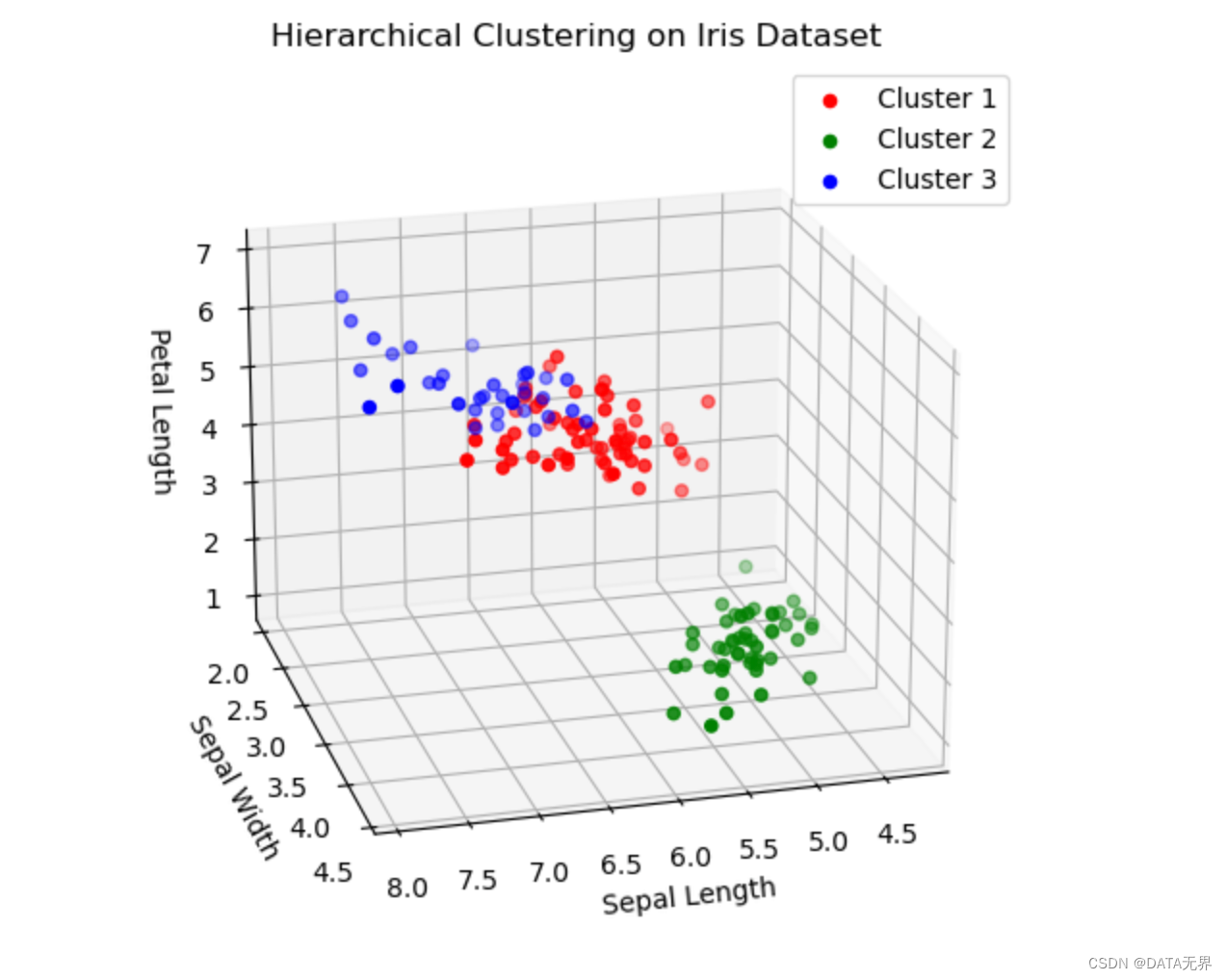
無監督學習在生物信息學、金融、網絡安全、推薦系統等領域應用廣泛。其強大的自動學習能力使其成為構建通用人工智能的關鍵技術之一。在未來,無監督學習將繼續促進數據分析和決策的智能化。
問:無監督學習與有監督學習的主要區別是什么?
問:無監督學習的典型應用場景有哪些?
問:無監督學習的主要挑戰是什么?







