
如何調(diào)用 Minimax 的 API
StreamingT2V模型的核心在于其自回歸技術(shù)框架,該框架主要由三個模塊組成:條件注意力模塊(CAM)、外觀保持模塊(APM)和隨機混合模塊。這些模塊共同作用,確保了生成視頻的時間一致性和質(zhì)量。
條件注意力模塊作為“短期記憶”,通過注意力機制從前一個視頻塊中提取特征,并注入到當前視頻塊的生成中。這種機制不僅保證了視頻塊之間的流暢過渡,還保留了視頻中的高速運動特征。例如,在生成一段蜜蜂在花叢中飛舞的視頻時,CAM能夠捕捉蜜蜂的運動軌跡并將其自然地連接在一起。
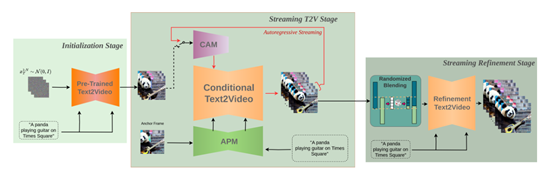
外觀保持模塊則作為“長期記憶”,從初始圖像(錨定幀)中提取全局場景和對象特征。這些特征貫穿于所有視頻塊的生成流程中,確保生成視頻的全局場景和外觀一致性。例如,在生成一段長時間的風景視頻時,APM可以確保山川、河流等元素在整個視頻中的位置和形態(tài)保持一致。

隨機混合模塊進一步優(yōu)化了視頻的分辨率和時間連貫性。通過自回歸增強的方法,隨機混合模塊能夠有效地提高視頻的清晰度,并使視頻塊之間的過渡更加自然。實驗表明,這種方法在生成高分辨率長視頻時表現(xiàn)尤為出色。

StreamingT2V模型在多個領(lǐng)域展現(xiàn)出了廣泛的應用潛力。在娛樂和創(chuàng)意內(nèi)容生成方面,StreamingT2V能夠輕松生成各種風格的視頻作品,滿足用戶多樣化的需求。同時,在教育、培訓和模擬等領(lǐng)域,StreamingT2V通過生成逼真的教學視頻和模擬場景,為學習者提供更加直觀、生動的體驗。

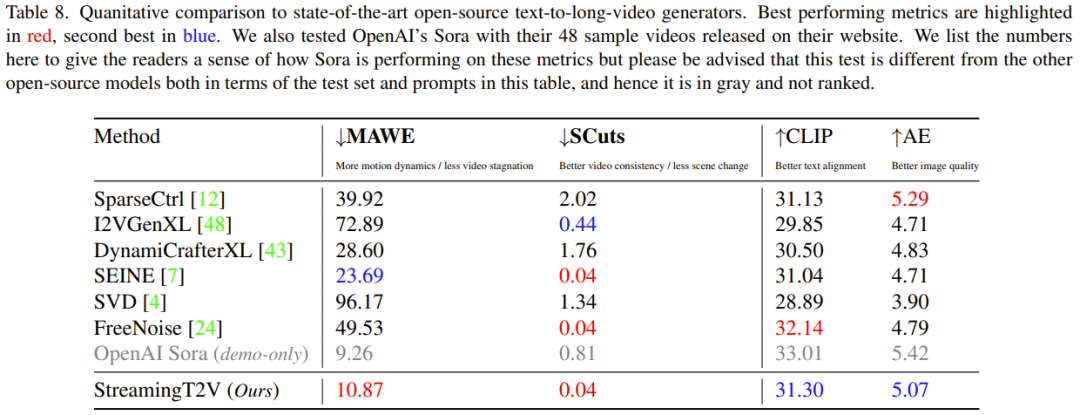
在實驗階段,研究團隊使用了多種評估指標來驗證StreamingT2V的性能。這些指標包括時間一致性的SCuts分數(shù)、運動感知扭變誤差(MAWE)、文本圖像相似度分數(shù)(CLIP)以及美學分數(shù)(AE)。結(jié)果顯示,StreamingT2V在視頻質(zhì)量、時間一致性和文本對齊方面均優(yōu)于現(xiàn)有的基線模型。

通過與其他視頻生成模型的對比研究,StreamingT2V在無縫視頻塊過渡和運動一致性方面表現(xiàn)最佳。與使用自回歸方法的圖像到視頻方法如I2VGen-XL、SVD、DynamiCrafter-XL等模型相比,StreamingT2V的綜合性能更為出色。
盡管StreamingT2V已經(jīng)在長視頻生成領(lǐng)域取得了顯著的進展,但在視頻質(zhì)量和多元化方面仍有提升空間。隨著技術(shù)的不斷進步和其他AI視頻生成模型的競爭,StreamingT2V需要不斷創(chuàng)新和升級,以保持其在市場中的領(lǐng)先地位。

StreamingT2V的推出標志著AI視頻生成技術(shù)進入了一個新的發(fā)展階段。通過其創(chuàng)新的自回歸框架,StreamingT2V不僅實現(xiàn)了高質(zhì)量長視頻的生成,還為視頻生成技術(shù)的研究和應用開發(fā)提供了堅實的基礎。隨著這一技術(shù)的不斷迭代,AI生成的視頻將逐漸滲透到我們的日常生活中,為我們帶來更加豐富多彩的視覺體驗。
問:StreamingT2V的核心技術(shù)是什么?
問:StreamingT2V在實際應用中有哪些優(yōu)勢?
問:如何評估StreamingT2V的性能?
問:StreamingT2V與其他視頻生成模型相比有哪些優(yōu)勢?
問:未來StreamingT2V的發(fā)展方向是什么?





