
AI視頻剪輯工具:解鎖創作的無限可能
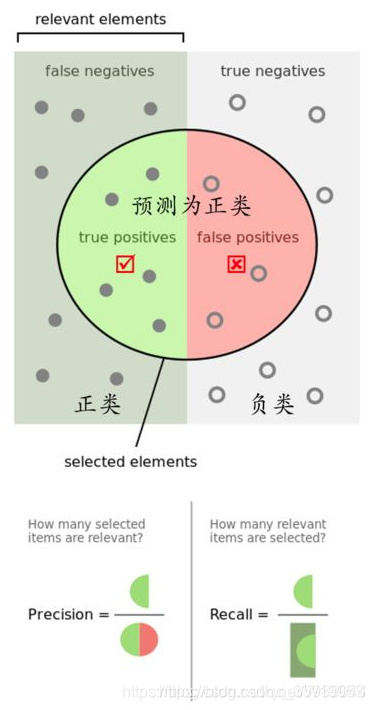
召回率的計算公式為:
Recall = frac{TP}{TP+FN}其中,TP表示真正例(True Positive),FN表示假負例(False Negative)。
召回率廣泛應用于需要高覆蓋率的場景,如欺詐檢測、醫療診斷等。在這些領域,漏檢的代價極高,因此召回率成為一個關鍵的評估指標。
精確率(Precision)是另一個重要的性能指標,它衡量的是預測為正樣本中實際為正樣本的比例。精確率和召回率之間往往存在權衡關系:提高召回率可能會降低精確率,反之亦然。
在實際應用中,需要根據具體情況平衡精確率和召回率。例如,在某些場景下,我們可能更傾向于減少漏檢(提高召回率),即使這會犧牲一定的精確率。
F值是精確率和召回率的調和平均,它提供了一個綜合考慮兩者的評估指標。F值的計算公式為:
F_beta = (1 + beta^2) times frac{PR}{beta^2P + R}其中,P表示精確率,R表示召回率,(beta)是調節兩者權重的參數。
當(beta=1)時,F值稱為F1分數,它是精確率和召回率的等權重調和平均,特別適用于兩者都需要平衡的場景。
ROC曲線是一個重要的工具,用于展示模型在不同閾值下的真正率和假正率。AUC(Area Under Curve)是ROC曲線下的面積,它提供了一個衡量模型整體性能的指標。
AUC值越接近1,表示模型的分類性能越好。AUC值為0.5時,表示模型性能等同于隨機猜測。
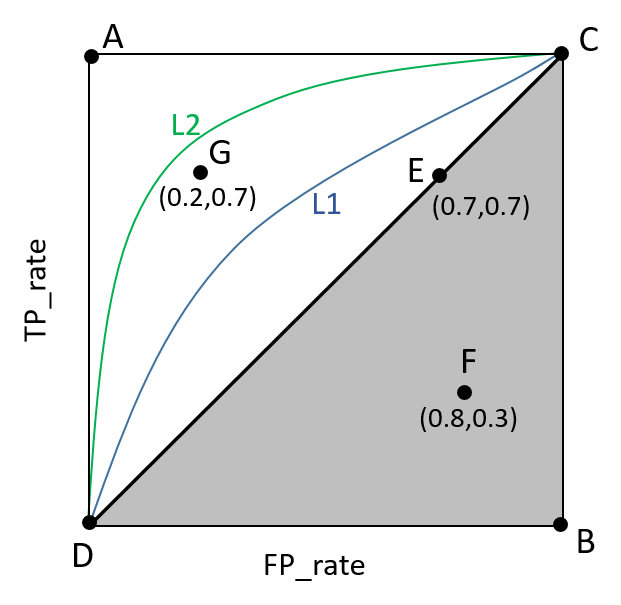
PR曲線是另一個重要的工具,它專注于當樣本不平衡時模型的性能評估。PR曲線下的AUC值同樣可以用來衡量模型的性能。
PR曲線以召回率為X軸,精確率為Y軸,曲線越靠近右上角,表示模型性能越好。
在實際應用中,召回率模型需要結合具體的業務場景進行優化和調整。例如,在推薦系統中,高召回率可能意味著更多的相關推薦,但也可能帶來信息過載的問題。
優化召回率模型通常涉及到特征工程、樣本平衡、模型選擇等多個方面。通過不斷的迭代和測試,可以找到最適合特定場景的模型配置。
召回率模型的業務價值體現在其能夠減少關鍵信息的遺漏,提高業務流程的效率和效果。在金融風控、醫療健康等領域,召回率模型的應用可以帶來顯著的經濟和社會效益。
問:召回率和精確率有什么區別?
答:召回率關注的是模型找出所有正樣本的能力,而精確率關注的是模型預測為正樣本中實際為正樣本的比例。兩者在實際應用中往往需要平衡。
問:F1分數如何在精確率和召回率之間取得平衡?
答:F1分數是精確率和召回率的調和平均,當(beta=1)時,F1分數給予兩者相等的權重,適用于兩者都需要平衡的場景。
問:如何提高召回率模型的性能?
答:提高召回率模型的性能可以通過特征工程、樣本平衡、模型選擇等方法。實際應用中,需要根據業務場景進行不斷的優化和調整。
問:召回率模型在哪些領域有重要應用?
答:召回率模型在金融風控、醫療健康、推薦系統等領域有重要應用,它能夠減少關鍵信息的遺漏,提高業務流程的效率和效果。
問:召回率模型的業務價值是什么?
答:召回率模型的業務價值體現在其能夠減少關鍵信息的遺漏,提高業務流程的效率和效果,帶來顯著的經濟和社會效益。






