隨機森林的特點
高準確率
隨機森林算法以其高準確率而聞名,特別是在處理復雜數據集時,能夠有效地捕捉數據中的模式和特征。
處理高維數據
它能夠處理具有高維特征的數據集,而無需降維,這使得它在大數據分析中非常有用。
抗噪能力強
隨機森林對于數據中的噪聲和缺失值具有很好的魯棒性,能夠在不完美的數據環境中提供可靠的預測。
隨機森林的相關基礎知識
信息增益與熵
在構建決策樹時,信息增益和熵是兩個重要的概念。信息增益用于選擇最佳分裂特征,而熵則用于度量數據的不確定性。
決策樹的構建
決策樹是一種以特征為節點的樹形結構,每個節點代表一個特征測試。常用的算法包括C4.5、ID3和CART。
集成學習
集成學習是通過組合多個學習模型來解決單一預測問題的方法。隨機森林就是集成學習的一種典型應用。

隨機森林的生成
樹的生成過程
隨機森林中的每棵樹是通過從訓練集隨機抽樣生成的。這種方法稱為Bootstrap采樣,即有放回地從訓練集中抽取樣本。
特征選擇
在每個樹節點分裂時,隨機選擇一部分特征來進行判斷,確保每棵樹的多樣性和獨立性。
樹的投票機制
每棵樹獨立地對輸入樣本進行分類,最終的分類結果由所有樹的投票結果決定,確保模型的穩定性。

袋外錯誤率(oob error)
袋外樣本的概念
在構建每棵樹時,約有1/3的訓練實例未被抽樣,這部分樣本稱為袋外樣本(OOB)。
袋外誤差的計算
通過對OOB樣本進行分類,計算它們的誤分類率,以此作為隨機森林的誤差估計。
OOB誤差的優點
OOB誤差提供了一種無需交叉驗證的模型評價方法,能夠快速評估隨機森林的泛化能力。
隨機森林工作原理解釋的一個簡單例子
實例描述
假設我們要預測某個人的收入層次,可以通過年齡、性別、教育程度等特征來進行預測。
CART樹的應用
每棵CART樹根據不同的特征進行分類,例如根據年齡或行業對收入進行分類。
投票結果
通過5棵CART樹的投票結果,得出最終的收入層次預測。多數投票的結果作為最終的預測輸出。
隨機森林的Python實現
使用Scikit-learn庫
Python中可以使用Scikit-learn庫來實現隨機森林。以下是一個簡單的示例代碼。
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
train, test = df[df['is_train']], df[~df['is_train']]
features = df.columns[:4]
clf = RandomForestClassifier(n_jobs=2, random_state=0)
y, _ = pd.factorize(train['species'])
clf.fit(train[features], y)
preds = iris.target_names[clf.predict(test[features])]
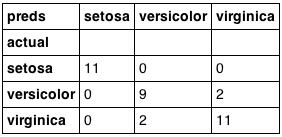
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds'])
模型訓練與預測
在代碼中,我們首先加載Iris數據集,然后使用隨機森林算法進行訓練,并對測試集進行預測。
結果分析
最后,通過交叉表比較真實標簽和預測結果,評估模型性能。
FAQ
問:隨機森林算法的基本概念是什么?
- 答:隨機森林算法是一種由多棵決策樹組成的集成算法,通過對多個決策樹的結果進行投票來做出分類決策。它廣泛應用于分類和回歸問題中,具有出色的性能和靈活性。
問:隨機森林算法如何解決決策樹容易過擬合的問題?
- 答:單一的決策樹容易過擬合,而隨機森林通過集成多棵樹,減少了過擬合的風險。每棵樹的生成過程是相互獨立的,這提高了模型的穩定性并增強了泛化能力。
問:隨機森林算法有哪些顯著的特點?
- 答:隨機森林算法具有高準確率、能夠處理高維數據、抗噪能力強等特點。它在處理復雜數據集時表現優異,能夠有效捕捉數據中的模式和特征,同時對數據中的噪聲和缺失值具有很好的魯棒性。
問:什么是袋外錯誤率(OOB Error)?
- 答:袋外錯誤率是通過袋外樣本(在構建每棵樹時未被抽樣的約1/3的訓練實例)進行分類后,計算它們的誤分類率,以此作為隨機森林的誤差估計。這種方法無需交叉驗證,能夠快速評估模型的泛化能力。
問:如何用Python實現隨機森林算法?
- 答:可以使用Python中的Scikit-learn庫來實現隨機森林。首先加載數據集,例如Iris數據集,然后使用
RandomForestClassifier進行訓練和預測。通過交叉表比較真實標簽和預測結果來評估模型性能。
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業工程師共享工作效率翻倍的秘密
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
一区在线观看免费|
国产午夜精品一区二区三区嫩草|
韩日欧美一区二区三区|
91久久久免费一区二区|
国产精品电影院|
懂色一区二区三区免费观看|
国产丝袜欧美中文另类|
高清在线不卡av|
国产精品国产三级国产aⅴ入口|
国内成+人亚洲+欧美+综合在线|
欧美日韩一级二级三级|
日韩激情中文字幕|
欧美成人国产一区二区|
粉嫩高潮美女一区二区三区|
国产精品精品国产色婷婷|
成人精品视频.|
香蕉乱码成人久久天堂爱免费|
日韩欧美第一区|
国产成人综合亚洲91猫咪|
国产精品福利一区二区三区|
欧美在线视频全部完|
日本欧美在线看|
国产亚洲美州欧州综合国|
色综合久久久久|
美女脱光内衣内裤视频久久影院|
国产亚洲污的网站|
欧美日韩精品二区第二页|
国产精品一级二级三级|
亚洲精品欧美二区三区中文字幕|
日韩欧美亚洲国产精品字幕久久久|
99免费精品视频|
久久精品国产一区二区三|
欧美国产欧美综合|
欧美一区二区三区免费大片|
91网站最新网址|
精久久久久久久久久久|
亚洲一二三专区|
国产日本欧美一区二区|
欧美一区二区三区播放老司机|
国产不卡一区视频|
美女在线一区二区|
午夜亚洲福利老司机|
成人免费小视频|
国产精品久久久久久福利一牛影视|
777久久久精品|
在线观看亚洲专区|
91在线国产福利|
www.成人在线|
av亚洲精华国产精华|
成人激情综合网站|
国产白丝网站精品污在线入口|
激情文学综合丁香|
国产精品一区免费在线观看|
蜜桃视频免费观看一区|
蜜臀av一区二区在线免费观看|
亚洲综合一区在线|
亚洲一区欧美一区|
五月天婷婷综合|
免费人成网站在线观看欧美高清|
蜜臀av性久久久久蜜臀aⅴ
|
91黄色免费版|
在线91免费看|
精品久久久久久亚洲综合网
|
水野朝阳av一区二区三区|
天天综合日日夜夜精品|
麻豆91免费观看|
激情综合亚洲精品|
av激情成人网|
欧美揉bbbbb揉bbbbb|
欧美精品丝袜中出|
26uuu欧美日本|
日韩伦理av电影|
日韩精品乱码免费|
国产乱码精品一品二品|
91性感美女视频|
日韩欧美国产不卡|
国产精品久久久久久久久果冻传媒|
亚洲综合视频在线|
国产麻豆精品95视频|
色婷婷亚洲一区二区三区|
欧美一区二区久久久|
中文字幕中文在线不卡住|
午夜av一区二区|
丁香亚洲综合激情啪啪综合|
欧美日韩免费视频|
国产亚洲精品7777|
水野朝阳av一区二区三区|
国产不卡一区视频|
717成人午夜免费福利电影|
中文字幕av免费专区久久|
亚洲成人av在线电影|
国产成人精品亚洲日本在线桃色|
欧美视频日韩视频|
国产精品成人免费|
国产一区二区伦理|
欧美精品乱码久久久久久|
亚洲精品欧美综合四区|
国产成都精品91一区二区三|
欧美日韩国产三级|
亚洲久本草在线中文字幕|
国产成人免费在线观看|
26uuu久久天堂性欧美|
午夜精品一区在线观看|
91久久国产最好的精华液|
亚洲国产精品成人综合|
国产一区在线观看麻豆|
日韩午夜激情av|
日本不卡不码高清免费观看|
欧美日韩一级黄|
亚洲图片欧美色图|
欧美日韩在线免费视频|
亚洲成a人v欧美综合天堂|
欧美伊人久久大香线蕉综合69
|
国产精品久久一卡二卡|
国产成人精品亚洲日本在线桃色
|
一区二区国产视频|
在线免费视频一区二区|
亚洲狠狠爱一区二区三区|
欧美日韩一区中文字幕|
午夜精品爽啪视频|
日韩欧美二区三区|
成人一级视频在线观看|
中文字幕一区二区三区乱码在线|
99久久婷婷国产综合精品电影|
国产精品久久久久影院老司
|
波多野结衣91|
中文字幕在线一区|
欧美日韩午夜在线|
激情欧美一区二区|
中文字幕在线一区二区三区|
91老师国产黑色丝袜在线|
亚洲制服丝袜av|
日韩精品资源二区在线|
成人激情动漫在线观看|
亚洲高清视频中文字幕|
精品国产人成亚洲区|
eeuss影院一区二区三区|
亚洲一区影音先锋|
国产亚洲一区字幕|
色狠狠色狠狠综合|
精品一区二区三区香蕉蜜桃|
国产精品国产三级国产普通话99|
欧洲在线/亚洲|
国产激情精品久久久第一区二区
|
亚洲精品一区二区三区精华液
|
一本大道av伊人久久综合|
美国三级日本三级久久99|
亚洲欧美在线高清|
在线91免费看|
日本韩国精品一区二区在线观看|
久久97超碰色|
婷婷开心激情综合|
一区二区免费视频|
国产精品久久久久久久久动漫|
91精品啪在线观看国产60岁|
91老师国产黑色丝袜在线|
国产综合一区二区|
蜜桃一区二区三区在线|
亚洲福利视频导航|
亚洲欧洲日韩av|
亚洲国产高清在线|
久久久久亚洲蜜桃|
欧美精品一区视频|
欧美高清性hdvideosex|
欧美亚洲动漫精品|
在线视频中文字幕一区二区|
波波电影院一区二区三区|
国产麻豆视频一区二区|
美腿丝袜在线亚洲一区|
日产国产高清一区二区三区|
午夜久久电影网|
婷婷国产v国产偷v亚洲高清|
亚洲高清在线精品|
婷婷综合另类小说色区|
亚洲国产欧美在线人成|
午夜精品在线看|
久久超碰97中文字幕|
国产综合色在线|
国产在线一区观看|
成人小视频免费观看|
国产不卡在线一区|
国产成人三级在线观看|
成人黄动漫网站免费app|
成人爱爱电影网址|
色吊一区二区三区|
制服丝袜激情欧洲亚洲|
亚洲精品在线免费观看视频|
久久久精品欧美丰满|
国产日韩欧美一区二区三区综合|
中文av字幕一区|
亚洲一级二级三级|
久久机这里只有精品|
成人免费视频国产在线观看|
99热99精品|
日韩欧美中文字幕制服|
久久久久久99精品|
亚洲自拍偷拍九九九|
国产一区欧美二区|
欧洲色大大久久|
欧美成人bangbros|