
豆包 Doubao Image API 價格全面解析
Qwen2.5-Coder 利用超過 5.5 萬億個 token 的編程相關數據進行訓練,這些數據涵蓋了多種源代碼、文本-代碼關聯數據和合成數據。這種大規模的數據使得模型能夠從中學習到豐富的編程知識和模式,為開發者提供精確的代碼建議。
該模型支持多達 92 種編程語言,能夠在不同編程語言之間切換自如。這為開發者提供了極大的靈活性和方便性,尤其是在多語言項目中。
Qwen2.5-Coder 的上下文處理能力可達 128K tokens,這使得它能夠處理大規模的代碼文本和復雜的編程邏輯。這種能力尤其適合大型項目和復雜代碼庫的處理。
模型提供了多種參數規模的版本,包括 1.5B、7B 和即將推出的 32B 版本,以滿足不同用戶和應用場景的需求。
Qwen2.5-Coder 可以根據特定需求生成完整的代碼,同時支持代碼補全功能。例如,在開發過程中,開發者只需輸入部分代碼,模型便可自動補全剩余部分,極大提高了開發效率。
模型不僅可以生成代碼,還能修復代碼中的錯誤。例如,當冒泡排序算法出現錯誤時,Qwen2.5-Coder 可以自動發現并修正錯誤,使得代碼能夠正常運行。
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
def bubble_sort(nums):
n = len(nums)
for i in range(n):
for j in range(0, n-i-1):
if nums[j] < nums[j+1]:
nums[j], nums[j+1] = nums[j+1], nums[j]
return nums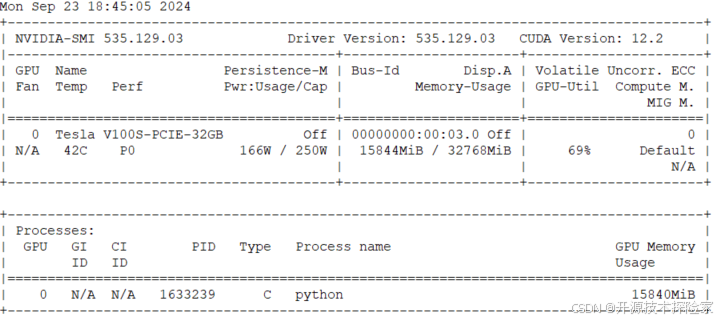
Qwen2.5-Coder 的安裝需要一定的硬件支持,推薦的操作系統是 CentOS 7,GPU 需要支持 CUDA 12.2 版本,例如 Tesla V100-SXM2-32GB。
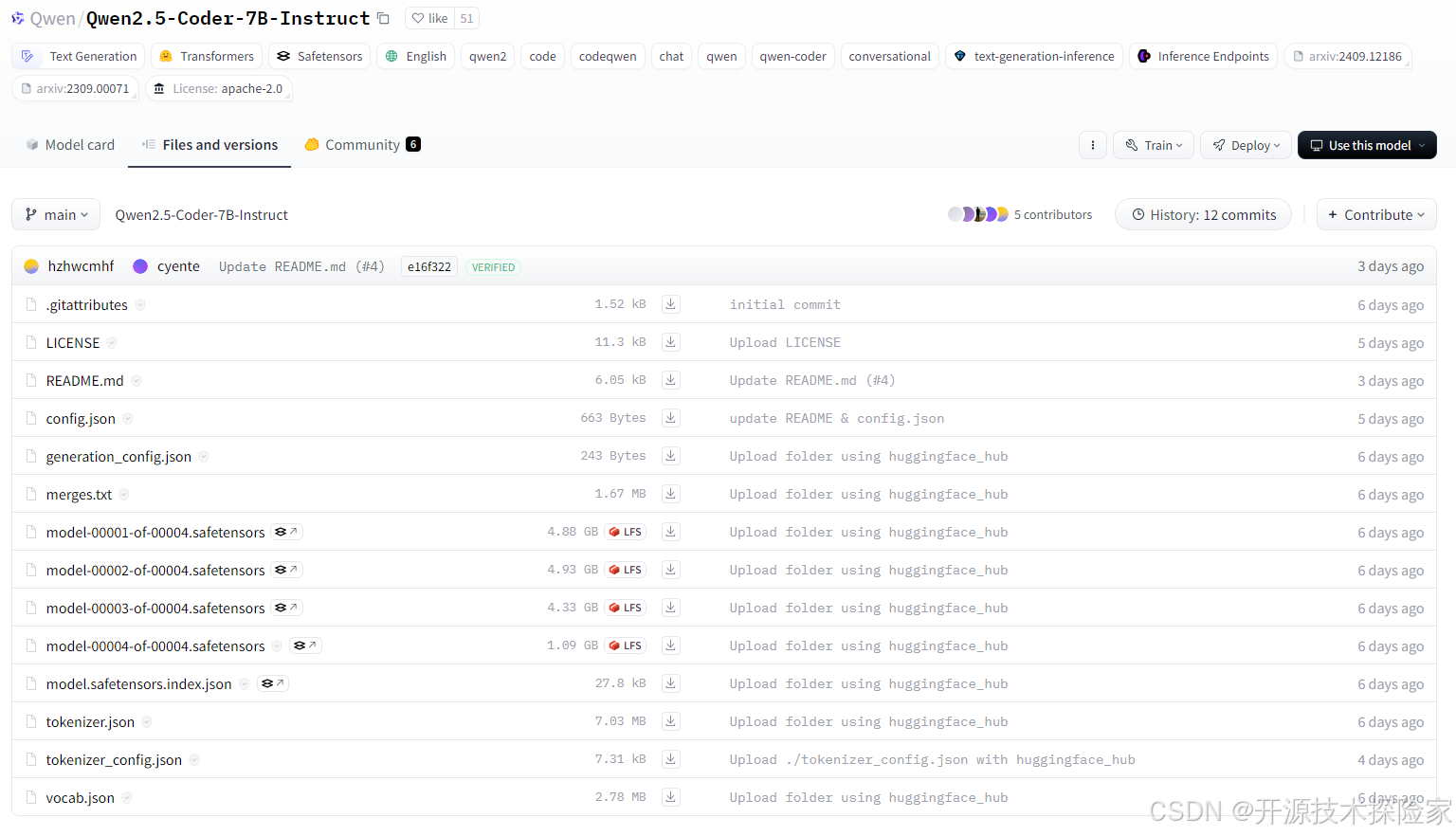
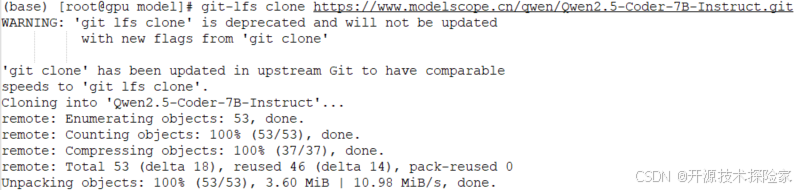
模型的下載可以通過 Hugging Face 平臺進行,用戶可以根據實際需求選擇不同的模型規格。
git clone https://www.modelscope.cn/qwen/Qwen2.5-Coder-7B-Instruct.git安裝完成后,通過以下命令激活虛擬環境并安裝依賴庫:
conda create --name qwen2.5 python=3.10
conda activate qwen2.5
pip install transformers torch accelerateQwen2.5-Coder 可以根據用戶輸入的提示生成代碼,以下是使用該模型生成 Python 冒泡排序算法的示例:
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
def loadTokenizer():
tokenizer = AutoTokenizer.from_pretrained('/data/model/qwen2.5-coder-7b-instruct')
return tokenizer
def loadModel(config):
model = AutoModelForCausalLM.from_pretrained(
'/data/model/qwen2.5-coder-7b-instruct',
torch_dtype="auto",
device_map="auto"
)
model.generation_config = config
return model模型不僅可以生成代碼,還能修復代碼中的錯誤。例如,當冒泡排序算法出現錯誤時,Qwen2.5-Coder 可以自動發現并修正錯誤,使得代碼能夠正常運行。
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
def bubble_sort(nums):
n = len(nums)
for i in range(n):
for j in range(0, n-i-1):
if nums[j] < nums[j+1]:
nums[j], nums[j+1] = nums[j+1], nums[j]
return nums
隨著人工智能技術的不斷進步,Qwen2.5-Coder 的應用前景將更加廣闊。未來,模型將不斷優化和升級,以適應更為復雜的編程任務和應用場景。
答:Qwen2.5-Coder 支持多達 92 種編程語言,包括 Python、Java、C++、JavaScript 等主流編程語言。
答:您可以通過 Hugging Face 或 ModelScope 下載模型,并在符合要求的硬件環境下安裝和運行。
答:Qwen2.5-Coder 主要提供代碼生成、補全、修復等功能,能夠在多種編程任務中提供幫助。
答:該模型適用于軟件開發、代碼審核、編程教學等多個領域,能夠顯著提升開發效率和代碼質量。
答:這意味著 Qwen2.5-Coder 可以處理較長的代碼輸入,支持高達 128K tokens 的上下文長度,有助于處理大型代碼庫和復雜邏輯。





