
數據庫表關聯:構建高效數據結構的關鍵
RAG的核心流程包括文本分割、向量化、索引創建及上下文提示生成。首先,將文本分割成塊,然后使用基于Transformer的Decoder模型將這些塊嵌入為向量,并存入索引。隨后,LLM使用這些索引中的上下文來回答查詢。
文本切分是RAG的基礎步驟之一。由于Transformer模型有固定的輸入序列長度,文本切分可以確保每個塊能夠被模型有效處理。選擇合適的模型進行向量化,如bge-large或E5等搜索優化模型,是向量化過程的關鍵。
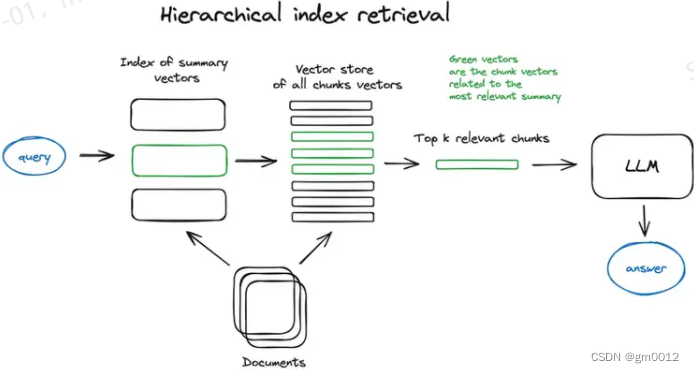
RAG中的索引存儲來自向量化步驟的內容。最簡單的方法是使用平面索引計算查詢向量與所有塊向量之間的距離。對于大型數據庫,分層索引通過創建摘要和文檔塊兩個索引,實現高效的信息檢索。
為了提升搜索質量,RAG使用上下文豐富化技術。通過擴展檢索到的句子前后的上下文窗口,或將文檔遞歸地分割為多個子塊,LLM能夠進行更深入的推理。
句子窗口檢索通過分別嵌入每個句子,實現了高精度的查詢與上下文余弦距離搜索。自動合并檢索器(父文檔檢索器)在找到與查詢最相關的塊后,會自動將這些子塊與更大的父塊結合,為LLM提供更豐富的上下文。

RAG的實現通常涉及復雜的代碼邏輯。以下是一個簡單的Python代碼示例,用于展示如何使用Transformer模型進行文本塊的嵌入:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("model_name")
model = AutoModel.from_pretrained("model_name")
text = "這是一個示例文本塊。"
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
vector = outputs.last_hidden_state.mean(dim=1)RAG技術通過結合檢索和生成,極大地提升了模型在復雜查詢下的應答能力。其核心在于如何高效地管理和利用上下文信息,以提供更精準的答案。
問:RAG能處理多模態數據嗎?
問:RAG的優勢是什么?
問:如何選擇合適的嵌入模型進行向量化?
通過對RAG技術的深入理解,可以幫助我們更好地應用這一技術,并為復雜的查詢提供有效的解決方案。




