
ChatGPT API 申請與使用全攻略

Image Source: unsplash
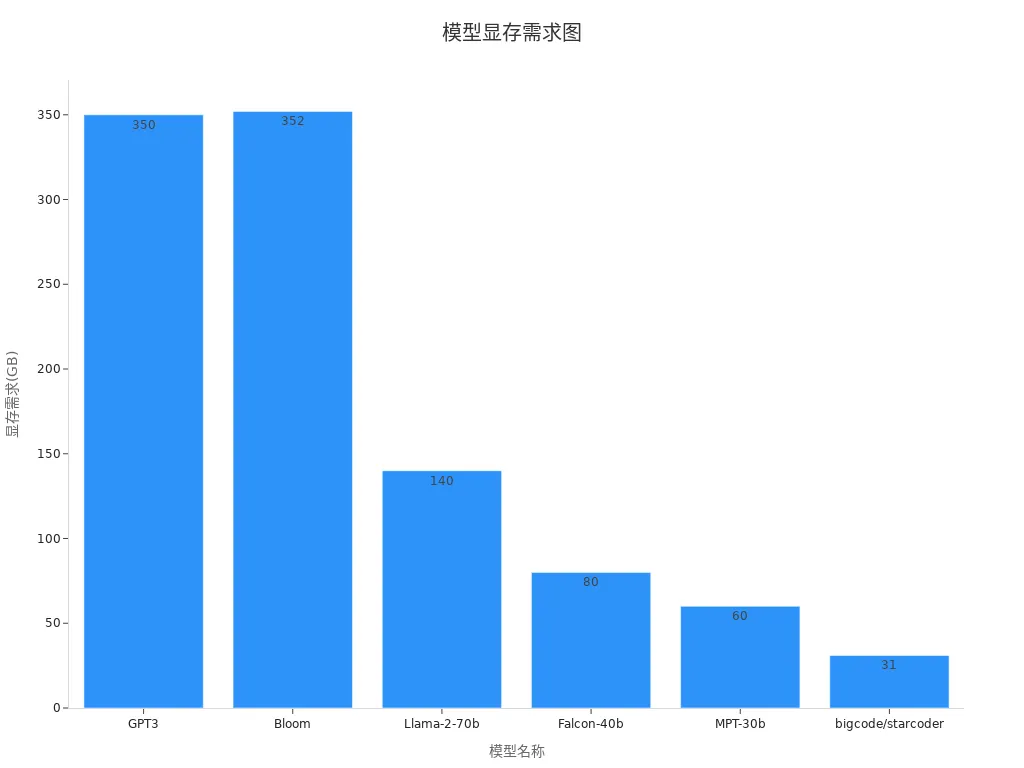
在使用Ollama接口生成文本之前,你需要先加載一個適合的模型。Ollama接口支持多種主流大語言模型,包括GPT3、Llama-2-70b等。選擇模型時,應根據任務需求和硬件資源進行權衡。例如,生成復雜內容時可以選擇性能更強的模型,而在資源有限的情況下,可以選擇占用顯存較少的模型。以下是一些常見模型的顯存需求:
| 模型名稱 | 顯存需求 |
|---|---|
| GPT3 | 350 GB |
| Bloom | 352 GB |
| Llama-2-70b | 140 GB |
| Falcon-40b | 80 GB |
| MPT-30b | 60 GB |
| bigcode/starcoder | 31 GB |
選擇模型后,可以通過以下命令加載模型:
ollama load --model llama-2-70b加載完成后,系統會提示模型已準備就緒。
以下是一個加載模型的Python代碼示例:
import ollama
# 初始化Ollama客戶端
client = ollama.Client(api_key="your_api_key")
# 加載模型
client.load_model("llama-2-70b")
print("模型加載完成!")加載模型后,你可以通過發送POST請求生成文本。請求格式包括以下參數:
prompt:輸入的文本提示,決定生成內容的主題。
max_tokens:生成文本的最大長度,默認值為256。
temperature:控制生成文本的隨機性,值越高,生成內容越多樣化。
以下是一個發送文本生成請求的Python代碼示例:
response = client.generate(
prompt="請寫一篇關于人工智能的短文",
max_tokens=150,
temperature=0.7
)
print(response["text"])生成文本時,參數設置會直接影響結果:
溫度(temperature):控制生成內容的隨機性。較低的值(如0.2)會生成更保守的內容,較高的值(如0.8)會生成更有創意的內容。
最大長度(max_tokens):限制生成文本的長度,避免生成過長或無關的內容。
為了獲得最佳效果,你可以嘗試以下優化技巧:
根據任務調整溫度:創意寫作時,設置溫度為0.7-0.9;生成技術文檔時,設置為0.2-0.4。
逐步調整參數:從默認值開始,逐步調整溫度和最大長度,觀察生成結果的變化。
結合高性能服務:Ollama接口與HAI服務結合使用,可以顯著提升文本生成的效率和質量。
> 提示:Ollama接口提供靈活且高效的本地大模型管理方式,適用于自動化內容生成和智能對話系統的構建。
多輪對話的核心在于管理會話上下文。Ollama接口通過記錄用戶與智能體的交互歷史,確保對話的連貫性。會話歷史通常以以下兩種格式存儲:
完整記錄:如(u0, a0, · · · , uk, ak),表示用戶與智能體的完整交互軌跡。
推理優化:如(u0, ar, ur+1, · · · , uk),僅保留關鍵上下文,省略多余消息,確保輸入token數量不超過3500。
此外,LangChain的存儲模塊可將對話歷史嵌入到語言模型中。通過ConversationBufferMemory,你可以保存聊天記錄并將其與新問題一起傳遞給模型。這種方法顯著提升了上下文的連續性和對話的智能性。
以下是一個實現多輪對話的Python代碼示例:
from ollama import Client
from langchain.memory import ConversationBufferMemory
# 初始化客戶端和內存
client = Client(api_key="your_api_key")
memory = ConversationBufferMemory()
# 模擬多輪對話
memory.save_context({"user": "你好"}, {"bot": "你好!有什么可以幫您?"})
memory.save_context({"user": "幫我寫一篇關于AI的文章"}, {"bot": "好的,請稍等。"})
# 將歷史記錄傳遞給模型
response = client.generate(
prompt=memory.load_memory_variables({})["history"] + "請繼續對話。",
max_tokens=150
)
print(response["text"])流式響應允許你實時接收生成的文本,而無需等待完整結果。這種方式在以下場景中尤為有用:
實時交互:如聊天機器人或語音助手,用戶可即時獲取反饋。
長文本生成:如報告或文章,流式響應減少等待時間,提升用戶體驗。
通過流式響應,Ollama接口能夠更高效地處理復雜任務,尤其是在需要快速響應的應用中。
實現流式響應需要啟用流模式,并逐步接收生成結果。以下是一個實現流式響應的代碼示例:
response = client.generate_stream(
prompt="請寫一篇關于機器學習的短文",
max_tokens=200
)
# 實時輸出生成內容
for chunk in response:
print(chunk["text"], end="")這種方法不僅提升了響應速度,還能讓用戶在生成過程中實時查看內容。

Image Source: pexels
在內容創作中,Ollama接口能夠幫助你快速生成高質量的博客文章和廣告文案。通過輸入簡單的提示詞,你可以獲得結構清晰、語言流暢的文本內容。無論是撰寫技術博客還是創意文案,Ollama接口都能顯著提升效率。
以下是Ollama接口在內容創作中的具體表現:
| 功能 | 描述 |
|---|---|
| 低重復率 | 所生成的綜述普通重復率與AIGC重復率均在5%以下。 |
| 高規范格式輸出 | 所生成的綜述文檔格式規范、結構清晰,符合學術論文標準,用戶幾乎無需進行二次整理。 |
例如,一位內容創作者利用Ollama接口生成了多篇博客文章,平均創作時間縮短了50%。你可以通過調整生成參數(如溫度和最大長度)來優化生成結果,滿足不同場景的需求。
Ollama接口在代碼生成領域同樣表現出色。它可以根據你的需求生成代碼片段、函數模板,甚至是詳細的代碼注釋。你只需提供簡短的描述或問題,Ollama接口就能快速生成符合語法規范的代碼。
在本地推理場景中,某數據分析師使用Ollama接口分析本地存儲的銷售數據,并生成了自動化分析腳本,工作效率提高了30%。以下是一個簡單的代碼生成示例:
response = client.generate(
prompt="生成一個Python函數,用于計算兩個數的最大公約數",
max_tokens=100
)
print(response["text"])通過這種方式,你可以將更多時間投入到復雜的邏輯設計中,而不是重復性編碼任務。
在客戶服務領域,Ollama接口可以幫助你實現自動回復和個性化建議功能。它能夠根據用戶的提問生成準確的回答,同時保持對話的自然性和連貫性。
例如,在資源受限的環境中,某偏遠地區的氣象監測站利用Ollama接口部署了輕量級氣象預測模型。該模型實時預測天氣變化,為當地農業生產提供了及時的信息支持。
通過結合多輪對話功能,你可以為客戶提供更貼心的服務體驗。以下是一個自動回復的示例:
response = client.generate(
prompt="用戶:請問今天的天氣如何?n智能體:",
max_tokens=50
)
print(response["text"])這種應用不僅提升了服務效率,還增強了用戶滿意度。
Ollama接口是一款功能強大且靈活的文本生成工具,能夠滿足內容創作、代碼生成和客戶服務等多種需求。通過本文的實踐指南,你可以快速掌握安裝、配置和調用接口的方法,輕松構建高效的文本生成應用。
> 提示:嘗試不同的功能和優化技巧,能夠幫助你更好地探索Ollama接口的潛力。
無論是提升創作效率,還是優化對話體驗,Ollama接口都能為你提供可靠的解決方案。立即動手實踐,發現更多可能性!




