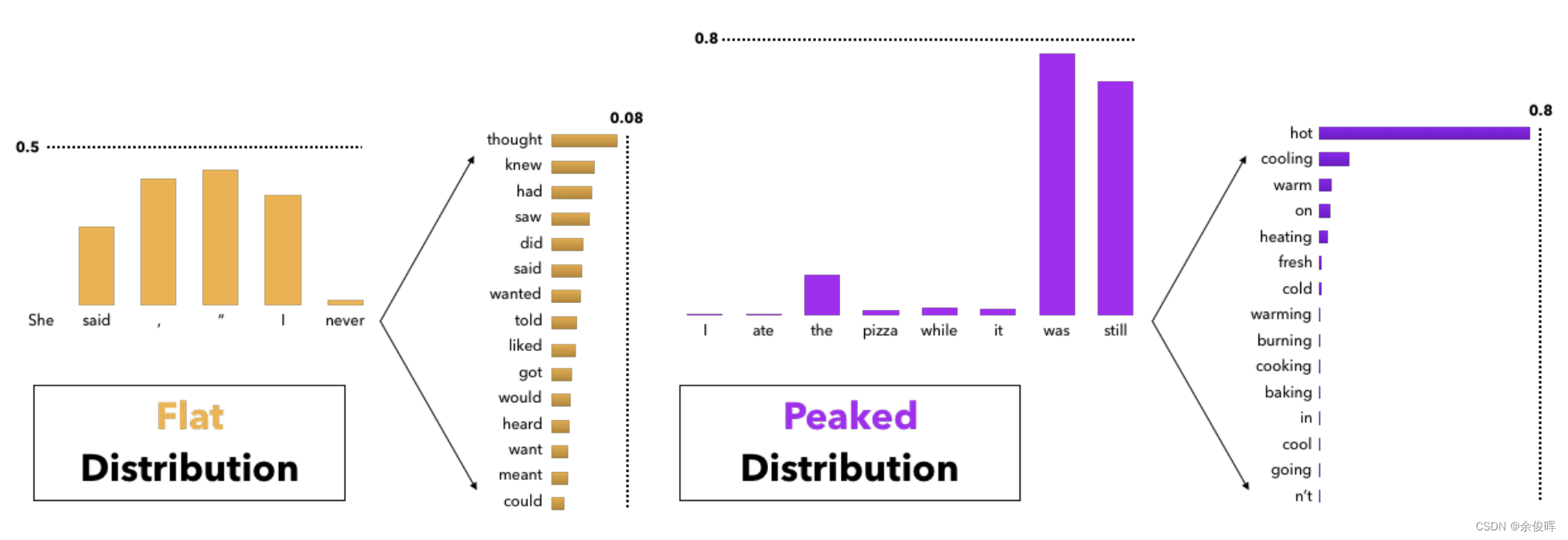
在文本生成任務(wù)中,選擇合適的 Temperature 值尤為重要。例如,在自動(dòng)詩(shī)歌生成時(shí),可以選擇較高的 Temperature 來(lái)增加創(chuàng)意,而在法律文檔生成時(shí),則需要較低的 Temperature 保持嚴(yán)謹(jǐn)性。
sample_top_p 是另一種控制生成隨機(jī)性的算法,又稱(chēng)為核采樣。它通過(guò)選取概率和超過(guò)某一閾值的詞來(lái)生成文本。
def sample_top_p(probs, p):
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
return next_token在實(shí)際應(yīng)用中,sample_top_p 可以有效減少生成結(jié)果的重復(fù)性,增加文本的多樣性。例如,在對(duì)話生成中,可以通過(guò)設(shè)置合適的 top_p 值來(lái)確保對(duì)話的自然流暢。
LLAMA 模型的核心生成函數(shù) generate() 結(jié)合了多種參數(shù)調(diào)控機(jī)制,為文本生成提供了強(qiáng)大的靈活性。
def generate(
self,
prompt_tokens: List[List[int]],
max_gen_len: int,
temperature: float = 0.6,
top_p: float = 0.9,
logprobs: bool = False,
echo: bool = False,
) -> Tuple[List[List[int]], Optional[List[List[float]]]]:
params = self.model.params
bsz = len(prompt_tokens)
assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)
min_prompt_len = min(len(t) for t in prompt_tokens)
max_prompt_len = max(len(t) for t in prompt_tokens)
assert max_prompt_len 0:
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
next_token = torch.argmax(logits[:, -1], dim=-1)
next_token = next_token.reshape(-1)
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
tokens[:, cur_pos] = next_token
eos_reached |= (~input_text_mask[:, cur_pos]) & (
next_token == self.tokenizer.eos_id
)
prev_pos = cur_pos
if all(eos_reached):
break
if logprobs:
token_logprobs = token_logprobs.tolist()
out_tokens, out_logprobs = [], []
for i, toks in enumerate(tokens.tolist()):
start = 0 if echo else len(prompt_tokens[i])
toks = toks[start: len(prompt_tokens[i]) + max_gen_len]
probs = None
if logprobs:
probs = token_logprobs[i][start: len(prompt_tokens[i]) + max_gen_len]
if self.tokenizer.eos_id in toks:
eos_idx = toks.index(self.tokenizer.eos_id)
toks = toks[:eos_idx]
probs = probs[:eos_idx] if logprobs else None
out_tokens.append(toks)
out_logprobs.append(probs)
return (out_tokens, out_logprobs if logprobs else None)這一函數(shù)不僅支持多樣的參數(shù)調(diào)整,還能通過(guò)不同的策略組合實(shí)現(xiàn)最優(yōu)的文本生成效果。無(wú)論是在創(chuàng)意文本還是結(jié)構(gòu)化文檔生成中,都能提供強(qiáng)有力的支持。
LLAMA 模型在多個(gè)領(lǐng)域展現(xiàn)了其強(qiáng)大的生成能力。以下是一些具體的應(yīng)用案例:
以下是一個(gè)簡(jiǎn)單的代碼補(bǔ)全示例,展示了如何利用LLAMA模型進(jìn)行代碼生成:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))通過(guò)對(duì) model.generate 參數(shù)的深入探討,我們可以更好地理解和應(yīng)用 LLAMA 模型的強(qiáng)大功能。在未來(lái),隨著模型能力的提升和應(yīng)用領(lǐng)域的擴(kuò)展,這些參數(shù)設(shè)置將起到更加關(guān)鍵的作用。
問(wèn):什么是 Temperature 超參數(shù)?
問(wèn):如何應(yīng)用 sample_top_p 采樣?
問(wèn):LLAMA 模型可以應(yīng)用于哪些領(lǐng)域?
問(wèn):如何選擇合適的 generate 參數(shù)設(shè)置?
問(wèn):generate 函數(shù)支持哪些設(shè)備?