
文心一言寫代碼:代碼生成力的探索
為了有效利用 Mistral-Large-Instruct-2407 模型,用戶需要配置幾項關鍵參數。經過實測,使用四張 A800 GPU 可以成功運行該模型。以下是具體的配置方法:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m vllm.entrypoints.openai.api_server
--model /data/models/Mistral-Large-Instruct-2407/
--served-model-name aaa
--trust-remote-code
--tensor-parallel-size 4
--port 8000部署后,可通過標準 OpenAI 接口訪問該模型,實現便捷的調用與集成。
在 AI 任務測試中,Mistral-Large-Instruct-2407 展現了卓越的性能。以“9.11 和 9.9 哪個大”為例,該模型提供了正確的答案,并通過了多個數學基準測試,顯示出其推理與解決問題的能力顯著增強。
9.11 比 9.9 大。
原因如下:
1. 首先比較整數部分:9.11 和 9.9 的整數部分都是 9,所以它們相等。
2. 接下來比較小數部分:
- 9.11 的小數部分是 0.11。
- 9.9 的小數部分是 0.9。
顯然,9.11(即 9 + 0.11)比 9.9(即 9 + 0.9)大,因為 9.11 比 9.9 多了 0.01。盡管結果正確,但推理過程中的某些細節可以進一步優化,以提高輸出的嚴謹性。
Mistral-Large-Instruct-2407 在代碼生成與推理領域表現出色。通過大量代碼示例的訓練,該模型能夠生成準確且高效的代碼段,并在多個基準測試中表現優異。
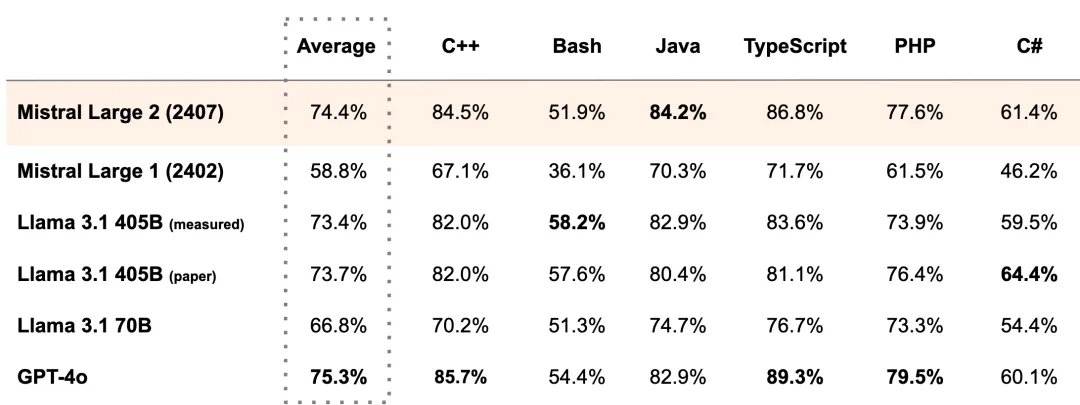
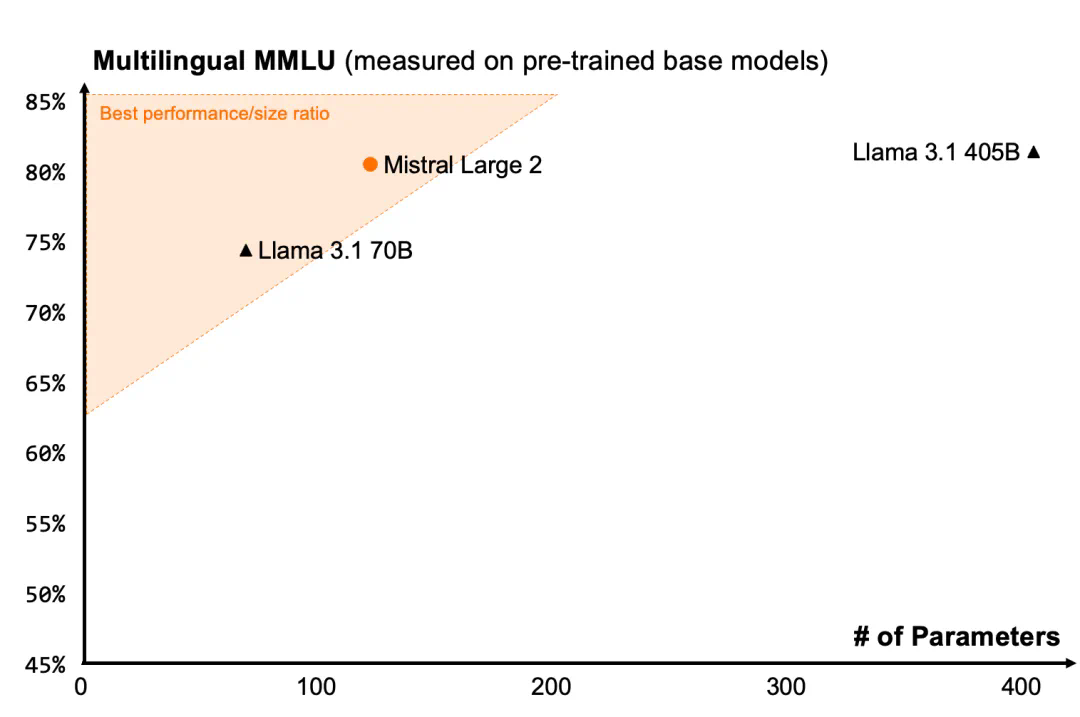
支持數十種語言的 Mistral-Large-Instruct-2407,尤其擅長處理多語言文檔,適用于全球化業務場景。在多語言 MMLU 基準測試中,其表現優于先前的模型版本。
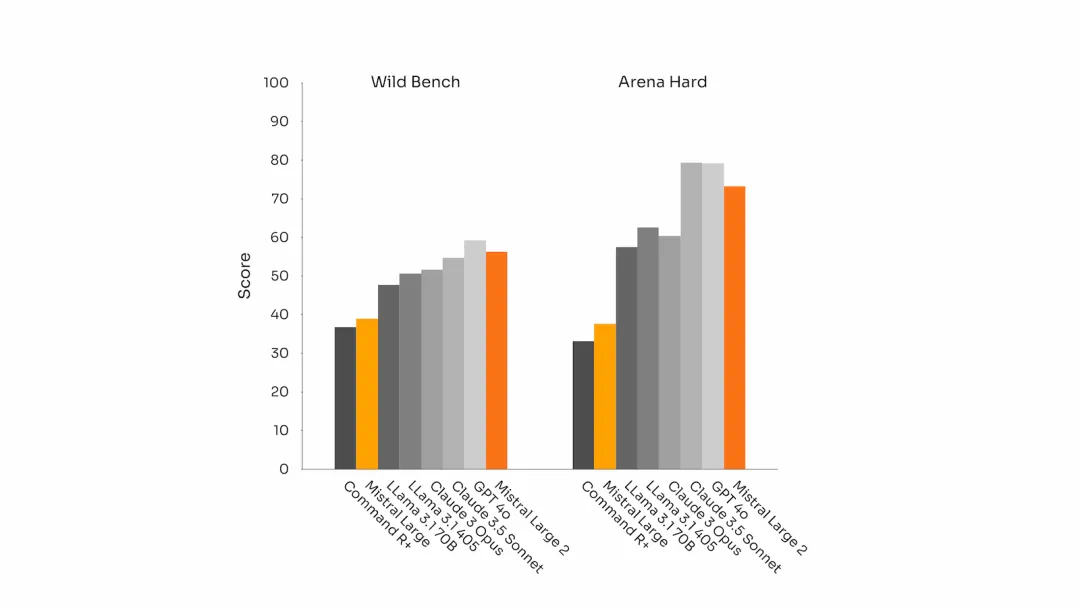
Mistral-Large-Instruct-2407 在指令遵循和對話能力上有了顯著提升。尤其在長時間多輪對話中,能夠保持上下文一致性和邏輯性。
盡管官方聲稱支持最大 128k 的 token,但實際測試中,模型僅支持 32k 的 token 上下文長度。用戶在發送請求時,需注意消息長度,避免超出此限制。
目前,vllm 并不支持 Mistral-Large-Instruct-2407 的函數調用功能,但其潛在能力在官方測評中已被證明出色。
Mistral-Large-Instruct-2407 的開放使用僅限于研究和非商業用途。對于商業部署,用戶需提前獲得 Mistral AI 的商業許可證。同時,模型的開放權重允許第三方根據需求進行微調,進一步優化模型性能。
Mistral-Large-Instruct-2407 憑借其強大的通用能力、卓越的代碼與推理能力,已成為接近 GPT4 的頂尖 AI 模型之一。盡管存在某些技術限制,該模型依舊是人工智能領域中一顆璀璨的明珠。
問:Mistral-Large-Instruct-2407 是否支持商業用途?
問:如何部署 Mistral-Large-Instruct-2407?
問:Mistral-Large-Instruct-2407 支持哪些語言?
問:最大 Token 限制對使用有什么影響?
問:Mistral-Large-Instruct-2407 的函數調用能力如何?






