
如何調用 Minimax 的 API
隨著AI Agent的興起,2025年被視為Agent快速發展的關鍵年份。無論是單Agent還是多Agent系統,都需要更長的上下文來支持持續記憶和大量通信。MiniMax-01系列模型的推出正是為了滿足這一需求,為復雜Agent基礎能力的建立邁出重要一步。
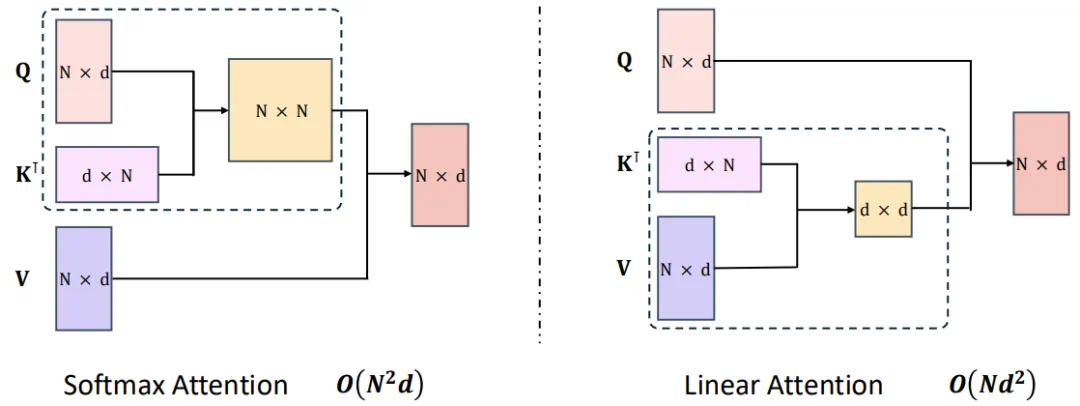
MiniMax-01系列模型的創新體現在多個方面。首先是其高達4560億的參數量和線性注意力機制的首次大規模應用。這使得MiniMax在處理長輸入時的效率極高,接近線性復雜度,能夠高效處理長達400萬token的上下文,是GPT-4o的32倍、Claude-3.5-Sonnet的20倍。
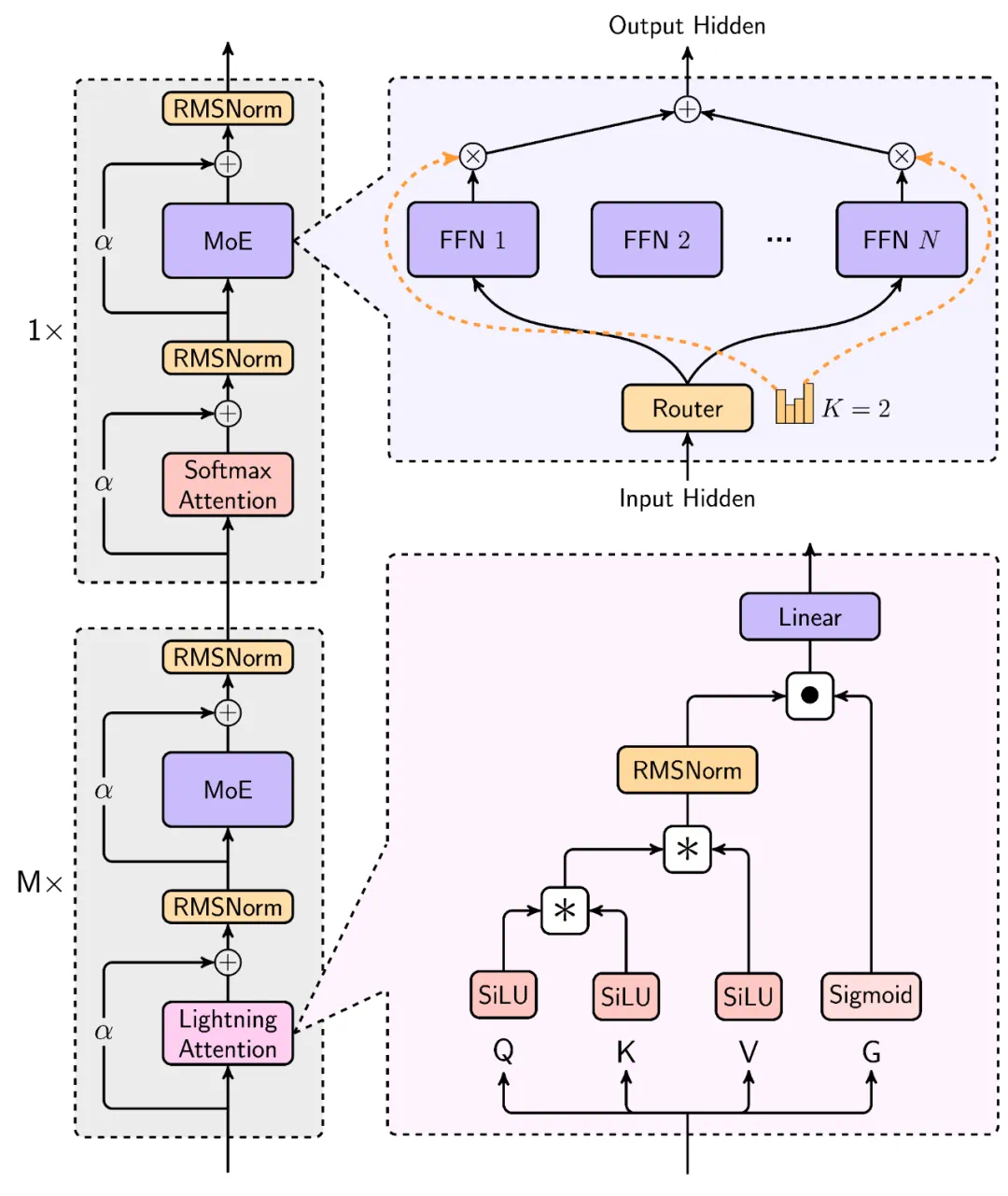
為了實現這一突破,MiniMax在Scaling Law、與MoE結合、結構設計、訓練優化和推理優化等方面進行了綜合考量,并重構了訓練和推理系統,包括更高效的MoE All-to-all通訊優化、更長序列優化以及推理層面的線性注意力的高效Kernel實現。
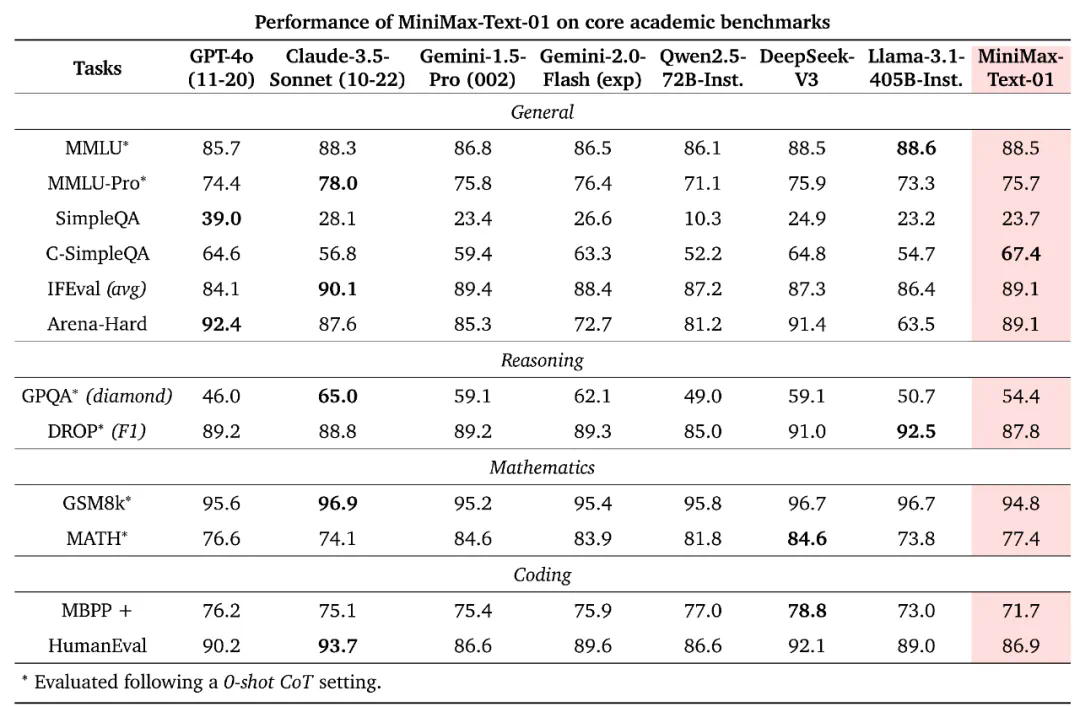
在業界主流的文本和多模態理解測評中,MiniMax-01系列在多數任務上追平了海外公認的先進模型,如GPT-4o-1120和Claude-3.5-Sonnet-1022。尤其是在長文任務上,MiniMax-Text-01隨著輸入長度增加,性能衰減最慢,顯著優于Google的Gemini模型。
MiniMax的模型在處理長輸入時效率極高,接近線性復雜度。其結構設計中,每8層中有7層采用基于Lightning Attention的線性注意力,1層采用傳統SoftMax注意力。這是業內首次將線性注意力機制擴展到商用模型級別。
MiniMax還開發了一個多模態版本:MiniMax-VL-01,其整體架構符合比較常見的ViT-MLP-LLM范式。在文本模型的基礎上整合了一個圖像編碼器和一個圖像適配器,以將圖像轉換成LLM能夠理解的token形式。
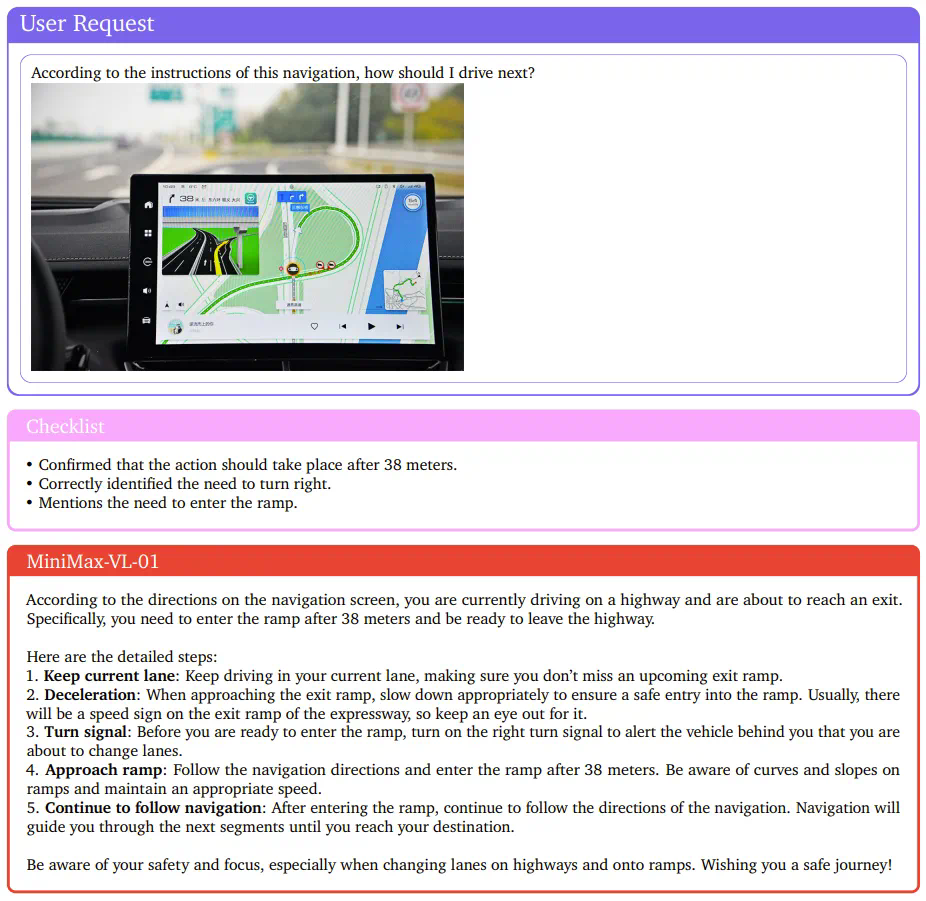
為了確保MiniMax-VL-01的視覺理解能力,MiniMax設計了一個專有數據集,并實現了一個多階段訓練策略。最終,MiniMax-VL-01在各個基準上表現出色,在某些指標上達到最佳。
得益于架構創新、效率優化和集群訓推一體設計,MiniMax能夠以業內最低的價格區間提供文本和多模態理解的API服務。標準定價為輸入token1元/百萬token,輸出token8元/百萬token。MiniMax開放平臺及海外版已上線,供開發者體驗使用。

MiniMax-01系列模型已在GitHub開源,并將持續更新。開發者可以通過GitHub訪問開源代碼:MiniMax開源地址。
MiniMax團隊表示,他們正在研究更高效的架構,以完全消除SoftMax注意力,這可能使模型能夠支持無限的上下文窗口,而不會帶來計算開銷。除此之外,MiniMax還在LLM的基礎上訓練的視覺語言模型,同樣擁有超長的上下文窗口。這也是由Agent所面臨的任務所決定的。
MiniMax創始人在去年的一次活動中提到:「我們認為下一代人工智能是無限接近通過圖靈測試的智能體,交互自然,觸手可及,無處不在。」
Lightning Attention是MiniMax在優化Transformer自注意力機制方面的重大突破。通過使用這種線性注意力,原生Transformer的計算復雜度從二次復雜度大幅下降到線性復雜度,這主要得益于一種右邊積核技巧(right product kernel trick)。
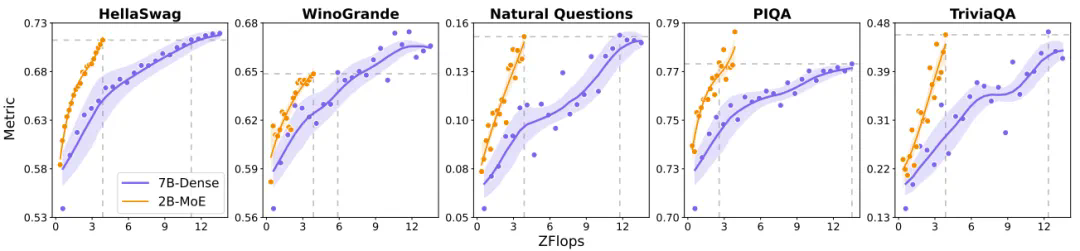
混合專家(MoE)相對于密集模型的效率優勢已經得到了大量研究證明。MiniMax團隊同樣通過實驗驗證了這一點,其MoE架構在多種基準上表現優于密集模型。
為了更好地處理長上下文,MiniMax采用了數據格式化技術,即將不同樣本沿序列的維度首尾相連,減少計算浪費。這種方法被稱為data-packing,是優化長上下文訓練的關鍵所在。
MiniMax在實踐中應用了包括分批核融合、分離式的預填充與解碼執行、多級填充、跨步分批矩陣乘法擴展等四項優化策略,以將Lightning Attention投入實際應用。

答:MiniMax-01系列模型在架構上首次大規模應用了線性注意力機制,能夠處理長達400萬token的上下文,是其他模型的20-32倍。
答:MiniMax采用了數據格式化技術,將不同樣本沿序列的維度首尾相連,減少計算浪費,并使用Lightning Attention降低計算復雜度。
答:MiniMax提供業內最低的價格區間,輸入token1元/百萬token,輸出token8元/百萬token。
答:MiniMax-VL-01在各個基準上表現出色,其整體架構符合ViT-MLP-LLM范式,能夠處理多模態任務。
答:MiniMax正在研究更高效的架構,以完全消除SoftMax注意力,實現支持無限上下文窗口的模型。





