
AI視頻剪輯工具:解鎖創作的無限可能
機器學習的起源可以追溯到20世紀中期。1943年,人工神經元模型的建立標志著機器學習的開端。隨后,1957年感知器的發明奠定了機器學習的基礎,開啟了人工智能研究的新篇章。
1986年,反向傳播算法的提出使得神經網絡得以復興。2012年,卷積神經網絡在ImageNet競賽中獲勝,標志著深度學習的突破。2016年,AlphaGo的成功展示了機器學習在強化學習領域的潛力。
未來,機器學習的發展將會更加注重自動化與分布式學習。自動化機器學習(AutoML)和聯邦學習(Federated Learning)是其中的兩個重要方向,它們將進一步提升機器學習的效率和安全性。
監督學習是一種依賴于標記數據進行訓練的機器學習方法。在這種學習方法中,每個輸入數據都有一個已知的輸出,模型通過學習這些映射關系來進行預測。常見的應用包括分類和回歸任務。
無監督學習則在沒有標記數據的情況下進行訓練。模型通過識別數據中的模式和結構來進行任務,例如聚類和降維。無監督學習在發現數據的潛在結構方面具有重要作用。
強化學習通過與環境的交互來學習策略,以最大化某種累積獎勵。它廣泛應用于游戲AI、機器人控制等領域。強化學習的特點是通過試錯法來改進策略,以達到最佳的執行效果。
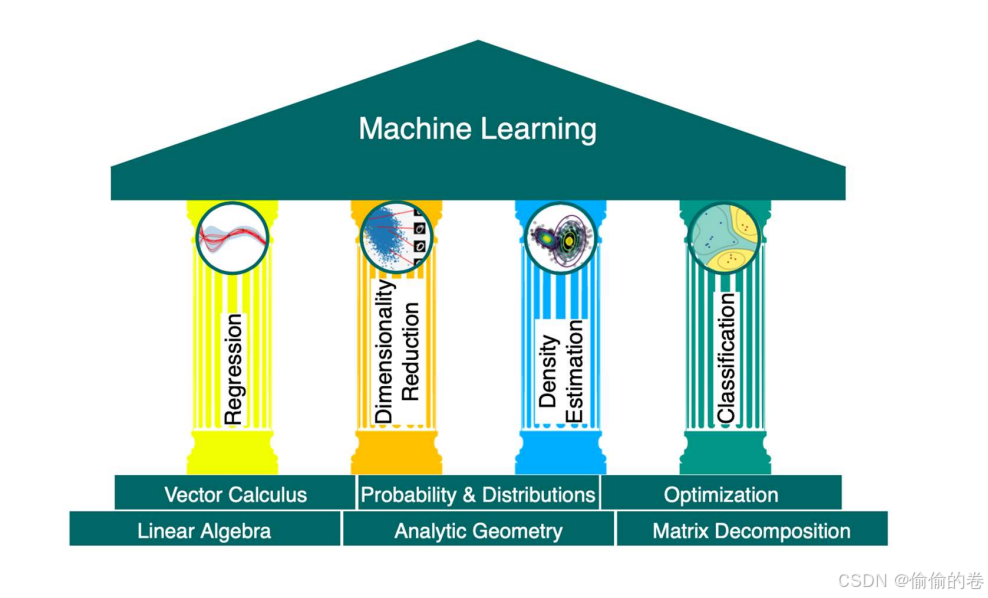
線性代數在機器學習中占據重要地位。許多機器學習算法依賴于矩陣運算和向量操作。矩陣的乘法、轉置、求逆等操作在數據處理和模型訓練中廣泛應用。
微積分是優化算法的基礎。在機器學習中,梯度下降法是一種常用的優化算法,通過計算損失函數的導數來更新模型參數,以達到最小化誤差的目的。
概率與統計為機器學習提供了理論支持。它們用于建模數據的不確定性,描述模型的性能,并在某些算法中,例如樸素貝葉斯分類器中,發揮關鍵作用。
模型的實現離不開算法和代碼的支持。在機器學習中,Python是一種常用的編程語言,借助其豐富的庫,如Numpy、pandas、Scikit-learn、PyTorch,開發者可以快速實現各種機器學習模型。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
# 生成數據
X, y = make_regression(n_samples=100, n_features=1, noise=0.1)
# 分割數據
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 創建模型并訓練
model = LinearRegression()
model.fit(X_train, y_train)
# 預測
y_pred = model.predict(X_test)機器學習在圖像和視頻處理中的應用非常廣泛。通過卷積神經網絡(CNN),計算機可以實現圖像分類、目標檢測等任務。這些技術在自動駕駛、醫療影像分析中都有重要作用。
在自然語言處理領域,機器學習用于文本分類、情感分析、機器翻譯等。通過序列到序列模型(Seq2Seq),計算機可以將一種語言翻譯成另一種語言,極大地提升了翻譯服務的效率。
自動駕駛汽車中,機器學習用于識別道路、車輛、行人等。通過傳感器數據的實時分析,車輛可以規劃行駛路徑,實現安全高效的自動駕駛。
目前,機器學習已經在多個領域取得了顯著進展。但其發展仍然面臨挑戰,包括數據隱私問題、算法的解釋性等。
未來,機器學習將更加注重自動化與協作學習。特別是在數據隱私日益重要的今天,聯邦學習等技術將會有更廣泛的應用。
機器學習作為一門迅速發展的技術,不斷推動著各個行業的變革。通過不斷的探索和創新,機器學習將為人類創造更多的可能性。






