
如何調(diào)用 Minimax 的 API
LCM 的開發(fā)涉及多個關(guān)鍵技術(shù)和創(chuàng)新點,這些技術(shù)的融合使得 LCM 在處理復(fù)雜任務(wù)時表現(xiàn)出色。
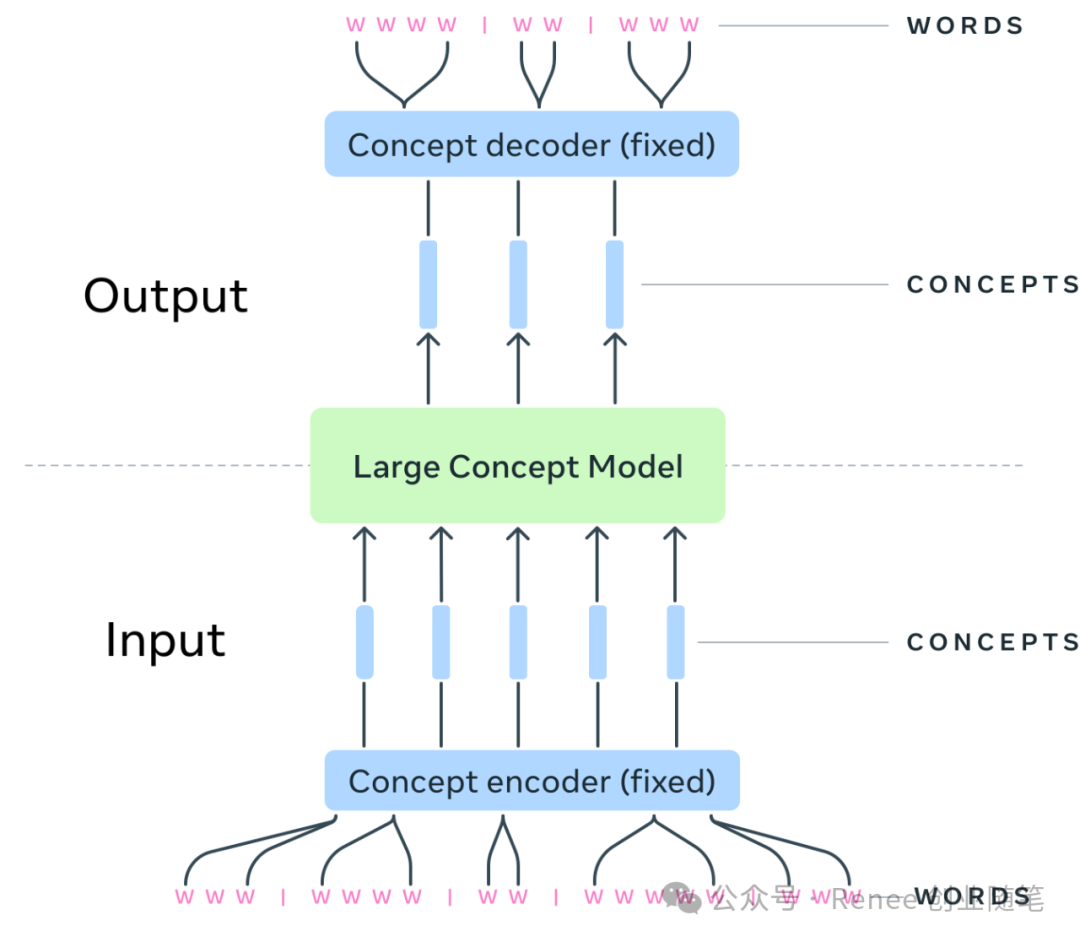
在 LCM 中,一個“概念”通常代表一整句話。這種定義允許 LCM 利用現(xiàn)有的句子嵌入空間(SONAR),支持超過 200 種語言的處理,涵蓋了文本與語音兩種模態(tài)。通過這樣的設(shè)計,LCM 能夠在更高的語義層次上進(jìn)行建模。
LCM 的模型設(shè)計依托于 SONAR 嵌入空間進(jìn)行訓(xùn)練,以實現(xiàn)自回歸句子預(yù)測。初步實驗中,LCM 使用了 1.6B 參數(shù)的模型,訓(xùn)練數(shù)據(jù)規(guī)模達(dá)到了 1.3 萬億 tokens。后續(xù)還將擴(kuò)展到 7B 參數(shù),訓(xùn)練數(shù)據(jù)達(dá)到 7.7 萬億 tokens。
LCM 的多模態(tài)和多語言能力使其在許多應(yīng)用場景中表現(xiàn)出色,特別是在生成任務(wù)和跨語言任務(wù)中。
LCM 展示了卓越的零樣本泛化能力,尤其是在多語言環(huán)境下的表現(xiàn)優(yōu)于同等規(guī)模的現(xiàn)有 LLM。這使得 LCM 在摘要生成和擴(kuò)展等任務(wù)中具有顯著的優(yōu)勢。
為了促進(jìn)社區(qū)研究,Meta 已經(jīng)開源了 LCM 的訓(xùn)練代碼。研究者可以在 GitHub 上獲取相關(guān)資源并進(jìn)行進(jìn)一步的開發(fā)和優(yōu)化。
LCM 的方法探索涵蓋了多種生成策略和模型優(yōu)化手段,其中包括 MSE 回歸和基于擴(kuò)散的生成變體。
基于均方誤差 (MSE) 的訓(xùn)練方法被稱為 base_lcm,這一實現(xiàn)已在代碼倉庫中提供。通過 MSE 回歸,LCM 能夠在生成任務(wù)中實現(xiàn)更高的精度和效率。
使用擴(kuò)散機(jī)制的生成模型稱為 two_tower_diffusion_lcm,該模型同樣在代碼發(fā)布內(nèi)容中包含。擴(kuò)散機(jī)制的引入為 LCM 提供了更強(qiáng)的生成能力。
LCM agent 的開發(fā)涉及多個步驟,從配置模塊驅(qū)動到代碼編譯和燒寫,每一步都需要精細(xì)的操作和調(diào)試。
在 kernel 和 lk 中配置 LCM 模塊驅(qū)動相關(guān)文件是開發(fā)的基礎(chǔ)步驟。開發(fā)者需要在相應(yīng)的目錄中更新 .c 和 .mk 文件,并將 LCM 添加到配置文件中。
完成模塊配置后,開發(fā)者需要通過特定的編譯命令生成可執(zhí)行代碼,并使用 Smart phone Flash Tool 進(jìn)行燒寫。這一過程要求開發(fā)者熟練掌握工具使用和命令行操作。
source build/envsetup.sh
lunchfull_hq6737t_66_1hg_m-eng
make -j13 2>&1 | tee build.logLCM 的高層次概念建模和多模態(tài)處理能力為 AI 領(lǐng)域帶來了新的可能性。未來,隨著技術(shù)的不斷進(jìn)步和社區(qū)的深入研究,LCM 有望在更多應(yīng)用場景中發(fā)揮重要作用。
LCM 的抽象語義表示可能成為自學(xué)習(xí) AI 的重要里程碑。憑借其在復(fù)雜任務(wù)中的靈活性和高效性,LCM 將為 AI 系統(tǒng)的思考與推理能力帶來全新突破。
LCM 的設(shè)計理念超越了傳統(tǒng) token 操作,為模型在復(fù)雜任務(wù)中的靈活性提供了更多可能。其在潛在空間中規(guī)劃概念,再將其具體化為語言的模式,使得 LCM 更加接近人類思維的模擬。
LCM,即 Large Concept Models,是一種新型 AI 模型,旨在通過高維嵌入空間和概念級建模提高多模態(tài)和多語言任務(wù)的處理能力。
LCM 不再依賴離散的 token 序列,而是在語義嵌入空間中建模,并通過概念級建模實現(xiàn)更高效的語義理解和生成。
Meta 已經(jīng)在 GitHub 上開源了 LCM 的訓(xùn)練代碼,開發(fā)者可以訪問 LCM 開源項目 獲取相關(guān)資源。
LCM 在生成任務(wù)、摘要生成與擴(kuò)展、跨語言任務(wù)等多領(lǐng)域展現(xiàn)了卓越的性能,尤其在多語言環(huán)境下的表現(xiàn)優(yōu)于同等規(guī)模的現(xiàn)有 LLM。
LCM 的開發(fā)涉及模塊驅(qū)動配置、代碼編譯和燒寫。開發(fā)者需要在 kernel 和 lk 中配置相關(guān)文件,并使用編譯命令和工具進(jìn)行調(diào)試和部署。





