反向索引的優勢在于查詢效率高。在搜索引擎系統中,用戶的查詢通過反向索引可以快速定位到相關文檔,無需掃描整個文檔庫。
反向索引與正向索引的比較
反向索引的結構
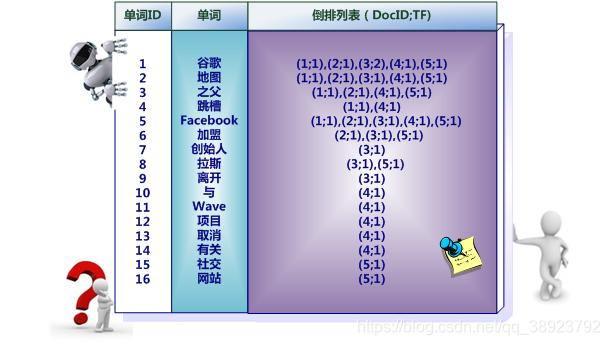
反向索引的核心是兩個部分:單詞詞典和倒排文件。單詞詞典記錄了所有出現過的單詞,每個單詞指向一個倒排列表。倒排列表包含出現該單詞的文檔ID及其在文檔中的位置信息。
正向索引的局限性
正向索引在文檔添加或刪除時更容易維護,但在查詢時需要遍歷所有文檔,效率較低。對于海量數據,這種方式顯然無法滿足快速響應的需求。
單詞-文檔矩陣與反向索引
單詞-文檔矩陣是一種概念模型,展示了單詞與文檔之間的關系。在這個矩陣中,行表示單詞,列表示文檔,矩陣中的每個元素表示該單詞在該文檔中的出現情況。
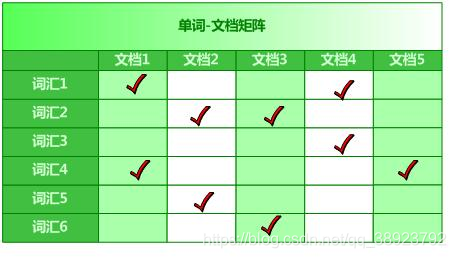
單詞-文檔矩陣的解讀
縱向解讀
從縱向來看,單詞-文檔矩陣可以幫助我們了解每個文檔中包含哪些單詞。例如,某一列代表的文檔可能包含單詞A、B,但不包含單詞C。
橫向解讀
從橫向來看,該矩陣幫助我們識別哪些文檔包含某個單詞。例如,某一行代表的單詞可能出現在文檔1和文檔3中,而不出現在文檔2中。
反向索引的構建與維護
構建反向索引需要先對文檔進行分詞,然后記錄每個單詞的出現文檔及位置信息。隨著新文檔的加入或舊文檔的刪除,反向索引需要動態更新。
反向索引的構建步驟
- 分詞處理:將文檔轉化為單詞序列。
- 單詞編號:為每個不同的單詞分配一個唯一的編號。
- 記錄倒排列表:記錄每個單詞在哪些文檔中出現。

反向索引的更新與維護
在實際應用中,反向索引的更新效率需要特別關注。通常采用增量更新,即在文檔變更時只更新相關的倒排列表,而不是重建整個索引。
反向索引在搜索引擎中的應用
反向索引是搜索引擎中實現快速檢索的核心技術。通過反向索引,搜索引擎可以在接收到用戶查詢后,迅速定位到包含查詢詞的文檔列表。
搜索引擎使用反向索引的優勢
- 提高檢索速度:避免了逐個掃描文檔的低效過程。
- 支持復雜查詢:通過布爾運算支持多關鍵詞查詢。
- 結果排序優化:借助詞頻、文檔頻率信息,優化搜索結果排序。
反向索引的局限性
盡管反向索引大大提高了檢索效率,但其構建和維護的復雜性也不容忽視。在數據量極大的場景下,倒排列表的長度和更新頻率都是挑戰。
反向索引的優化策略
為了進一步提升反向索引的性能,可以從數據結構、存儲策略等方面進行優化。
數據結構優化
使用B樹或哈希表等高效數據結構來存儲單詞詞典,提升查找速度。
B樹結構
B樹是一種平衡的多叉樹結構,適合用于磁盤存儲,查找效率高。
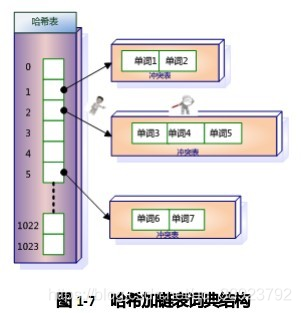
哈希表
哈希表通過計算單詞的哈希值快速定位單詞,適合用于大數據集的快速查找。
存儲策略優化
通過壓縮存儲、分布式存儲等手段,降低存儲空間需求,提高索引的可擴展性。
結論
反向索引無疑是搜索引擎提升檢索效率的核心技術之一。通過合理的結構設計和優化策略,反向索引能夠在大規模數據處理中保持高效穩定的性能。隨著技術的不斷進步,反向索引將在更多領域展現其強大的應用潛力。
FAQ
-
問:反向索引與正向索引的區別是什么?
- 答:反向索引以單詞為關鍵字記錄文檔信息,查詢效率高;正向索引以文檔為關鍵字記錄單詞信息,查詢效率低。
-
問:反向索引如何提高搜索引擎的效率?
- 答:反向索引允許快速定位包含查詢詞的文檔,避免掃描整個文檔庫,提高查詢速度。
-
問:反向索引在更新時面臨哪些挑戰?
- 答:在文檔頻繁更新的場景下,維護倒排列表的準確性和更新效率是主要挑戰。
-
問:如何優化反向索引的存儲策略?
- 答:可以通過使用壓縮技術和分布式存儲,降低存儲空間需求,提高索引的可擴展性。
-
問:反向索引在其他領域有何應用?
- 答:除了搜索引擎,反向索引還廣泛應用于數據庫查詢優化、文本分析等領域。
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業工程師共享工作效率翻倍的秘密
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
成人黄色片在线观看|
久久久精品免费观看|
欧美videos大乳护士334|
蜜臀av一区二区三区|
国产午夜精品在线观看|
91在线精品一区二区三区|
亚洲成a人v欧美综合天堂|
欧美美女bb生活片|
国产精品一区二区免费不卡|
日韩理论片在线|
欧美一卡二卡三卡四卡|
成人午夜在线播放|
不卡一区中文字幕|
精品国产91亚洲一区二区三区婷婷|
欧美a级理论片|
国产欧美一区视频|
欧美在线你懂得|
国产激情一区二区三区四区
|
亚洲裸体xxx|
欧美一级欧美三级在线观看|
不卡一区在线观看|
免费成人小视频|
国产日产精品1区|
777亚洲妇女|
97久久超碰国产精品|
婷婷开心激情综合|
国产欧美一区二区三区在线看蜜臀|
欧美日韩一区成人|
proumb性欧美在线观看|
另类小说图片综合网|
亚洲国产日韩综合久久精品|
亚洲欧洲一区二区在线播放|
久久影院视频免费|
欧美日韩精品一区二区三区四区|
国产sm精品调教视频网站|
首页综合国产亚洲丝袜|
一区二区三区**美女毛片|
国产精品嫩草影院com|
精品国产百合女同互慰|
欧美精品三级在线观看|
91视频观看免费|
成人a免费在线看|
国产xxx精品视频大全|
久久精品99国产精品日本|
日韩高清不卡一区二区三区|
亚洲成av人影院|
亚洲高清在线视频|
午夜影院在线观看欧美|
亚洲国产另类av|
一二三四区精品视频|
亚洲美女少妇撒尿|
亚洲综合图片区|
亚洲妇熟xx妇色黄|
亚洲成人激情av|
日韩在线一二三区|
日韩在线观看一区二区|
另类人妖一区二区av|
蜜乳av一区二区三区|
肉丝袜脚交视频一区二区|
性做久久久久久免费观看|
午夜精品久久久久久久蜜桃app|
亚洲国产你懂的|
日韩激情av在线|
看电影不卡的网站|
国产成人精品一区二区三区四区|
粉嫩13p一区二区三区|
99久免费精品视频在线观看|
在线观看成人免费视频|
欧美日韩亚洲综合在线
|
色屁屁一区二区|
欧美精三区欧美精三区|
精品久久久久香蕉网|
欧美国产在线观看|
一区二区三区精密机械公司|
视频一区二区中文字幕|
国产精品自在在线|
日本高清不卡在线观看|
日韩精品中文字幕在线一区|
国产欧美精品在线观看|
亚洲永久免费视频|
精品亚洲成av人在线观看|
99久久99久久精品免费观看|
欧美精品成人一区二区三区四区|
久久久亚洲欧洲日产国码αv|
亚洲天天做日日做天天谢日日欢
|
一区二区三区不卡视频在线观看
|
欧美日韩在线不卡|
国产三级欧美三级|
亚洲第一会所有码转帖|
国产高清久久久久|
欧美乱妇23p|
亚洲欧洲日韩女同|
国产一区二区三区国产|
欧美视频一区二区三区在线观看|
久久久久国产精品人|
亚洲午夜久久久久久久久电影院|
国产精品综合久久|
欧美一区二区视频在线观看2022|
国产视频一区二区在线|
麻豆传媒一区二区三区|
欧美在线综合视频|
日韩美女视频19|
高清成人在线观看|
久久先锋影音av|
免费视频一区二区|
欧美日韩亚洲综合一区|
亚洲激情在线激情|
99国产精品国产精品久久|
国产亚洲污的网站|
精品写真视频在线观看|
欧美乱熟臀69xxxxxx|
亚洲综合一区二区三区|
99国产精品久|
国产精品人妖ts系列视频|
韩国欧美国产1区|
日韩欧美一区二区三区在线|
香蕉加勒比综合久久|
欧美私人免费视频|
亚洲综合偷拍欧美一区色|
91视视频在线观看入口直接观看www
|
欧美精品一区二区三区四区|
日韩精品免费视频人成|
欧美午夜一区二区|
亚洲小说春色综合另类电影|
91美女片黄在线|
亚洲色图清纯唯美|
色狠狠综合天天综合综合|
中文字幕人成不卡一区|
成人国产电影网|
国产精品成人免费在线|
av不卡免费在线观看|
亚洲欧美一区二区三区孕妇|
色综合色狠狠综合色|
亚洲综合色视频|
欧美精品精品一区|
毛片av一区二区|
久久久久久久综合|
不卡一卡二卡三乱码免费网站|
国产精品久久久久久妇女6080|
99v久久综合狠狠综合久久|
亚洲激情图片一区|
欧美喷潮久久久xxxxx|
久久国产夜色精品鲁鲁99|
久久久久久久久久美女|
99在线精品免费|
亚洲国产成人tv|
欧美精品日韩一本|
国产一区二区视频在线|
最新中文字幕一区二区三区
|
日韩手机在线导航|
国产+成+人+亚洲欧洲自线|
亚洲日本欧美天堂|
69堂成人精品免费视频|
国产毛片精品国产一区二区三区|
国产精品乱码人人做人人爱|
欧美吻胸吃奶大尺度电影|
麻豆91小视频|
自拍偷拍亚洲综合|
日韩亚洲欧美高清|
91视频在线看|
国产在线视频一区二区|
亚洲黄色尤物视频|
久久久亚洲高清|
欧美精品日日鲁夜夜添|
成人美女视频在线观看18|
成人欧美一区二区三区黑人麻豆|
这里只有精品免费|
av高清不卡在线|
久久精品国产免费|
一区二区三区日韩欧美精品|
久久女同精品一区二区|
9久草视频在线视频精品|
蜜桃精品视频在线观看|
一二三四社区欧美黄|
日本一区二区电影|
日韩视频永久免费|
色av成人天堂桃色av|
成人动漫一区二区|
国产一区二区剧情av在线|
日韩精品一卡二卡三卡四卡无卡|
亚洲欧洲av色图|
久久免费视频色|
91精品国产乱码|
欧美日韩一区二区在线观看视频|
99精品欧美一区|
成人av在线资源网站|
激情另类小说区图片区视频区|
午夜久久久久久|
亚洲午夜国产一区99re久久|
亚洲欧洲av色图|
国产精品黄色在线观看|
国产欧美一区二区三区在线看蜜臀
|
午夜精品久久久久久久蜜桃app|
国产精品国产三级国产aⅴ入口|
久久久久久麻豆|
久久综合色婷婷|
精品成人a区在线观看|
精品久久久久99|
精品久久人人做人人爰|
欧美成人性福生活免费看|