
數(shù)據(jù)庫表關(guān)聯(lián):構(gòu)建高效數(shù)據(jù)結(jié)構(gòu)的關(guān)鍵
正態(tài)分布的數(shù)學(xué)表達(dá)式為:
[ f(x) = frac{1}{sqrt{2pisigma^2}} e^{-frac{(x-mu)^2}{2sigma^2}} ]
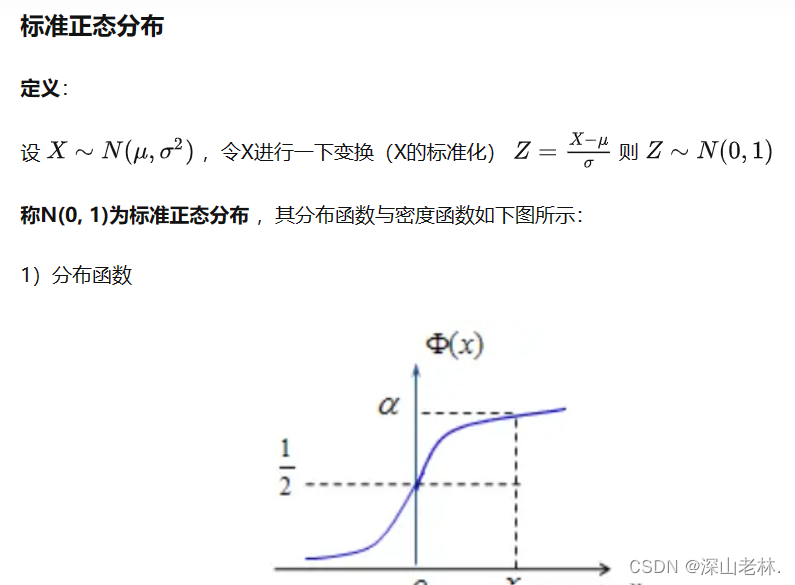
其中,(mu) 為均值,(sigma) 為標(biāo)準(zhǔn)差。在標(biāo)準(zhǔn)正態(tài)分布中,(mu = 0),(sigma = 1)。這意味著所有的數(shù)據(jù)點(diǎn)以Y軸為對稱軸。
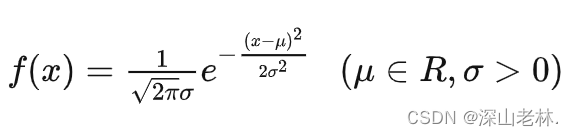
標(biāo)準(zhǔn)正態(tài)分布值計(jì)算器利用數(shù)學(xué)公式和隨機(jī)數(shù)生成技術(shù),生成符合指定均值和標(biāo)準(zhǔn)差的隨機(jī)數(shù)據(jù)集。通過計(jì)算累積分布函數(shù)(CDF),計(jì)算器可以產(chǎn)生特定數(shù)據(jù)點(diǎn)的概率值。
import java.util.Random;
public class NormalDistributionCalculator {
public static double calculate(double mean, double sd, double x) {
double exponent = -0.5 * Math.pow((x - mean) / sd, 2);
double probability = (1 / (sd * Math.sqrt(2 * Math.PI))) * Math.exp(exponent);
return probability;
}
}Java提供了豐富的數(shù)學(xué)庫,我們可以用它來實(shí)現(xiàn)一個(gè)簡單的正態(tài)分布生成器。下面是一個(gè)示例代碼,生成具有指定均值和標(biāo)準(zhǔn)差的正態(tài)分布隨機(jī)數(shù)。
import javax.swing.*;
import java.awt.*;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.util.Random;
public class NormalDistributionGenerator {
public static void main(String[] args) {
JFrame frame = new JFrame("正態(tài)分布生成器");
frame.setSize(400, 300);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
JPanel panel = new JPanel();
frame.add(panel);
placeComponents(panel);
frame.setVisible(true);
}
private static void placeComponents(JPanel panel) {
panel.setLayout(null);
JLabel meanLabel = new JLabel("均值:");
meanLabel.setBounds(10, 20, 80, 25);
panel.add(meanLabel);
JTextField meanText = new JTextField(20);
meanText.setBounds(100, 20, 165, 25);
panel.add(meanText);
JLabel sdLabel = new JLabel("標(biāo)準(zhǔn)差:");
sdLabel.setBounds(10, 50, 80, 25);
panel.add(sdLabel);
JTextField sdText = new JTextField(20);
sdText.setBounds(100, 50, 165, 25);
panel.add(sdText);
JButton generateButton = new JButton("生成");
generateButton.setBounds(10, 80, 150, 25);
panel.add(generateButton);
generateButton.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e) {
double mean = Double.parseDouble(meanText.getText());
double sd = Double.parseDouble(sdText.getText());
double number = new Random().nextGaussian() * sd + mean;
JOptionPane.showMessageDialog(panel, "生成的數(shù): " + number);
}
});
}
}
Excel是處理統(tǒng)計(jì)數(shù)據(jù)的強(qiáng)大工具。使用Excel中的NORM.DIST和NORM.S.DIST函數(shù),我們可以輕松計(jì)算出正態(tài)分布的累計(jì)概率和概率密度函數(shù)值。
此函數(shù)用于計(jì)算標(biāo)準(zhǔn)正態(tài)分布的概率值,語法如下:
NORM.S.DIST(z, cumulative)若要計(jì)算z=0.28對應(yīng)的標(biāo)準(zhǔn)正態(tài)分布累積分布值,在Excel中輸入:
=NORM.S.DIST(0.28, TRUE)
NORM.DIST函數(shù)用于計(jì)算給定均值和標(biāo)準(zhǔn)差的正態(tài)分布值,語法如下:
NORM.DIST(x, mean, standard_dev, cumulative)計(jì)算均值為0.6,標(biāo)準(zhǔn)差為0.089的正態(tài)分布下,x=0.65的累計(jì)概率值:
=NORM.DIST(0.65, 0.6, 0.089, TRUE)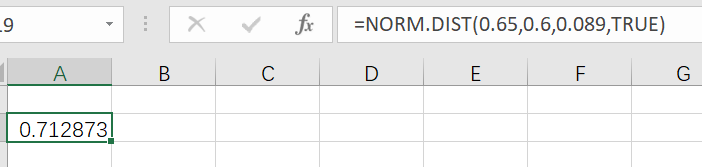
正態(tài)分布在現(xiàn)實(shí)生活中有廣泛應(yīng)用。比如,在質(zhì)量管理中,我們可以使用正態(tài)分布分析生產(chǎn)過程中產(chǎn)品的質(zhì)量特性。在金融領(lǐng)域,正態(tài)分布用于風(fēng)險(xiǎn)管理和金融建模。此外,在心理學(xué)研究中,正態(tài)分布幫助分析測量數(shù)據(jù)和實(shí)驗(yàn)結(jié)果。
標(biāo)準(zhǔn)正態(tài)分布值計(jì)算器是處理和分析數(shù)據(jù)時(shí)的一個(gè)強(qiáng)大工具。通過不同的軟件和編程語言,我們可以方便地生成和計(jì)算正態(tài)分布相關(guān)的概率值,從而更好地理解和應(yīng)用這些數(shù)學(xué)概念。
問:標(biāo)準(zhǔn)正態(tài)分布計(jì)算器可以用于哪些領(lǐng)域?
答:標(biāo)準(zhǔn)正態(tài)分布計(jì)算器廣泛應(yīng)用于統(tǒng)計(jì)學(xué)、工程學(xué)、金融學(xué)、心理學(xué)等領(lǐng)域,用于分析數(shù)據(jù)分布、風(fēng)險(xiǎn)評估和實(shí)驗(yàn)結(jié)果。
問:如何在Java中實(shí)現(xiàn)正態(tài)分布隨機(jī)數(shù)生成?
答:可以使用java.util.Random類的nextGaussian()方法來生成正態(tài)分布隨機(jī)數(shù),并通過公式調(diào)整其均值和標(biāo)準(zhǔn)差。
問:Excel中的NORM.DIST和NORM.S.DIST有什么區(qū)別?
答:NORM.S.DIST用于標(biāo)準(zhǔn)正態(tài)分布,而NORM.DIST用于指定均值和標(biāo)準(zhǔn)差的正態(tài)分布,前者是后者的特例。
問:標(biāo)準(zhǔn)正態(tài)分布曲線的特征是什么?
答:標(biāo)準(zhǔn)正態(tài)分布曲線呈鐘形,對稱于Y軸,均值為0,標(biāo)準(zhǔn)差為1,積分面積為1。
問:如何使用Excel計(jì)算正態(tài)分布的概率?
答:可以使用NORM.S.DIST或NORM.DIST函數(shù),通過設(shè)置參數(shù)計(jì)算給定數(shù)據(jù)點(diǎn)的累積分布函數(shù)或概率密度函數(shù)值。
數(shù)據(jù)庫表關(guān)聯(lián):構(gòu)建高效數(shù)據(jù)結(jié)構(gòu)的關(guān)鍵

企業(yè)知識庫開源:探索開源知識庫系統(tǒng)的最佳選擇

探索拉格朗日乘數(shù)法:從基礎(chǔ)到應(yīng)用
伊利諾伊州天氣:極寒天氣的影響與應(yīng)對措施

冪:從古代數(shù)學(xué)到現(xiàn)代科學(xué)的演變

經(jīng)緯度怎么看:詳細(xì)操作教程
當(dāng)前天氣:技術(shù)實(shí)現(xiàn)與應(yīng)用指南
魯棒性與過擬合的關(guān)系:從理論到實(shí)踐
鍵.png)
如何高效爬取全球新聞網(wǎng)站 – 整合Scrapy、Selenium與Mediastack API實(shí)現(xiàn)自動(dòng)化新聞采集