
如何調用 Minimax 的 API
HunyuanVideo 采用了圖像-視頻聯合訓練策略,將訓練數據精細劃分為不同類別,以滿足各自的訓練需求。視頻數據被劃分為五個不同組別,圖像數據則被劃分為兩個組別,以確保在訓練過程中充分發揮數據的特性和優勢。本節將重點介紹視頻數據的精細化篩選和準備過程。
原始數據池涵蓋多個領域,包括人物、動物、植物、風景、交通工具、物體、建筑及動畫等多種類別的視頻。所有視頻采集均設定了基本的閾值要求,如視頻的最小時長等。此外,還針對部分數據設定了更高的篩選標準,包括空間分辨率、特定寬高比、構圖、色彩和曝光等專業要求,確保數據在技術質量和美學品質上均達標。
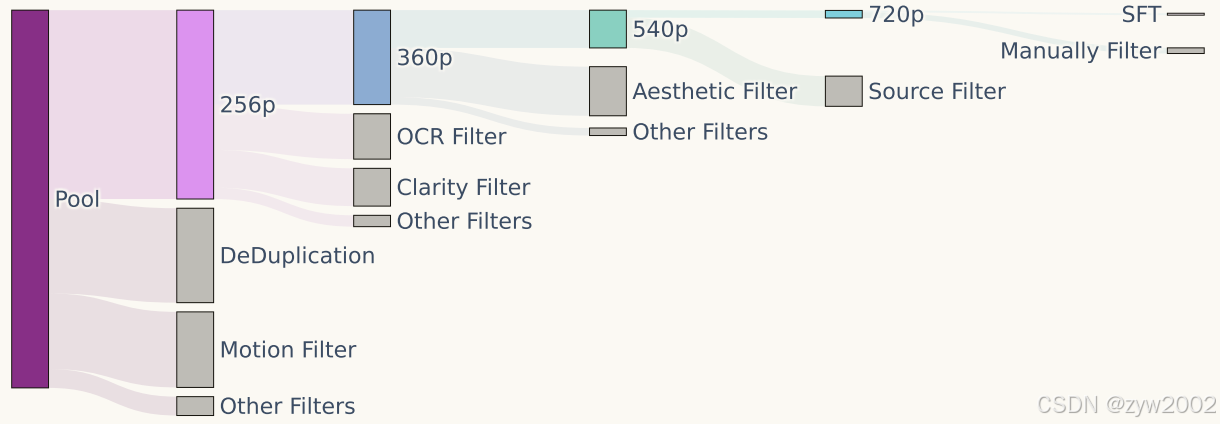
HunyuanVideo 采用了一系列預處理技術來提升數據質量。首先,使用 PySceneDetect 將視頻分割為單鏡頭片段。然后,利用 OpenCV 的拉普拉斯算子提取清晰幀作為視頻片段的起始幀。接著,通過內部 VideoCLIP 模型計算視頻嵌入向量,用于去重和聚類。
構建了一個分層數據篩選管道,通過多維度的篩選技術來提升數據質量,包括使用 Dover 評估視頻片段的美學和技術質量,剔除模糊視頻,預測視頻的運動速度,獲取場景邊界信息,移除帶有過多文本或字幕的片段,并去除水印、邊框和標志等遮擋或敏感信息。
通過小規模模型實驗驗證篩選器的有效性,并據此逐步優化數據篩選管道。最終,為不同訓練階段構建了五個視頻訓練數據集,視頻分辨率逐步提升,并根據訓練階段動態調整篩選閾值。
為提升生成模型的提示響應能力和輸出質量,開發了內部視覺語言模型(VLM),為所有圖像和視頻生成結構化標注。這些標注采用 JSON 格式,從多維度提供全面的描述信息,包括短描述、密集描述、背景、風格、鏡頭類型、光照和氛圍等。
訓練了一個相機運動分類器,能夠預測 14 種相機運動類型,包括變焦、平移、俯仰、繞拍、靜態鏡頭和手持鏡頭。高置信度的相機運動預測結果被集成到 JSON 格式的結構化標注中,從而賦予生成模型對相機運動的控制能力。
訓練了一個 3DVAE 模型,將像素空間的視頻和圖像壓縮到緊湊的潛在空間。為了同時處理視頻和圖像,采用的是 CausalConv3D。對于一個形狀為 (T+1) × 3 × H × W 的視頻,3DVAE 將其壓縮為潛在特征。這種壓縮方法顯著減少了后續模型所需的令牌數量,使其能夠以原始分辨率和幀率訓練視頻,同時保持較高的效率和質量。
3DVAE 訓練策略
在訓練過程中,我們采用了課程學習策略,逐步從低分辨率短視頻訓練到高分辨率長視頻。為了改善高運動視頻的重建效果,我們在采樣幀時隨機選擇了 1 至 8 范圍內的采樣間隔,確保從視頻剪輯中均勻地抽取幀。
推理階段
在單塊GPU上編碼和解碼高分辨率長視頻可能會導致顯存不足 (OOM) 錯誤。為了解決這一問題,采用了一種時空切片策略,將輸入視頻在空間和時間維度上劃分為重疊的切片。每個切片單獨編碼/解碼,最終再將輸出拼接在一起。對于重疊區域,我們使用線性組合進行平滑融合。這一切片策略使我們能夠在單塊GPU上處理任意分辨率和時長的視頻。
HunyuanVideo 中的 Transformer 設計,采用了統一的全注意力機制,并基于以下三大理由:
模型的具體結構如下圖所示。
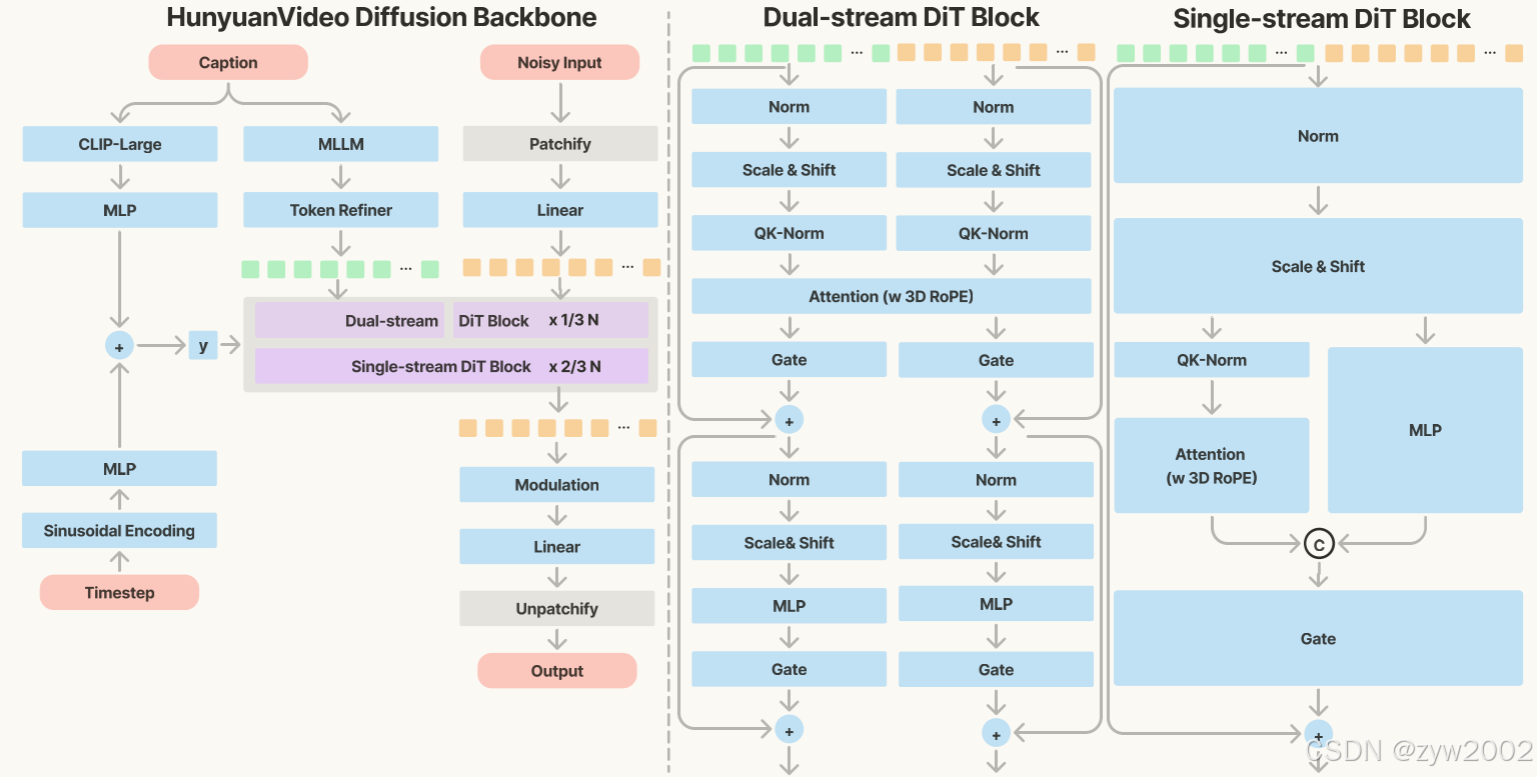
本研究使用 Flow Matching 框架來訓練圖像和視頻生成模型。Flow Matching 的核心思想是將復雜的概率分布通過一系列變量變換轉換為簡單的概率分布,通過逆變換從簡單分布生成新的數據樣本。
訓練過程
輸入表示使用訓練集中圖像或視頻的潛在表示。通過線性插值方法,構建訓練樣本。目標是預測速度場,指導樣本向樣本移動。優化參數通過最小化預測速度和真實速度的均方誤差 (MSE) 來優化模型參數。
推理過程
初始噪聲樣本從高斯分布中抽取。使用一階 Euler 常微分方程 (ODE) 求解器,結合模型預測的估計值,逐步計算生成樣本。
背景和動機
早期實驗表明,預訓練模型顯著加速了視頻訓練的收斂速度,并提升了視頻生成性能。為此,提出了一種兩階段的漸進式圖像預訓練策略,用于視頻訓練的熱啟動。
階段 1:256px 圖像訓練
目標是模型首先在低分辨率(256px)圖像上進行預訓練。策略包括多尺度訓練,在 256px 圖像上啟用多長寬比訓練,幫助模型學習生成寬廣長寬比范圍內的圖像。
階段 2:混合尺度訓練
目標是增強模型在高分辨率(如 512px)上的能力。提出混合尺度訓練方法,在每次訓練的全局批次中,引入兩個或多個尺度的多長寬比 buckets。
相比圖像生成,視頻生成在減少推理步驟的同時維持空間質量和時間質量更加具有挑戰性。為了解決這一問題,我們重點研究如何減少視頻生成所需的推理步驟數量。






