
如何調用 Minimax 的 API
Hunyuan-Video 可以生成符合用戶特定要求的個性化視頻內容。通過調整輸入的提示詞,用戶可以生成不同風格、主題的高質量視頻。這使其在廣告、娛樂等領域具有廣泛應用潛力。
模型支持視頻、音頻和文本的多模態信息整合,使得生成的視頻不僅在視覺上吸引人,還能在聲音和文字上保持一致。通過這種方式,Hunyuan-Video 能夠生成更為生動和真實的多媒體內容。
Hunyuan-Video 支持將靜態圖像轉化為動態視頻,通過模型微調技術,將給定的圖像作為視頻的第一幀進行生成。該功能在動畫制作和教育內容生成中具有重要應用。
Hunyuan-Video 采用圖像-視頻聯合訓練策略,通過這樣的訓練機制,模型能夠同時處理圖像和視頻數據。這種方法不僅提高了模型的訓練效率,還增強了其生成視頻的質量和多樣性。
模型在訓練前,通過一系列嚴格的數據過濾技術,確保輸入數據的質量。這些技術包括 PySceneDetect 拆分單鏡頭視頻、OpenCV 拉普拉斯算子識別清晰幀等。這些步驟確保了模型能夠從高質量數據中學習,從而提升生成視頻的美學和技術標準。
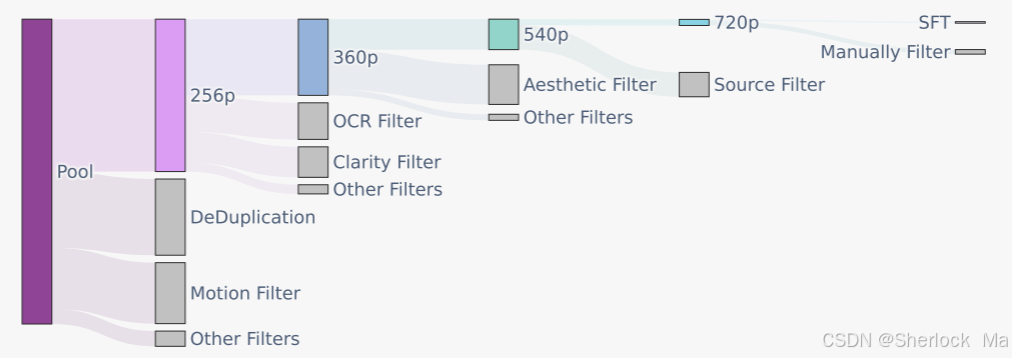
Hunyuan-Video 使用 3D-VAE 來壓縮視頻和圖像的像素空間到緊湊的潛在空間。通過這種方式,模型能夠同時處理視頻和圖像數據,提高了視頻重建質量和模型的推理效率。
Hunyuan-Video 的微調過程涉及選擇特定數據集進行精細化調整。通過自動化數據過濾技術和人工審查,確保微調數據的高質量,從而提升模型的性能和生成視頻的細節質量。
首先,用戶需要準備 Hunyuan-Video 的運行環境。可以選擇使用 conda 配置環境,也可以直接使用官方提供的 Docker 鏡像。
conda env create -f environment.yml
conda activate HunyuanVideo
python -m pip install -r requirements.txt
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.5.9.post1在開始微調之前,用戶需要下載并準備訓練數據集。Hunyuan-Video 提供了在 Hugging Face 上的權重,確保模型的正常運行。
微調過程包括調整模型的超參數,定義輸入輸出格式,并通過漸進訓練策略,逐步提高模型的生成質量。在這個階段,用戶可以根據具體需求調整模型的生成風格和細節。
問:為什么選擇 Hunyuan-Video 進行視頻生成?
問:如何確保生成視頻的質量?
問:Hunyuan-Video 支持哪些應用場景?
問:如何優化 Hunyuan-Video 的性能?
通過本文的詳細介紹,相信您對 Hunyuan Video 的微調方法有了深入的了解。在掌握這些核心技術后,您將能夠更有效地應用該模型,實現高質量的視頻生成。





