如何調用 Minimax 的 API
官方網站: https://aivideo.hunyuan.tencent.com/
Hunyuan-Video 生成的視頻內容多樣且細膩,涵蓋了從人物肖像到復雜場景的廣泛應用。以下是一些模型生成效果的例子:




Hunyuan-Video 的論文對比了全球領先的視頻生成模型,如 Gen-3 和 Luma 1.6,以及中國市場上表現最好的商業模型。結果顯示,Hunyuan-Video 在運動動力學等方面表現出色,達到了最高的整體滿意度。這一高性能的實現得益于其獨特的數據處理和模型訓練策略。
Hunyuan-Video 使用圖像-視頻聯合訓練策略,將視頻素材精心分為五個不同的組,而圖像則分為兩組,依據各自的訓練需求進行定制。這種分類確保了模型能夠在多個維度上進行高效學習。
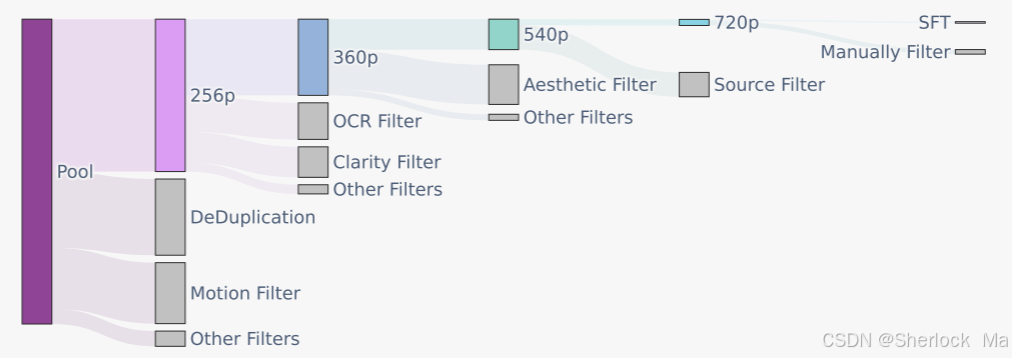
使用 PySceneDetect 將原始視頻拆分為單鏡頭視頻剪輯,通過 OpenCV 的拉普拉斯算子識別清晰的起始幀。利用內部 VideoCLIP 模型計算視頻剪輯的 Embedding,通過余弦距離進行重復數據刪除,并應用 k-means 算法獲取概念質心,用于排序和平衡。通過這些技術手段,模型能夠在美學、運動和概念范圍內不斷優化。
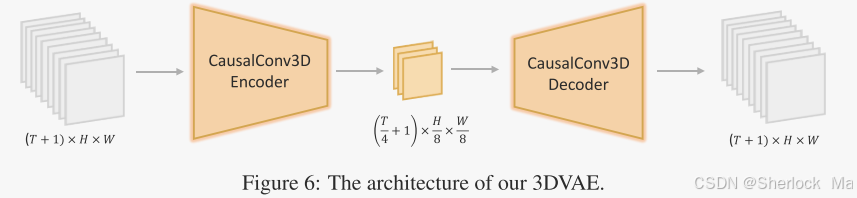
Hunyuan-Video 的 3D-VAE 通過 CausalConv3D 將視頻和圖像壓縮到緊湊的潛在空間中,顯著提高了視頻生成的效率和質量。在訓練過程中,使用從低分辨率短視頻逐漸變化到高分辨率長視頻的策略,確保了高運動視頻的重建質量。
Hunyuan-Video 采用了統一的全注意力機制 Transformer 設計,支持圖像和視頻的統一生成。文本編碼器通過在潛在空間中提供指導信息,增強了文本與視頻生成之間的聯系。使用大語言模型作為文本特征提取器,提升了文本信息的表達能力。
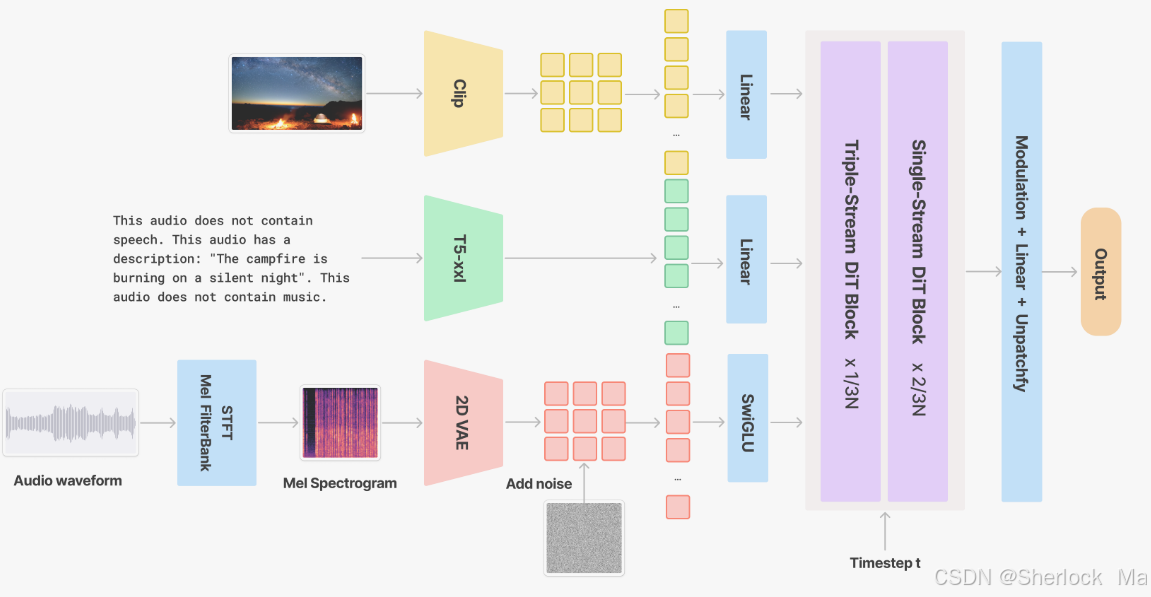
視頻到音頻模塊通過添加同步的聲音效果和背景音樂,提升了視頻內容的表現力。V2A 模型通過梅爾頻譜圖和 VAE 編碼器,在潛在空間中重建高保真的音頻信號。
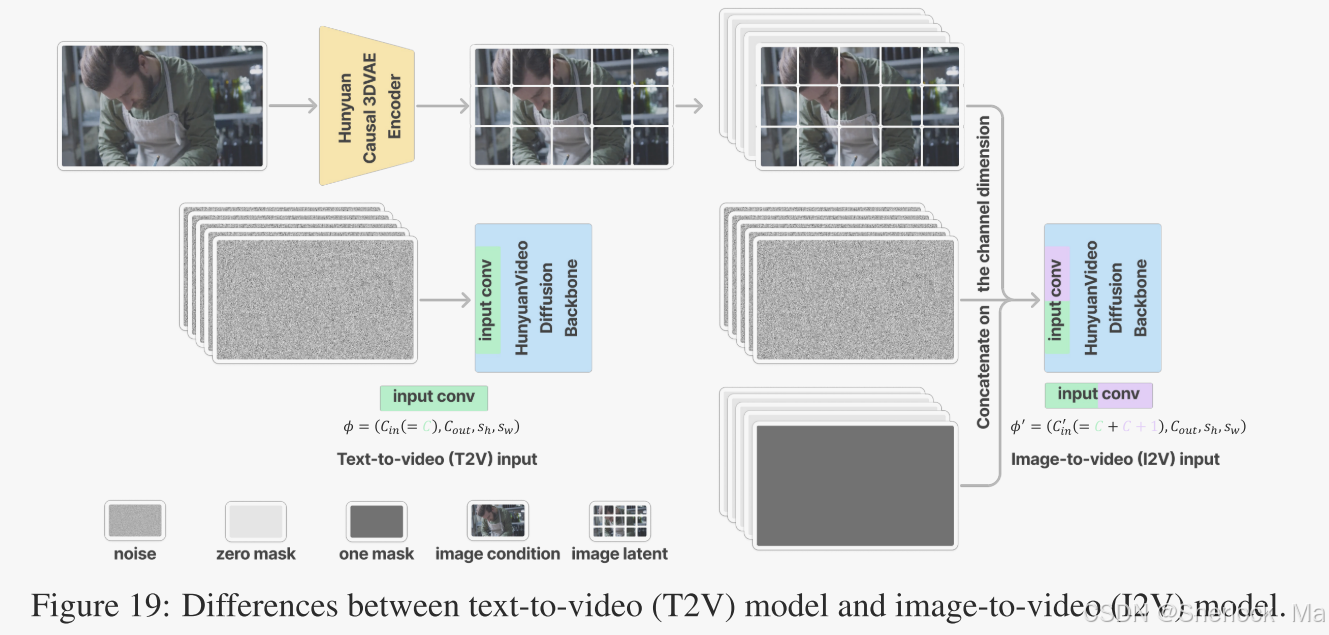
圖像到視頻(I2V)功能允許用戶通過輸入圖像和字幕,生成與之匹配的視頻內容。這一功能通過引入圖像作為視頻的第一幀并結合文本條件,確保生成的視頻與原始輸入的主題緊密貼合。
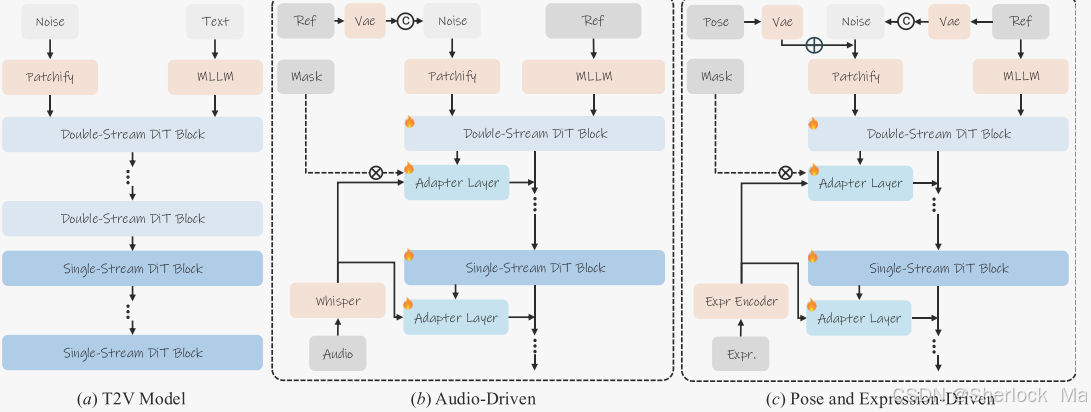
通過結合音頻信號、姿勢模板和表情模板,Hunyuan-Video 能夠實現豐富的化身動畫控制,提升角色的表現力和真實感。通過對參考圖像的編碼,以及使用多種適配器,模型能夠實現對復雜動畫的高精度控制。