
PixVerse V3 API Key 獲取:全面指南與實踐
PixArt-α的訓練策略分為三個階段:
這種分解策略使PixArt-α在訓練效率和圖像合成質量上都取得了顯著優勢。
PixArt-α采用了Diffusion Transformer(DiT)架構,創新性地引入了跨注意力模塊和自適應標準化層(adaLN-single)。跨注意力層的引入使得文本特征能夠靈活注入,而adaLN-single則減少了模型參數量。
class CrossAttentionLayer(nn.Module):
def __init__(self, dim, num_heads):
super(CrossAttentionLayer, self).__init__()
self.self_attention = nn.MultiheadAttention(dim, num_heads)
self.cross_attention = nn.MultiheadAttention(dim, num_heads)
self.layer_norm = nn.LayerNorm(dim)
def forward(self, x, text_features):
x = self.layer_norm(x)
x, _ = self.cross_attention(x, text_features, text_features)
return x為了提高文本圖像對的對齊效率,PixArt-α引入了一種自動標注流程,生成高信息密度的圖像標題。研究團隊對LAION和SAM數據集進行了詳細的名詞統計,確保模型在訓練中能夠掌握更多概念。
PixArt-α支持與ControlNet和DreamBooth結合使用。ControlNet通過生成HED邊緣圖像作為控制信號,增強了圖形生成的細節表現力。DreamBooth則通過少量圖像和文本提示,生成高保真度的圖像,展現出與環境的自然交互。

在User study、T2ICompBench和MSCOCO Zero-shot FID等指標下,PixArt-α展示了其卓越的圖像生成能力。在與Midjourney等其他模型的對比中,PixArt-α在質量和對齊度方面都表現優異。
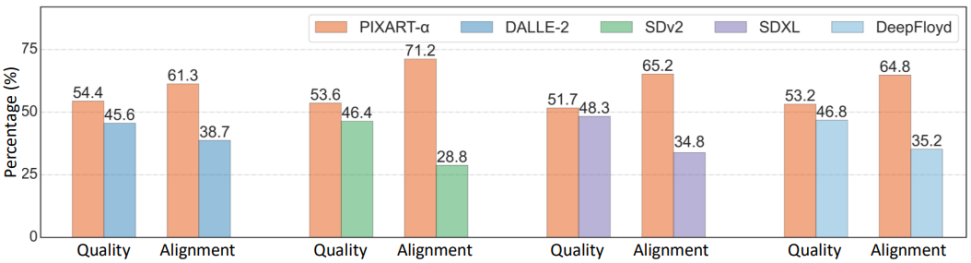
PixArt-α通過創新的訓練策略、架構設計和數據構建,實現了低成本高質量的文本到圖像生成。未來,研究團隊希望PixArt-α能夠為AIGC社區帶來更多創新,推動高效T2I模型的發展。
問:PixArt-α的主要優勢是什么?
問:PixArt-α如何實現高質量的圖像生成?
問:PixArt-α支持哪些應用場景?
問:如何開始使用PixArt-α?
問:PixArt-α與其他T2I模型相比有哪些不同?






