
LLM的預(yù)訓(xùn)練任務(wù)有哪些
首先,用戶需要從GPT4All官方網(wǎng)站下載適用于自己操作系統(tǒng)的安裝包。GPT4All支持Windows、MacOS和Linux系統(tǒng)。下載安裝包后,建議將其安裝在指定的目錄,以便于日后的管理和維護。
安裝完成后,用戶需要在GPT4All的安裝目錄下創(chuàng)建一個名為models的文件夾,用于存放下載的模型文件。這個步驟是為了確保模型文件能夠被軟件正確識別和調(diào)用。
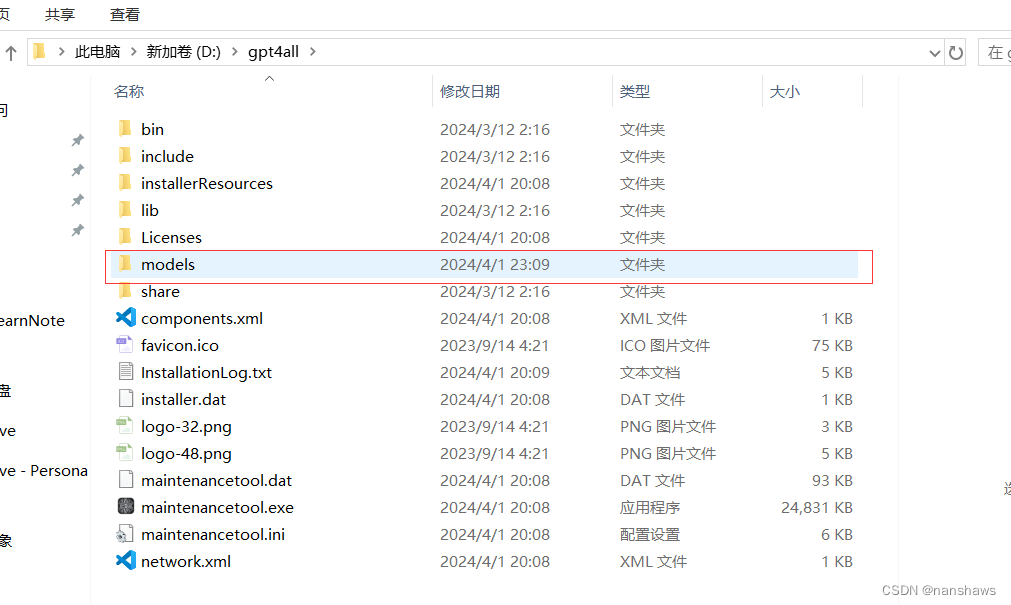
GPT4All提供了多種模型供用戶選擇,首推的是6.86G的大模型,運行內(nèi)存要求16G。在下載模型時,用戶可以直接通過GPT4All的軟件界面下載,或選擇瀏覽器下載后手動移動至models目錄。推薦選擇Hermes模型,因為它在使用上沒有限制。
一旦模型文件下載完成,用戶需要確保模型文件格式為gguf格式,這種格式是目前GPT4All所支持的唯一格式類型。將下載的模型文件移動到models目錄后,用戶即可在GPT4All界面中選擇并啟動該模型。
啟動GPT4All軟件后,用戶可以直接在軟件中選擇已導(dǎo)入的模型并開始進行交互測試。這一過程非常直觀,用戶可以通過輸入自然語言問題并獲得GPT模型生成的答案來進行模型的基礎(chǔ)測試。
在使用過程中,用戶可能會遇到一些常見問題,如模型文件未能識別、軟件啟動失敗等。大部分問題可以通過檢查模型文件格式和路徑設(shè)置來解決。
除了在客戶端使用,GPT4All也提供Python庫供開發(fā)者進行深度定制。首先,用戶需要安裝gpt4all Python包:
pip install gpt4all同客戶端使用相似,用戶需下載語言模型并設(shè)置模型目錄路徑。確保模型文件存放在C:/Users/Administrator/AppData/Local/nomic.ai/GPT4All/目錄下。
以下為一個簡單的Python代碼示例,展示如何使用GPT4All生成數(shù)據(jù)科學(xué)家的詩歌:
from gpt4all import GPT4All
model = GPT4All(
model_name='gpt4all-falcon-q4_0.gguf',
model_path='C:/Users/Administrator/AppData/Local/nomic.ai/GPT4All/',
device='nvidia',
allow_download=False
)
with model.chat_session():
response1 = model.generate(prompt='write me a short poem of data scientist', temp=0, max_token=200)
print(response1)代碼中,model_name為下載的模型文件名,model_path為存放模型的目錄,device指定為’cpu’或特定顯卡類型,max_token用于設(shè)置輸出內(nèi)容的最大長度。
models目錄中。通過本文的詳細介紹,用戶可以輕松掌握如何在本地設(shè)置和使用GPT4All模型,無論是在客戶端還是通過Python代碼調(diào)用。希望這篇文章能幫助你更好地理解和使用GPT4All這一強大的工具。







