
DeepSeek Janus-Pro 應用代碼與圖片鏈接實踐
eDiff-I 是一種基于文本到圖像擴散模型的生成方法,利用專家去噪器集合來提高生成效率。它不僅能夠生成高分辨率的圖像,還能處理復雜的文本提示,展示出強大的零樣本泛化能力。eDiff-I 的模型通過一系列嵌入(如 T5 文本、CLIP 文本和 CLIP 圖像嵌入)來實現條件合成,從而賦予模型多樣化的圖像生成行為。這一功能讓用戶可以實現風格遷移,甚至可以通過簡單的文本涂鴉來控制生成圖像的布局。

eDiff-I 的核心在于其專家去噪器的設計。通過將生成過程分為多個階段,每個階段使用專門的去噪器來處理不同的噪聲級別,從而提高生成質量。這樣的設計確保了模型在不同階段能夠靈活地處理文本和視覺信息。另一方面,eDiff-I 還集成了多種預訓練的文本編碼器,提升了模型在生成圖像細節上的表現。
在調用 eDiff-I 的 API 之前,用戶需要獲取訪問權限。這通常涉及申請 API Key,之后可以通過該 Key 進行授權調用。要申請 API Key,用戶需要注冊并登錄到 eDiff-I 的官方網站,填寫相關信息后即可獲得。
eDiff-I 支持多種輸入條件,包括 T5 文本嵌入、CLIP 文本嵌入和圖像嵌入。這些嵌入在不同的生成階段發揮不同的作用。通過組合這些輸入條件,eDiff-I 能夠生成更符合用戶預期的圖像。
T5 文本嵌入主要用于捕捉輸入文本的細節信息,在生成的早期階段提供對文本的更好理解,從而引導生成過程。
CLIP 文本嵌入有助于確定生成圖像的全局外觀,而 CLIP 圖像嵌入則用于風格遷移,通過參考圖像的風格影響生成結果。
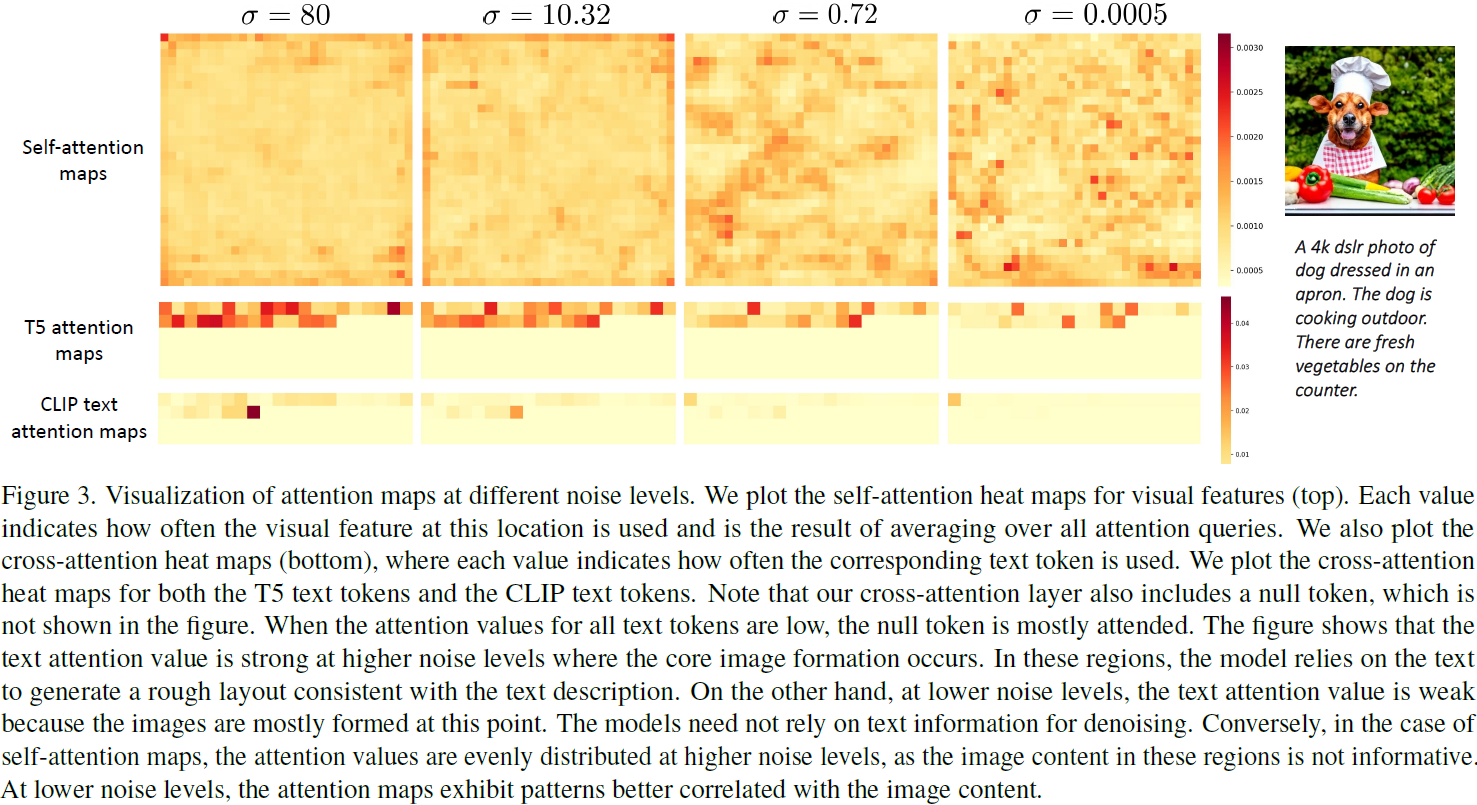
eDiff-I 的“用文字作畫”功能允許用戶通過簡單的文字和涂鴉來控制生成圖像的布局。用戶可以在畫布上選擇文本短語并進行涂鴉,生成的圖像將遵循這些輸入的空間布局。
用戶在畫布上繪制的短語和涂鴉會被轉換為二進制掩模,這些掩模與交叉注意力矩陣結合,用于調整生成過程中各圖像區域對文本的關注程度。
通過一系列實驗,eDiff-I 證明了其在生成圖像質量上的優勢。與其他模型相比,eDiff-I 在 FID 和 CLIP 分數上表現更佳,尤其是在復雜場景和長文本描述的生成任務中。
在不同的數據集上,eDiff-I 使用 CLIP 和 T5 文本嵌入的表現也有所不同。T5 嵌入在描述性文本中表現優于 CLIP 嵌入,而聯合使用這兩種嵌入可以獲得更好的結果。
eDiff-I 通過其創新的專家去噪器設計和多條件輸入支持,實現了高性能的文本到圖像生成。未來,eDiff-I 的應用前景廣闊,不僅能為數字藝術創作提供便利,還能在更多領域發揮作用。
問:如何獲得 eDiff-I 的 API 訪問權限?
問:eDiff-I 如何實現風格遷移?
問:eDiff-I 的“用文字作畫”功能如何工作?
問:eDiff-I 能否處理長文本描述?
問:如何確保生成圖像與文本提示一致?






