
LLM的預訓練任務有哪些
MinPts的選擇通常基于Eps的選取,建議選擇k值加1。具體來說,如果你選擇的k值為2倍的特征數減1,那么MinPts應該為k加1。這確保了每個核心點的鄰域內有足夠的點數來形成一個有效的簇。
Eps和MinPts的組合決定了DBSCAN的聚類結果。過大的Eps會導致簇數量減少,過小的MinPts會導致噪聲點增加。因此,選擇合適的參數需要根據數據分布進行多次試驗和調整。
在Python中,可以使用scikit-learn庫來實現DBSCAN聚類。首先,需要導入必要的庫,并設置隨機種子以確保結果的可重復性。
import numpy as np
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
np.random.seed(2021)為了展示DBSCAN的效果,我們生成moon數據并進行繪圖。這些數據有助于展示DBSCAN在處理非凸形狀數據集時的優勢。
data = np.ones([1005,2])
data[:1000] = make_moons(n_samples=1000, noise=0.05, random_state=2022)[0]
data[1000:] = [[-1,-0.5], [-0.5,-1], [-1,1.5], [2.5,-0.5], [2,1.5]]
plt.scatter(data[:,0],data[:,1],color="c")
plt.show()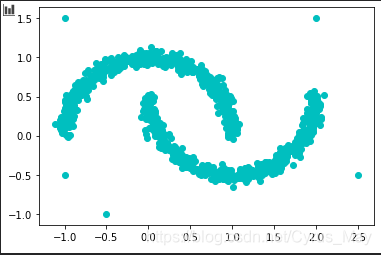
使用DBSCAN類來創建聚類模型并進行訓練。通過選擇合適的Eps和MinPts參數,可以有效地識別數據中的簇。
k = 3 # 2*維度-1
k_dist = select_MinPts(data, k)
k_dist.sort()
plt.plot(np.arange(k_dist.shape[0]), k_dist[::-1])
# 由拐點確定鄰域半徑
eps = k_dist[::-1][15]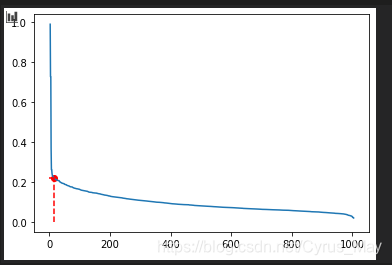
DBSCAN不僅可以用于簇的識別,還非常適合用于檢測數據中的離群值。通過分析聚類結果,可以識別數據集中不屬于任何簇的點,這些點通常被視為噪聲或離群值。
在DBSCAN聚類后,通過可視化將核心點、邊界點和噪聲點進行區分,可以清晰地看到數據的分類情況以及離群值的分布。
class_1 = []
class_2 = []
noise = []
for index, value in enumerate(label):
if value == 0:
class_1.append(index)
elif value == 1:
class_2.append(index)
elif value == -1:
noise.append(index)
plt.scatter(data[class_1, 0], data[class_1, 1], color="g", label="class 1")
plt.scatter(data[class_2, 0], data[class_2, 1], color="b", label="class 2")
plt.scatter(data[noise, 0], data[noise, 1], color="r", label="noise")
plt.legend()
plt.show()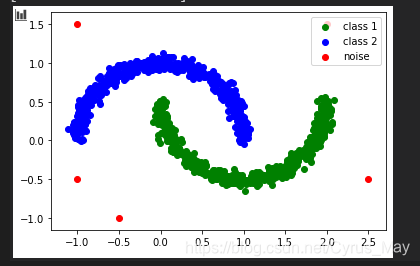
通過DBSCAN聚類實例,可以觀察到算法在處理不同數據分布時的優劣。尤其是當數據集存在大量噪聲時,DBSCAN能夠有效地識別出這些異常,并提供合理的聚類結果。
在scikit-learn中,DBSCAN類用于實現密度聚類。該類通過定義Eps和min_samples等參數,幫助用戶識別數據中的自然簇結構。這種方法特別適合處理具有不同密度和非凸形狀的數據集。
DBSCAN類的關鍵參數包括:
調節Eps和min_samples的值是DBSCAN性能優化的關鍵。通常,需要通過多次實驗來找到合適的參數組合,以便獲得最佳的聚類效果。
通過生成一組具有不同形狀的數據集,可以測試DBSCAN在處理非凸形狀和噪聲數據時的能力。下圖展示了數據的初始分布。
from sklearn import datasets
X1, y1 = datasets.make_circles(n_samples=5000, factor=.6, noise=.05)
X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2, centers=1.2, 1.2, cluster_std=.1, random_state=9)
X = np.concatenate((X1, X2))
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()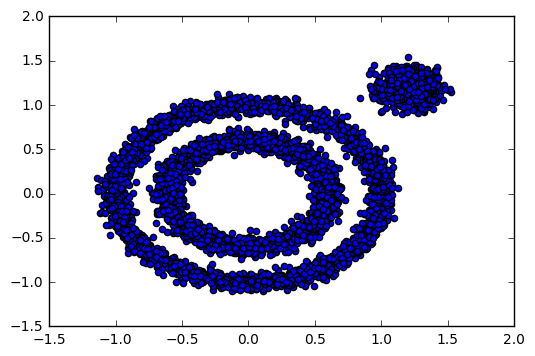
使用默認參數的DBSCAN可能無法直接得到滿意的聚類結果。因此,需要通過調整Eps和min_samples來優化聚類效果。
from sklearn.cluster import DBSCAN
y_pred = DBSCAN(eps=0.1, min_samples=10).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()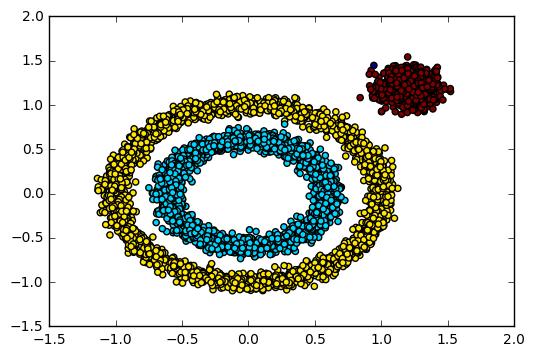
通過調參,DBSCAN可以更準確地識別數據中的簇結構和噪聲點。這個過程表明了參數選擇對聚類結果的重要性。







