
Node.js 后端開發指南:搭建、優化與部署
大型語言模型大多是在自然語言文本和代碼上進行預訓練的,這些數據與表格數據有著本質的不同。表格數據的二維特性使其在理解和回答相關問題時,需要模型具備垂直閱讀的能力。然而,目前的LLM在處理表格數據時,往往更擅長水平推理而不是垂直推理。

在缺失值識別任務中,模型需要識別并準確地指出表格中缺失值所在的行和列。從示例中可以看出,盡管模型能夠識別出行,但在列的識別上卻存在錯誤。

在列過濾任務中,模型需要根據給定的值找到對應的列。從示例中可以看出,模型的回答并不準確,這表明模型在處理表格數據時存在一定的局限性。

在更復雜的表格問答任務中,模型需要根據表格數據回答問題。從示例中可以看出,模型在回答有關二年級學生美術成績的問題時,給出了錯誤的結果。
表調優(Table-Tuning)是一種新方法,它受到指令調優的啟發,并在大型語言模型中被證明是成功的。通過在表指令數據集上微調模型,可以創建出在表格任務上表現更好的模型版本。
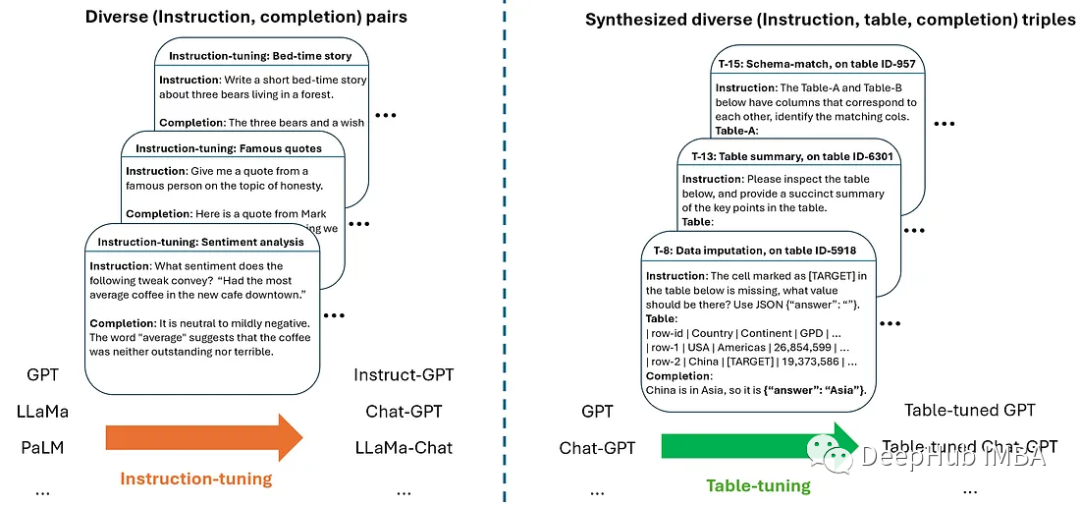
用于表調優的數據集是通過合成增強的方法創建的。這種方法從大量真實的表格開始,通過自動生成帶有指令、表格和響應的三元組樣本,從而創建出一個多樣化的標記數據集。
在合成步驟中,從一組支持的任務中采樣一個真實的表格和一個任務,創建新的樣本。生成的示例中的表不一定與輸入表相同,這為模型提供了更多的訓練樣本。
在合成步驟之后,為了創建更多樣化的數據集,論文使用了三種類型的增強:指令級增強、表級增強和標簽級/響應級增強。這些增強方法有助于提高模型的泛化能力,并確保數據的多樣性。
TableLLM是一款具備130億參數的大型語言模型,專為處理表格數據任務而生。它采用了一種創新的遠程監督訓練法,結合推理擴展策略,讓模型能更好地把握推理模式,并通過交叉驗證確保數據生成的質量。
TableLLM的整體架構包括構建遠程監督學習訓練數據和模型訓練兩個部分。模型訓練針對文檔嵌入的和電子表格嵌入的表格數據使用不同的提示,以適應不同的應用場景。
TableLLM在電子表格嵌入場景中普遍超越其他方法,在文檔嵌入場景中與GPT-3.5持平。這表明TableLLM在處理表格數據方面具有顯著優勢,尤其是在電子表格數據的應用場景中。
答:Table-GPT模型通過表調優(Table-Tuning)的方法,在表指令數據集上微調模型,使模型能夠更好地理解輸入中的表格數據,并提高對表格相關問題的響應準確性。
答:表調優的數據集是通過合成增強的方法創建的。首先從大量真實的表格開始,通過自動生成帶有指令、表格和響應的三元組樣本,從而創建出一個多樣化的標記數據集。
答:TableLLM模型的主要優勢在于其專門針對表格數據任務設計,能夠適應各種實際辦公需求。它采用了遠程監督訓練法和推理擴展策略,通過交叉驗證確保數據生成的質量,從而在處理表格數據方面展現出顯著優勢。
答:TableLLM模型在電子表格嵌入場景中普遍超越其他方法,在文檔嵌入場景中與GPT-3.5持平。這表明TableLLM在處理電子表格和文檔中的表格數據方面具有強大的性能。
從數據整理到表格應用,選擇合適的GPT模型對于提高工作效率和準確性至關重要。Table-GPT模型和TableLLM模型的出現,為處理表格數據提供了新的解決方案。它們通過優化模型對表格數據的理解能力,使得從數據整理到表格應用變得更加高效和準確。隨著技術的不斷進步,我們可以期待未來會有更多創新的模型和方法出現,進一步推動表格數據處理的發展。







